边缘端口
1. 特点
- 接入设备后直接进入forwarding状态,避免等地30秒转发延迟
- 边缘端口变为forwarding状态的时候不产生TC报文
- 不转发TC报文
- 收到TC不删除本接口的MAC表
- P/A收敛时,不会进入阻塞状态
- 收到BPDU报文,变普通端口,执行STP计算
2. 不足
- 临时环路
(2个端口直接连起来,或者下游接入的交换机不支持生成树)
临时环路持续0-2秒,收到对方端口发出的BPDU后同时进入阻塞状态,进行生成树的选举,决出一个DP和一个BP,DP在30秒之后进入转发状态,BP维持阻塞状态。 - 当边缘端口收到BPDU后,会丧失边缘端口的特性,变成普通端口并进行生成树计算,引起网络震荡。
3. 配合技术
BPDU保护
正常情况下,边缘端口接用户终端,不会收到BPDU报文。假如有人恶意攻击,伪造BPDU报文,那么边缘端口收到BPDU报文之后变为普通端口,引起生成树计算,导致网络震荡。
此时需要在边缘端口上配置BPDU保护功能,如果边缘端口再收到BPDU报文,此时边缘端口并不会变为普通端口,而是error-down,然后通知网管系统,如果想要恢复转发状态,可以手动shutdown/undo shutdown,或者配置自动恢复error-down auto-recovery cause bpdu-protection interval 时长
4. 使用场景
- 大型公司内网有很多电脑,上下班时产生大量的TC,造成所有交换机的MAC地址表频繁删除,以至于持续泛洪所有的数据帧,启用边缘端口可以改善网络品质
- 接DHCP客户端的端口,否则DHCP获取地址比较慢
- 接重要服务器和IP电话接口,否则在生成树拓扑发生变化时,将被阻塞掉,30秒后才能再次提供服务
Ping丢包该如何排查?网络中出现丢包,应该如何进行故障排查?
1. Ping丢包故障定位思路故障分析
- Ping丢包是指Ping报文在网络中传输,由于各种原因(如线路过长、网络拥塞等)而产生部分Ping报文丢弃的现象。在使用Ping命令,出现Ping丢包的现象时,第一步需要确定Ping丢包的网络位置,其次是确定Ping丢包的故障原因和设备,然后依据定位的故障原因再进行解决。
- 确认Ping丢包的网络位置时一般采用逐段Ping的方法,可以将Ping丢包故障最终确定在直连网段之间
- 确认Ping丢包的故障原因一般采用流量统计的方法,通过流量统计可以知道丢弃报文的具体位置、判断故障原因。
- 导致Ping丢包的原因非常多,也非常复杂,比如物理环境故障、网络环路、ARP问题、ICMP问题等,当然,并不是Ping丢包就一定表示网络质量差,某些情况下虽然Ping丢包,但是业务是正常的。
- 分析Ping丢包时注意以下两点:
- 当设备对报文进行硬件转发,速度非常快,就不会丢包,例如Ping设备端口下挂的电脑。当报文需要CPU进行处理时,CPU繁忙就会丢包,例如Ping设备上的IP地址。
- 为了防止网络攻击对设备造成影响,设备具有CPU保护功能,对于超过CPCAR值的ARP、ICMP等报文进行丢弃,造成Ping丢包现象,此种现象不影响业务的正常运行。
2. Ping丢包故障重现
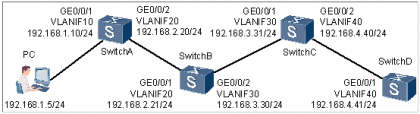
在PC上执行ping -n 100 192.168.4.41,发现有20%的报文丢失
3. Ping丢包故障定位
- 缩小故障范围
当在PC上直接Ping IP地址192.168.4.41丢包时,直接判定故障出现的原因将非常的困难。此时可以先缩小故障范围,在PC上分别Ping SwitchA、SwitchB、SwitchC和SwitchD,通过Ping结果可以判断出哪一段网络出现故障。假设PC上Ping SwitchB时也出现丢包,则可以初步判断丢包发生在SwitchA和SwitchB直连网段之间 - 配置Ping多包
为了持续复现丢包现象,以便于故障处理,需要持续发送Ping报文。交换机可以配置Ping的-c count参数,发送多个Ping报文。 - 配置流量统计
通过缩小故障范围最终将故障定位在SwitchA和SwitchB之间,为了进一步确认故障点,需要在SwitchA和SwitchB上配置流量统计功能,观察丢包情况,配置方法如下:- 先通过高级acl配置流规则
acl 3000 ; rule 5 permit icmp source 192.168.1.5 0 destination 192.168.2.21 0 - 然后根据acl配置流策略,主要是配置
- traffic classifier命中流
if-match acl 3000 - traffic behavior流行为
statiatic enable - 使用traffic policy将流和行为绑定
claffifier huawei behavior huawei - 在接口下使能策略
- traffic classifier命中流
- 查看流量统计命令为
display traffic policy statistics interface {接口} inbound或者outbound verbose rule-based class huawei - 清空流量统计命令为
reset traffic policy statistics interface {接口} inbound或者outbound
- 先通过高级acl配置流规则
- 分析统计结果
在SwitchA上持续Ping SwitchB- 如果离开SwitchA的报文数目
<Ping发送的报文数目,说明SwitchA上丢包,引起SwitchA丢包可能原因分为网络环路和ARP问题。登陆设备SwitchA- 查看CPU和接口利用率的情况,查看是否出现MAC地址漂移
- 查看是否有ARP报文被丢弃
- 如果离开SwitchA的报文数目
>进入SwitchB的报文数目,说明传输链路上存在丢包,后面介绍的物理链路故障引起ping丢包如何处理 - 如果离开SwitchA的报文数目
=进入SwitchB的报文数目,但是离开SwitchB的报文数目<进入SwitchB报文数目,说明SwitchB上存在丢包,引起SwitchB设备丢包可能原因分为网络环路和ICMP问题。登录设备SwitchB:- 查看CPU和接口利用率是否很高、查看是否出现MAC地址漂移
- 查看是否有ICMP报文被丢弃、查看ICMP报文限速的配置是否过小
- 如果离开SwitchA的报文数目
4. 故障解决
1. 物理链路故障引起ping丢包分析
- 物理链路故障常见以下原因:
- 计算机网卡有问题
- 线缆接头接触不良或松脱
- 网线出现问题,可以使用精明鼠查看是否有网线中断线情况
- 光纤弯曲度过大或者损坏导致光纤功率过低,PC和服务器上的可以使用光功率计测量,交换机上可以使用命令
display transceiver interface gigabitethernet 0/0/1 verbose查看,一般光功率大于-15db为正常可用的,小于-40db无法使用,当然光功率也不是越大越好,过大容易导致光模块损坏。如果是对光信号进行放大,被放大的信号如果信噪比比较低的情况,被放大之后的信号的失步更加严重。 - 如果是光纤问题,比较容易损坏的是lc头lc小方头(直接连接光模块)、fc大圆头、sc大方头、st小圆头,如果是远距离传输,可以使用otdr光时域反射仪定位大概的光纤故障地理位置
