- MPLS概述
- MPLS重点
- LDP
- MPLS VPN
- 防环
- BGP接入MPLS VPN
- MPLS VPN故障排查
- 实验
- 实验一:MPLS-LDP
- 实验二:R2和R4建立远端LDP会话
- 实验三:PHP
- 实验四:研究MPLS解决BGP路由黑洞的原理
- 实验五:基本MPLS VPN部署
- 实验六:OSPF接入MPLS VPN
- 实验七:配置ospf的domain-id
- 实验八:三类LSA防环逆向实验
- 实验九:在R1和R4之间部署 sham-link
- 实验十:配置路由反射器(本实验是下一个实验的预配置)
- 实验十一:使用VRF-LITE将用户接入MPLS VPN(hub-spoke)
- 实验十二:BGP接入MPLS VPN
- 实验十三:如果不采用默认路由的方式,如何传递明细路由呢?(BGP接入MPLS VPN)
- 实验十四:VRF下的路由操控(上个实现的场景三)
MPLS概述
本节课主要内容:
- 对比传统IP转发与MPLS:IP转发回顾、MPLS转发特点、MPLS应用场景
- MPLS基本原理:MPLS基本构架、MPLS标签格式、MPLS转发
- LDP协议:共有标准协议 标签分发协议
- MPLS VPN体系构架
- MP-BGP在MPLS VPN中的重要作用
- MPLS VPN路由隔离模型(vrf)
- MPLS VPN路由区分原理(RD)
- MPLS VPN路由传递原理(RT)
- MPLS VPN数据转发原理(label)
- MPLS VPN环境下的路由反射器及路由区分器
- 在MPLS VPN环境中部署不同overlay动态路由协议(基础理论及实验)
- backup link 环境:EIGRP路由还原、OSPF sham-link
- 多宿主环境:EIGRP SOO、BGP SOO
- vrf-lite环境下的OSPF
- BGP as-override
- BGP allowas-in
- 控制MPLS VPN中的路由更新:通过RT、vrf条件性路由控制
- MPLS VPN接入互联网
- MPLS VPN故障排查
传统IP转发
- 传统路由循规蹈矩:每跳都检查是否有去往目标的,如若没则丢弃报文
- 传统IP转发在流量工程方面的缺陷。传统IP网络基于IGP Metric计算最优路径,这是远远不够的,往往在现实网络中还需考虑带宽、链路属性等其他因素。基于 IP 的流量工程是基于 IGP 面向目的地址转发,是hop-by-hop的转发,无法实现根据来源控制流量转发。另外基于IP的流量工程是面向无连接的,不能实现显式路径
MPLS知识点
- MPLS能够提高转发效率,但同时它将消耗更多资源
- MPLS更多的是解决了每个数据包都要进行头部分析或者运算的问题,不再对IP报文做分析
- MPLS的标签栈,比IP年轻、比IP轻量。MPLS并不是一种业务或应用,他实际上是一种隧道技术,这种技术不仅支持多种高层协议与业务,而且在一定程度上可以保证信息传输的安全性
- 帧模式MPLS

MPLS帧模式封装在2、3层之间,信元模式的MPLS已经淘汰 - MPLS头

- MPLS头部总长度为4bytes (32bits)
- 标签Label长度20bits标签值域
- EXP(Experimental Use)长度3bits用于扩展。现在通常用做CoS,当设备阻塞时,优先发送优先级高的报文
- S(Bottom of Stack)长度1bit栈底标识。MPLS支持多层标签,即标签嵌套。S值为1时表明为最底层标签
- TTL长度8bits 和IP报文中的TTL(Time To Live)意义相同
- 标签空间:指标签的取值范围。标签空间划分如下:
- 0~15:特殊标签
- 0:IPv