- 除了网络设备直接相关的物理因素,还有以下因素:
- 在实际环境中设备未接地导致静电不能释放
- 风扇损坏导致设备过热等物理环境问题也会引起Ping丢包
- 物理链路故障可以通过观察发现,如光纤弯曲度过大、物理连接线过长、设备或者电脑网卡指示灯显示不正常等
- 针对物理链路故障,故障的解决的办法一般是更换物理器件,器件更换后故障即可恢复。
2. 网络环路故障引起ping丢包分析
以太网交换网络中为了进行链路备份,提高网络可靠性,通常会使用冗余链路,但是使用冗余链路会在交换网络上产生环路,引发广播风暴以及MAC地址表不稳定等故障现象,从而导致用户通信质量较差,甚至通信中断。
网络环路会导致设备CPU和端口利用率高,Ping报文被丢弃。
当设备处于存在环路的网络中,设备的反应速度比较缓慢,环路问题判断方法如下:
- 通过
display interface brief | include up命令,查看所有UP接口下的流量,存在环路的接口上InUti和OutUti两个计数会逐步增加,甚至到接近100%,远远超过业务流量 - 检查CPU的利用率
通过命令display cpu-usage查看CPU的利用率
网络环路会导致CPU利用率一直很高,Ping报文未来得及处理就被丢弃。 - 判断交换机是否存在MAC地址漂移
- 可以执行
display trapbuffer命令,查看MAC地址漂移的日志来判断 - 可以多次执行
display mac-address来观察,若MAC地址在交换机不同的接口学习到,则存在mac地址漂移 - 可以执行
mac-address flapping detection命令配置MAC地址漂移检测功能,然后通过display mac-address flapping record命令来判断是否出现MAC地址漂移
- 可以执行
解决此种Ping丢包问题的方法是破除网络环路,可以在设备上部署STP/RSTP/MSTP~或者Smart Link~等协议,对环路进行处理
3. ARP问题故障引起ping丢包分析
常见ARP攻击:
- ARP泛洪攻击(拒绝服务攻击Dos),攻击者发送大量的ARP报文,侵占设备ARP表项资源,导致系统资源耗尽。可以通过配置ARP表项限制、ARP Miss消息限速、ARP表项严格学习、ARP报文限速来
- ARP欺骗攻击(中间人攻击),攻击者通过发送伪造的ARP报文,恶意修改设备或网络内其他用户主机的ARP表项。可以通过配置ARP表项固化、ARP表项严格学习、发送免费ARP报文、DAI来防止ARP欺骗攻击。
ARP问题常见故障现象:
- 刚开始由于ARP学习失败出现Ping丢包
- 然后学习到ARP后一段时间内(ARP表项老化时间,默认20分钟)无丢包现象
- 之后再出现ARP学习失败会继续出现丢包
常见ARP问题有以下两种:
- 设备配置了ARP安全功能,如ARP Miss的源抑制、ARP速率抑制等,会导致ARP学习很慢,Ping丢包
- 设备受到ARP报文攻击,上送CPU的ARP报文数超过CPCAR值,导致部分ARP报文被丢弃,Ping丢包
常见问题判断及解决方法如下:
- 通过
display arp packet statistics命令,查看是否有ARP报文被丢弃,分析设备上ARP安全的配置情况,从而判断问题的原因。对于该问题需要重新配置ARP安全,使设备能够正常的处理ARP报文。 - 通过
display cpu-defend statistics命令,查看CPU对于ARP报文处理情况,是否存在报文丢弃。对于该问题需要检查设备是否受到ARP攻击,正确配置ARP安全来防范攻击,同时增加ARP报文的CPCAR值。配置样例如下:
cpu-defend policy arp
car packet-type arp-reply cir 32
car packet-type arp-request cir 32
quit
cpu-defend-policy arp global
4. ICMP问题故障引起ping丢包分析
常见ICMP攻击:
- ICMP泛洪攻击,发送速度极快的ping报文,导致被攻击者疲于应付,CPU使用率过高。可以设置CPCAR值,保证设备CPU不被攻击
- 发送长度超过65535B的报文,导致被攻击者组报之后内存溢出。可以设置ping的报文长度,超过长度的报文直接丢弃
- 发送的报文长度没有超过65535B,但是会分片,导致被攻击者频繁的组报,CPU使用率过高。可以设置丢弃ICMP分片的报文
- 发送icmp不可达报文,干扰被攻击者的路由信息,影响正常报文的转发。可以开启ICMP不可达报文攻击防范功能,收到ICMP不可达报文将直接忽略
- 跨越网段向被攻击者发送虚假的重定向报文,以改变目标主机的路由表,影响正常报文的转发。可以启动ICMP重定向攻击防范后,设备将对ICMP重定向报文进行丢弃
ICMP问题常见故障现象:
- Ping设备时,一旦Ping速度比较快就会丢包,速度慢下来就不会丢包
- Ping大包时出现规律性丢包
- Ping设备时,会出现Ping通几个报文后Ping不通,大约两分钟左右又可以Ping通,Ping通几个报文后又Ping不通
常见ICMP问题有以下三种:
- 设备配置ICMP限速功能,超过速度限制的ICMP报文被丢弃
- 设备配置ICMP攻击防范,超过速度限制的ICMP报文被丢弃
- 设备受到ICMP报文攻击,上送CPU的ICMP报文数超过CPCAR值,导致部分ICMP报文被丢弃
常见问题判断及解决方法如下:
- 检查
icmp rate-limit total threshold threshold-value命令的配置情况,了解ICMP流量限速的阈值。如果阈值过小,则可通过icmp rate-limit total threshold threshold-value命令进行修改,使其允许更多的ICMP报文通过。配置如下:
icmp rate-limit enable
icmp rate-limit total threshold 500
- 通过
display icmp statistics和display anti-attack statistics icmp-flood命令查看是否有ICMP报文被丢弃。对于该问题需要重新配置ICMP安全,使设备能够正常的处理ICMP报文 - 通过
display cpu-defend statistics packet-type icmp all命令,查看CPU对于ICMP报文处理情况,是否存在报文丢弃。对于该问题需要检查设备是否受到ICMP攻击,正确配置ICMP安全来防范攻击,同时增加ICMP报文的CPCAR值。ICMP报文的CPCAR值配置样例如下:
cpu-defend policy icmp
car packet-type icmp cir 256
quit
cpu-defend-policy icmp global
还可以通过icmp-reply fast命令使能Ping快回功能来解决CPU丢弃ICMP报文故障
6台路由器
给你6台路由器,2台高性能,2台中等性能,2台低性能,构思两种拓扑,你怎么规划?有什么区别?
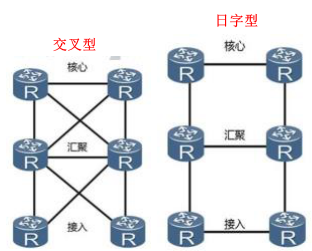
拓扑如何规划需要考虑到用户关心的核心问题:
1. 如果客户是企业
可能最关心的是成本开销问题
- 从设备角度考虑:
使用交叉型连接,会需要更多的端口、光纤单模光纤比多模光纤贵,但是传输距离远、光模块一个万兆光模块一千多、板卡更贵、,需要增加采购成本 - 从线路角度考虑:
若节点和节点之间距离较远,在不同的城市中,租用运营商长途专线互联,日字型一般情况下,可以满足互联互通的需求,也提供基本的冗余能力,但要追求更高的冗余性则可以使用交叉型。
运营商租用线路是按照每纤每公里每月来计费的,比如移动裸纤市场价是每纤每公里每月400元。
租用专线,比如在同一个城市不同的区,之前单位办理10M的专线一月是3500,后来租用的200M的,一年就是40万。
因此,租用线路成本有可能高于设备采购成本 - 对于运营商:
由于其拥有传输资源,成本不会过多造成压力,设计网络主要从冗余、性能等角度去考虑,一般在核心层和汇聚层之间多采用交叉型,汇聚层和接入层之间多采用日字形
2. 如果客户是政府
这类客户不差钱,可能最关心的是冗余、网络品质以及后期维护的问题
- 冗余:
物理层面分为设备冗余和链路冗余,日字型和交叉型都满足设备和链路冗余,都不存在单点故障,但是交叉型较日字型冗余性更高 - 网络品质角度:
日字型设计由于互联线路较少,所以在节点和节点之间(特别是斜对角)访问的时候,网络品质不是最优,且当中经过的线路和设备较多,任意一点出现问题都会导致网络品质下降,所以健壮度不高。特别是在上行链路中断的情况下,流量将走中间平行的互联链路,极易对旁路造成干扰。
交叉型设计由于互联线路多,任意节点之间互访都是最优路径,且在一条上行线路故障的情况下,整体网络品质几乎不受影响 - 后期维护:
普通的一个政府部门,比如一个处,很少招收专门的网络运维人员,基本都是兼职
对于IGP协议,交叉型在路由设计上比日字型邻居数量成倍增加,故障定位和排障难度增大
日字形比交叉型拓扑简单,邻居较少,流量走向清晰,在日常管理运维方面更有优势。如果出现故障,排障比较快;如果日后增加节点进行扩容,也更容易实现
3. 如果客户是保密要求比较高的单位
可能更关系的是流量和路由的控制问题
- 网络流量
分为主备方式和负载均衡方式,日字型比较适合设计为主备方式,流量走向比较清晰明了;交叉型比较适合设计为负载均衡方式,但设计不好容易出现来回路径不一致现象,保密单位一般部署加密机和防火墙,如果采用来回路径不一致URPF,单播反向路径转发的情况下,可能造成网络互访有问题 - 路由控制问题:
交叉型下游设备均是双上联,这种情况下对于路由的控制需要配置更多的规则,并且路由的走向的过多,不利于严格控制流量的走向
日字型只有一个上联线路,为了实现所有的流量都经过核心交换机,实现流量精确控制,只需要配置策略的策略阻断接入和汇聚两层的横线连接的链路即可
园区网打印机如何部署
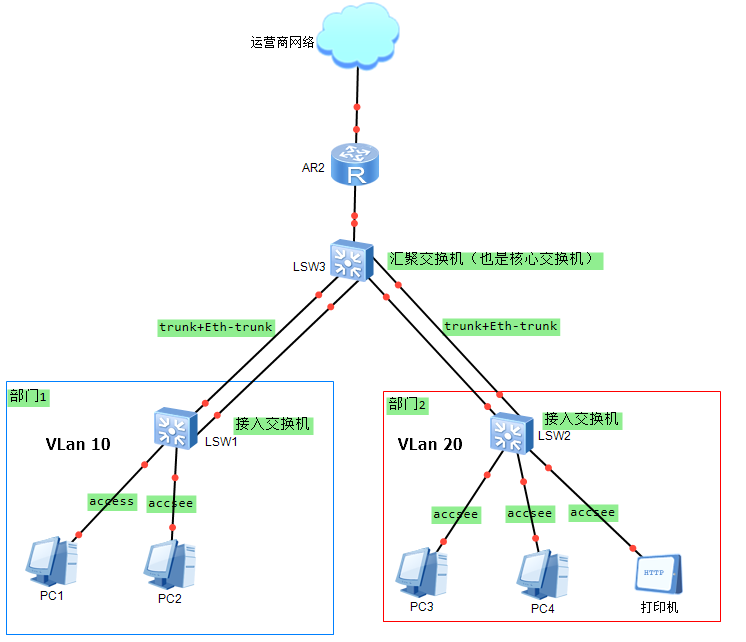
1. VLAN+Eth-Trunk
- 这是两个部门,需要划分vlan进行隔离
- SW1和SW2创建相应的vlan之后,将与终端相连的接口添加进入vlan,上行接口放行所有的vlan
- 在配置vlan时,与打印机和终端相连的下行端口配置成access,交换机与交换机之间配置成trunk
- 双上行链路,很明显需要配置成eth-trunk,然后配置成trunk口
# 下行端口配置
# SW1
vlan 10
port link-type access
port default vlan 10
port g0/0/1 to g0/0/10
# SW2
vlan 20
port link-type access
port default vlan 20
port g0/0/1 to g0/0/10
# 上行端口配置
int eth-trunk 1
trunkport g0/0/11 0/0/12
port link-type trunk
port trunk allow-pass vlan all # 或者10 20
为什么接口模式不使用hybrid?因为hybrid配置比较麻烦,不仅需要配置PVID,还需要配置untag-list等;其次hybrid一般用在接入像华为FusionComputer、VMware的EXSi或者开源的PVE这类虚拟化平台设备,因为这类设备中有虚拟交换机,可以划分vlan,此接口下可能接收到带有vlan的数据
2. 网关+RSTP
- 这属于办公网络,只有两个接入和一个汇聚,为了方便流量控制,同时减少在接入交换机上划分过多的vlan,建议将网关部署在汇聚交换机上,同时需要在汇聚交换机上配置所有的vlan
- 还需要在交换机上配置RSTP,通过修改优先级将汇聚交换机配置为根桥
- 为了防止上下班高峰期时频繁的开关机导致的拓扑频繁变化,此时可以将与终端相连的端口配置成边缘端口
- 正常情况下边缘端口与终端相连并不会收到BPDU报文,但是如果有人恶意攻击,仿造BPDU报文,导致边缘端口收到BPDU报文之后变成普通端口,重新进行生成树计算,导致网络震荡,这时候可以配置BPDU保护。开启BPDU保护之后,边缘端口收到BPDU报文之后并不会变为普通端口,而是error-down,此时需要进行手动恢复,即
shutdown/undo shutdown,当然也可以配置自动恢复error-down auto-recovery cause bpdu-protection interval 时长 - 因为接口交换机配置边缘端口较多,为了方便配置,一般采用在全局下开启边缘端口
stp edged-port default,此时需要注意的是,需要将与上游汇聚交换机相连的eth-trunk接口从边缘端口中解放出来,即在此接口下配置stp edged-port disable
# 配置vlan
vlan batch 10 20
int vlan 10
ip addr 10.1.1.254 255.255.255.0
int vlan 20
ip addr 20.1.1.254 255.255.255.0
# 当然也需要配置eth-trunk,配置方法与接入交换机相同
# 配置rstp
stp mode rstp
stp root primary
3. DHCP以及防护+802.1x
为了能够使终端自动获取到IP地址,需要在汇聚上配置DHCP服务器。
由于打印机要配置固定的IP,有两种方法可以实现:
- 在DHCP中使用Mac与IP地址绑定的方式实现
- 在打印机上配置静态IP之后,在DHCP地址池中将其exclude掉
全局地址池和接口地址池的区别:接口地址池只能使用接口地址作为网关,全局地址池可以单独配置网关
ip pool hcie
gateway-list 10.1.1.254
network 10.1.1.0 mask 255.255.255.0
exclude-ip-address 10.1.1.100 # 排除打印机静态配置的地址
static-bind ip-address 10.1.1.100 mac-address 0001-0002-0003
dns-list 114.114.114.114
quit
dhcp enable
int eth-trunk 1
dhcp select global
配置了DHCP之后,还需要配置响应的防护功能:
- 为了防止有人冒充DHCP服务器为终端分配地址(DHCP仿冒者攻击),需要配置信任端口,即将连接DHCP服务器的端口配置成信任端口,这样就保证客户端不会收到仿冒者发送的DHCP offer报文
- 为了防止中间人攻击,即ARP欺骗,攻击者发送一个ARP报文给接入交换机,将ARP报文中的sender IP改为客户端的IP,但是sender mac却是攻击者的mac,这就导致DHCP服务器上和客户端上的ARP表项中的mac地址不是对方的,而是攻击者的,造成DHCP服务器和客户端之间的数据全部转发给攻击者。为了防止这种攻击,可以开启一下功能:
- 部署DHCP snooping,配置信任端口,创建绑定表,绑定表中包含MAC地址、IP地址、租约时间、VlanID、接口信息,如果报文中跟绑定表中记录内容的不一致则会丢弃报文
- DAI,动态ARP检测,当设备收到ARP报文时,将此ARP报文对应的源IP、源MAC、VLAN以及接口信息和绑定表的信息进行比较,如果信息匹配,说明发送该ARP报文的用户是合法用户,否则丢弃报文。可以使用命令
dai enable开启DAI功能 - IPSG,IP源防攻击,防止IP盗用的行为,同样是利用绑定表来检查二层接口上收到的IP报文,只有与绑定表中信息一致才通过,否则丢弃。可以使用命令
ip source check user-bind enable开启IPSG共呢个
DAI和IPSG启用之前必须配置DHCP Snooping,因为这两个功能都依赖DHCP Snooping的绑定表
DAI和IPSG的区别:DAI是利用绑定表对ARP报文进行过滤,防止中间人攻击;IPSG是利用绑定表对IP报文进行过滤,防止IP地址欺骗攻击
option43选项是告诉AP,AC的IP地址,让AP寻找AC进行注册
option82实现dhcp客户端和dhcp中继设备的地址信息记录在dhcp服务器上,实现dhcp分配的限制和计费功能
为了防止有人随意上网,可以使用802.1x对接入的终端进行认证,通过授权来指定用户所能访问的资源。802.1x是一种基于端口的网络接入控制协议,因为是二层协议,所以对接入设备的性能要求不高,同时认证报文和数据报文通过逻辑接口分离,安全性比较高。
802.1x由三部分组成,客户端、接入设备和认证服务器(AAA),在此园区网中,客户端即PC、接入设备即接入层交换机、认证服务器即汇聚层交换机。客户端需要安装802.1x认证的终端,并且支持EAPoL(EAL over LANs,可扩展认证协议)
客户端分为两个逻辑接口,一个是用来传输认证数据的非受控端口,另一个是用来传输传输业务数据的受控端口,受控端口只有在授权状态下才会进行业务数据的传输。
认证触发方式主要分为客户端触发和认证服务器触发。
- 客户端可以发送EAPoL-start报文来进行认证触发,该报文的组播mac为01-80-C2-00-00-03,除此之外,还可以发送DHCP/ARP/DHCPv6/ND等报文触发认证;
- 而认证服务器端则是周期性的发送EAPoL-request/identity来触发认证,用来支持不能主动发送EAPoL-start报文的终端设备。
- 假如设备无法安装802.1x终端,可以使用MAC旁路认证,例如打印机、摄像头等设备,终端使用mac地址作为用户名和密码进行认证。
4. NAT+PPPoE
- 如果该公司想要访问运营商网络,可以采用NAT的方式
- NAT分为Basic NAT和NAPT。Basic NAT仅仅是IP地址的一对一的转换,不处理端口;而NAPT可以把多个内网地址映射到一个公网地址的不同端口上,实现多个私网用户共用一个公网IP访问互联网的目的
- 因为配置NAT是在路由器上配置,用户流量最终汇聚到汇聚交换机上,为了引导用户流量进入路由器,然后进入运营商网络,在这种场景下,最简单的方式是配置默认路由,一条是在汇聚交换机上配置的指向路由器的默认路由,另外一条是路由器上配置的指向运行商的默认路由
- 如果是单纯的是公司访问互联网,则可以配置Easy IP,原理跟NAPT相同,都是使用
IP地址+端口的方式进行映射;如果该公司还对外提供网络服务,例如HTTP,这时候需要配置NAT Server,在路由器上配置公网IP地址+端口号与私网IP地址+端口号之间的映射关系,从而实现公网用户能够访问内网提供给的http服务等
- 除了使用NAT上网,还可以采用PPPoE的上网方式
- 配置PPPoE的客户端,在路由器上,首先创建dialer接口,在该接口下配置链路封装协议为ppp、IP地址为ppp自动协商,同时指定dialer接口拨号所使用的账号和认证方式等
5. 打印机配置
- 如果打印机有网口,可以配置成网络打印机,将打印机直接接入交换机即可
- 如果打印机不支持DHCP,可以直接配置固定的IP之后,在DHCP服务器的地址池中将这个IP排除掉
- 如果打印机支持DHCP,可以在DHCP服务器的地址池中,通过打印机的MAC绑定一个固定的IP
- 如果打印机没有网口,只能配置成共享打印机的方式,使用一台主机(打印服务器)的usb连接打印机,当需要打印东西的时候,访问打印服务器即可,打印服务器IP的配置方式和网络打印机的方式相同
环形网和星形网的优缺点?具体应用场景?
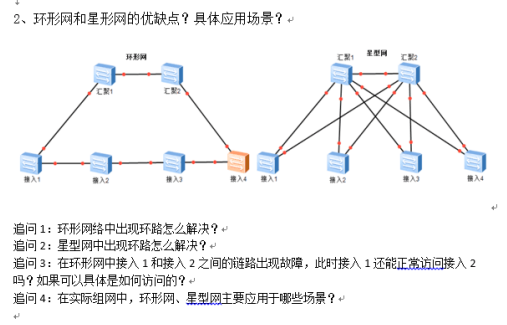
优缺点
- 冗余性和成本
- 任一节点到其他节点都有两条路径,双星型和环型都具有冗余性和可靠性。但是双星型比环型冗余度更高,两个接入层之间的互访,环型只有2条链路,星型有4条。
- 双星型冗余度更高,成本也会增加很多,比如在汇聚层,环型只需要2个接口,双星型却需要4个接口,成本会显著增加,比如万兆光模块一个千把块钱、40G的光模块更贵、40G的光纤也是按米计价。这仅仅只是设备成本,搭建网络租用运营商的线路成本可能要远远高于设备成本,目前移动光纤市场价是400元/纤/千米/月
- 负载分担和网络品质
- 双星型可以实现双链路负载分担,任意节点之间互访,仅经过汇聚节点,出现故障后,故障影响范围较小
- 环型路径节点数量不一致,很难实现负载分担,无论走哪条路径都进过很多节点,网络品质很难保证,当出现多个故障点时,会导致大面积业务中断
- 路由控制和破环
- 双星型,因为访问必经过2个汇聚,更好控制,流量路径相对环形网络有更多路径的可能,流量统一通过汇聚交换机转发,方便实现流量管理,方便安全设备部署实施以及无线设备的部署以及QOS相关优化,破环可以使用VRRP+MSTP、smart-link+monitor-link或者堆叠
- 环型,任意2个节点之间互访可能性很多,只能在各自节点做路径控制,接入设备之间直接走流量,汇聚设备性能无法充分利用,并增加接入设备的流量负担,不利于流量集中管理和部署网络安全相关的策略,网络管理难度大,破环可以使用MSTP破二层环路、ospf破三层环路
- 网关部署
- 双星型中网关部署在汇聚和接入均可,一般简单局域网中,汇聚性能高,网关部署在汇聚更合适,更加方便路由控制和流量管理,并且能充分发挥汇聚层设备高性能的优势,同时也能减少在接入层设备上划分过多的vlan
- 环型,因为各节点都存在用户终端,一般是物理距离特别远时选择环型网络,网关建议分布式部署,每个节点部署自己的网关即可,如果需要同一个网关,可以使用super VLAN,即vlan聚合;更高级一些的,可以部署Vxlan,即三层网关,采用分布式网关的部署方式,将汇聚层设备堆叠后做为spine节点,将接入层设备作为leaf节点,但需要注意的是,使用VXLAN技术也会带来一些新的问题,比如数据传输开销增加的问题,因为Vxlan采用Ethernet over UDP的方式,仅仅Vxlan报文的头部就50字节【=2层14B+IP头20B+UDP头8B+VXLAN头8B】,容易造成分片,建议使用Vxlan的时候修改MTU
- 扩展性和运维
- 环型扩容会影响当前的拓扑,需要将环型网络拆开,这种情况下会导致冗余性的暂时丢失,同时也会造成拓扑变化比较大,IGP协议需要重新针对环型网路做路由收敛,代价比较大,在割接过程中需要谨慎
- 双星型扩容,只是增加设备和相应链路,不破坏原有的拓扑,扩展性比较强,适合规模化、模块化部署,新加入的设备和原有的接入层设备的冗余能力相同,并且对于IGP协议来说,原有的拓扑并不会改变,只是新增一部分路由,在割接过程中,风险可控,操作难度大大降低
- 适用场景
- 环型,一般用于广域网组网或者传输网组网或者骨干网,并且设备性能差别不太大的情况下,因为所有机器要承载网络中的所有路由,比如有4太S5700EI、两台S5700HI
- 双星型,常用于中小型企业总部园区网络或大型分支网络或者数据中心网络中,性能较好的设备放在汇聚层,性能逊色一些的设备放在接入层,比如两台S9700HI,4台S5700EI
园区网
园区网的网关部署在接入层还是汇聚层?
- 放在汇聚层有优势
- 从成本角度去分析:对接入设备性能要求比较低,成本减少(接入交换机可以只要求2层,版本可以是简化版LI),看接入交换机的数量,数量越大成本优势越明显
- 从网关冗余的角度分析:可以在2台汇聚之间运行VRRP等技术实现网关冗余,如放接入需要采用堆叠等技术实现,扩展性差
- 从业务部署和管理角度分析:所有核心网关配置可以远程配置,现场工程师只需要把接口划入指定VLAN,测试电脑配置指定IP,PING通网关即可,现场不需要考虑路由协议问题
- 从业务局部迁移角度分析:因为不同接入交换机上的相同VLAN是互相通的,所以物理位置的迁移(比如机房的搬迁等情况下)不需要重新部署新的IP地址段
- 从IP资源角度分析:不同接入交换机上的VLAN使用相同的IP地址段,避免浪费,减少接入和汇聚之间的互联地址段,减少路由协议的邻居数目
- 放在接入层有优势
- 从隔离广播域的角度分析:可以分割广播域,当局域网出现类似ARP病毒之类的问题,受影响的范围可控
- 从故障定位的角度分析:哪个网段出现问题,直接能够根据拓扑图找到物理位置
- 从选路控制角度分析:接入和汇聚间跑路由协议,可以有多种方式操控流量走向(比如OSPF选路为O>OIA>OE1>OE2、策略路由等技术)
- 从规避环路角度分析:不需要运行生成树或者SMART-LINK等技术
- 从线路效率角度分析:路由协议可以实现负载分担(逐流或者逐包),而二层协议只能实现主备或者实现异组负载分担,同属于一台交换机的不同网段之间的业务互访,不需要经过汇聚交换机,所以提高了访问效率
- 从风险的角度分析:要实现同网段必须连同一台接入交换机,物理位置隔离,风险小,如部署在汇聚,则不同接入交换机上同VLAN可互通,风险大
- 从项目的角度分析
- 考虑成本因素,要确定接入交换机的型号,是否支持3层功能(纯2层接入成本有优势
网关放在汇聚层) - 要考虑同IP段的使用人员分布位置,集中式适合部署在接入,分布式适合部署在汇聚
- 要考虑流量模型,横向流量高适合部署在接入(同交换机转发快),纵向流量高适合部署在汇聚(减少路由查找次数)
- 考虑成本因素,要确定接入交换机的型号,是否支持3层功能(纯2层接入成本有优势
100台路由器
在一个自治系统中100台路由器,性能差异较大,选择哪种IGP协议?
IGP协议有三种,RIP、OSPF、ISIS,首先来分析RIP特点:
- RIP每30S更新所有路由表,链路开销大,特别是在广域网链路上
- RIP收敛慢,如主备切换需要180秒
- 16跳,对网络直径有限制,不适合大型网络。在设计网络时可以让100台的网络直径小于16跳,但是在后期维护以及控制路由选路会改动开销,开销由原来的1跳改为多跳,这样就会严重限制网络直径的大小
- 基于跳数选路,计算开销比较简单,无法根据带宽大小选择最优路径,而路由器在传输数据的时候,传递快慢都是与带宽挂钩的
- 扁平化网络结构,不能分为多个区域,即代表整个网络中每台路由器需要维护相同的路由条目,承受相同的数据装发流量,对于性能较差的设备可能承受不了
从RIP的特点可以看出其不适合在 100 台这种大型网络里面,接下来分析OSPF和ISIS协议。
OSPF和ISIS支持路由条目数较大,在1-3万条之间isis一个虚拟系统最多携带路由3万左右,最多可以配置50个虚拟系统;一个ospf路由表不要装载超过3万条路由,可以层次化设计,网络规模可以很大,使用哪种协议看具体组网需求和场合:
共同点:
- 都是链路状态路由协议,都要求区域内的路由器交换链路状态信息,链路状态信息被收集到链路状态数据库中
- 都是基于链路状态库中的信息,采用几乎相同的SPF算法来计算最佳路由
- 都在广播网络中选择指定路由器来控制扩散并降低这类介质中多对多邻接的系统资源需求
不同点:
- OSPF
- 支持的网络类型丰富,广播、NBMA、P2P、P2MP
- LAS种类多,路由控制精细,分为域内>域间>外部1类>外部2类
- OSPF区域类型丰富,骨干、普通、STUB、NSSA
- OSPF有区分内部和外部路由,根据需要可以配置不同的优先级
- 有虚链路提供备份、冗余、优选链路的功能
- 人员熟悉度,企业网络工程师熟悉OSPF、不熟悉ISIS,在设计网络和后期运维的时候更有优势
- ISIS
- 人员熟悉度:当前在运营商环境中使用较多
- 收敛速度快,路由变化都是PRC
- 扩展性强,采用TLV结构,支持IPV6
- 运行在数据链路层,抗攻击能力强
- 可以支持非IP网络
总结:
可以选用ISIS或OSPF
OSPF的选路更灵活,路由操控手段更丰富,更适合层次化划分,可以考虑将性能好的设备放在OSPF骨干区域,性能差的放到NSSA、STUB区域等,有更多的特殊区域可供选择,当前实际应用多在企业网中
ISIS收敛速度更快,扩展性强,网络稳定性更好,当前实际多应用于运营商网络中,多采用网络扁平化设计。ISIS虽然也可以支持划分多区域,但功能比较单一,并且只有level-1区域,可能会造成路径选择不优,如果想要优选又必须得做level-2到level-1的路由泄漏,存在隐患。但在极端情况下,ISIS能承载的路由条目比OSPF更多
追问
1. 通过哪些方面考虑应用那种IGP协议?
如果客户是运营商核心,特别是MPLS VPN的核心,一般低层用ISIS,企业网多数使用OSPF。
ISIS一般用在网络结构比较平坦的ISP核心网络,配置简单效率高。OSPF的相关特性比较多,比较适合逻辑上层次结构比较复杂的网络,并且OSPF是基于IP的,大多数人能够比较方便的理解其原理,便于实施和运维,企业用OSPF比较好。
2. 什么情况下一定要使用ISIS?
一般现网情况下,ISP网络逻辑结构比较平坦的核心部分会使用ISIS。理论上说,必须使用ISIS而不能使用OSPF的情况,只有网络不是用IP,比如IPX、appletalk。OSPFv2设计的时候只支持IPv4,而ISIS从理论上来说都可以,只要使用新的TLV来携带路由信息即可。
大型割接
总体分为四个阶段:前期调研阶段、割接前准备阶段、割接实施阶段、割接后保障阶段
割接流程
1. 前期调研阶段
- 需了解用户的背景和需求、业务类型和特点、变更的目的
- 调研现网的网络情况、拓扑情况、流量走向、路由规划等,了解变更后目的网络情况、拓扑情况,流量走向、路由规划等
- 变更过程中人员职责安排及联系方式
- 变更计划制定,需精确到每一步操作的时间点和操作完成时间点
- 变更前测试方案和变更后测试方案,变更前对重点业务和应用进行测试,变更后进行第二次测试,通过两次测试结果来判断割接后现网业务是否得到恢复
- 回退方案制定,当在规定时间点无法按照割接计划完成相应内容或者割接完成后业务无法恢复,则认为割接失败,进行回退。回退过程中按照回退方案操作,移除新增或改变的线缆,恢复原设备配置和连线,恢复后还需对业务进行再次测试,已判断回退成功
- 割接失败后信息采集,按照职责划分,采集各自负责设备的日志信息进行分析总结,避免再次割接失败
2. 割接前准备阶段
- 割接前方案评审
- 设备登录方式、软件版本确认
- 割接涉及设备的健康检查和新设备的稳定性测试
- 割接涉及改动的线缆标签制作,以便回退使用
- 对割接人员培训和工作职责划分
- 割接前需对现网业务进行测试
3. 割接实施阶段
- 对现网设备进行备份存档,以便割接失败回退使用,同时做好状态检查和快照,以便操作后前后对比
- 按照割接方案中割接步骤,按计划实施,每完成一步需对配置和状态进行检查,以确定操作生效和状态正常
- 割接过程记录操作日志
- 割接完成后按照测试方案进行割接后测试
- 如割接失败则按照退回方案进行割接退回,回退后需按照测试方案进行业务测试
4. 割接后保障阶段
割接完成后,一般需对割接后新网络进行守局保障,万一割接后业务异常时,可以第一时间进行排查和定位,及时恢复。割接后如果客户有要求,可对运维人员进行关于新网络的培训,让客户的维护人员对新网络
更了解
割接过程中涉及的知识点
软割接与硬割接的区别
- 业务层面:不影响业务的称为软割接,影响业务的称为硬割接
- 时间层面:超过时间窗口的称为硬割接,没有超过的称为软割接
时间窗口与割接时间的区别
时间窗口是指我们在写割接方案时规定的具体割接时长,是计划性的时间
割接时间是指具体在实施割接时所用的时间,割接时间应该控制在时间窗口内(否则就变成硬割接)
串行割接与并行割接
- 网络设计层面:从核心到汇聚再到接入或者反之,则称为串行割接;并行割接就是不分层进行
- 实施节点层面:如果割接是按照不同的节点之间依次割接,则称为串行割接;如果多个地点同时割接则为并形割接
回退方案与应急方案的区别
回退方案是指当割接时,遇到了无法解决的故障,应该采用的办法,例如在升级设备时,所升级的版本导致用户业务无法访问,并且暂时没有解决方案,此时就需要回退到之前版本
应急方案是指当割接过程中,遇到了紧急事件的处理方式,例如在升级设备时,因设备重启导致板卡故障,此时应该在应急方案中写明需要事先准备备件
什么是值守(守局),一般需要多长时间
值守与守局是同一个概念,指的是当割接完成时,需要观察的时间
时间的长短是根据项目情况及客户情况共同商定的,大部分情况值守一天,如果割接影响的范围很大,可能会加长值守时间,也有可能需要定期回访
什么是快照
快照是指对当前设备所运行状态(数据)的一个副本,说白了就是备份。作用是方便恢复及数据备份
割接的目的是什么(什么是割接)
目的是根据具体割接内容来定的,也就是我们需要完成的工作
如何判断需要回退,回退时应该注意什么
回退是指出现了无法解决的问题,并且对现网业务有了一定的影响,作为一名前线的工程师,我们只能给出技术上的判断,具体回退与否应该第一时间与项目经理商定,由项目经理与客户共同决定是否回退
网络拓扑结构
各种拓扑的优缺点
局域网内部常见的网络拓扑有:星型拓扑、双星型拓扑、网状拓扑、部分网状拓扑、总线型拓扑
1. 星型拓扑(单星型)
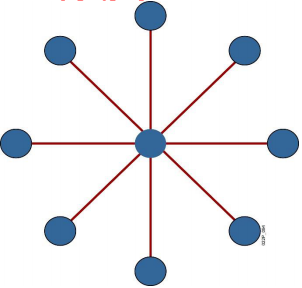
星型拓扑是由中央节点和通过点到点通信链路接到中央节点的各个站点组成。
中央节点执行集中式通信控制策略,因此中央节点相当复杂,而各个站点的通信处理负担都很小。
- 优点:
- 结构简单,连接方便,管理和维护都相对容易,而且扩展性强
- 网络延迟时间较小,传输误差低
- 在同一网段内支持多种传输介质,除非中央节点故障,否则网络不会轻易瘫痪
- 每个节点直接连到中央节点,故障容易检测和隔离,可以很方便地排除有故障的节点
- 缺点:
- 安装和维护的费用较高
- 共享资源的能力较差
- 一条通信线路只被该线路上的中央节点和边缘节点使用,通信线路利用率不高
- 对中央节点要求相当高,一旦中央节点出现故障,则整个网络将瘫痪
2. 网状拓扑
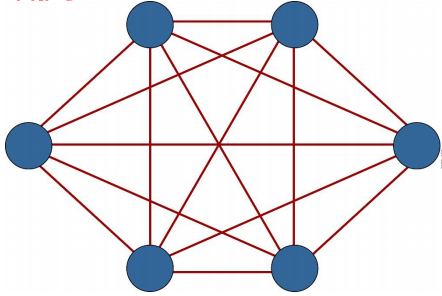
网型拓扑的一个应用是在BGP协议中。为保证IBGP对等体之间的连通性,需要在IBGP对等体之间建立全连接关系,即网状网络。假设在一个AS内部有n台路由器,那么应该建立的IBGP连接数就为n(n-1)/2 个
- 优点
- 节点间路径多,碰撞和阻塞减少
- 局部故障不影响整个网络,可靠性高
- 缺点
- 网络关系复杂,建网较难,不易扩充
- 网络控制机制复杂,必须采用路由算法和流量控制机制
3. 部分网状拓扑
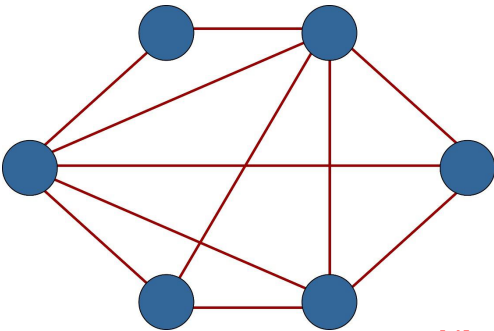
部分网状拓扑,在容错能力与成本之间寻求平衡
4. 双星型拓扑
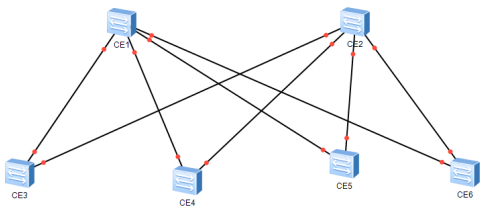
双星型的结构综合了单星型结构和网状结构的好处,即节省了链路,又能起到网状结构的路由冗余和备份的作用
5. 树形拓扑
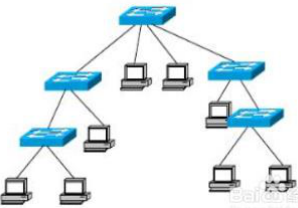
树型拓扑是多级星型结构组成的,自上而下呈三角形分布的,就像一颗树一样。
最顶端的枝叶少,中间的多,而最下面的枝叶最多。
树的最下端相当于边缘层,树中间相当于汇聚层,而树顶端则相当于核心层。
采用分级的集中控制方式,其传输介质可有多条分支,但不形成闭合回路,每条通信线路都必须支持双向传输。
- 优点
- 易于扩展。这种结构可以延伸出很多分支和子分支,这些新节点和新分支都能容易地加入网内
- 故障隔离较容易。如果某一分支的节点或线路发生故障,很容易将故障分支与整个系统隔离开来
- 缺点
各个节点对根的依赖性太大,如果根发生故障,则全网不能正常工作
6. 总线型拓扑
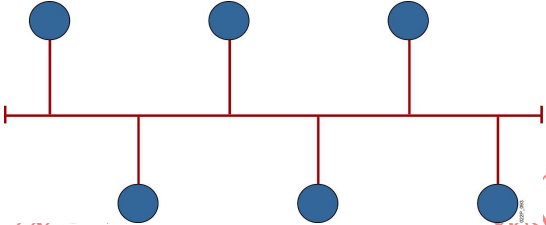
- 优点
- 所需要的电缆数量少,线缆长度短,易于布线和维护
- 结构简单,有较高的可靠性,传输速率高
- 易于扩充,增加或减少用户比较方便
- 多个节点共用一条传输信道,信道利用率高
- 缺点
- 传输距离有限,通信范围受到限制
- 故障诊断和隔离较困难
- 分布式协议不能保证信息的及时传送,不具有实时功能
7. 环型拓扑
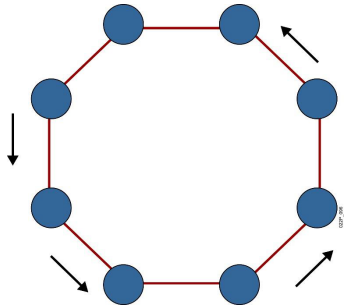
- 优点
- 电缆长度短
- 增加或减少工作站时,仅需简单的连接操作
- 可使用光纤,光纤的传输速率很高,十分适合于环型拓扑的单方向传输
- 缺点
- 节点的故障会引起全网故障
- 故障检测困难
- 环型拓扑结构的媒体访问控制协议都采用令牌传递的方式,在负载很轻时信道利用率
相对来说就比较低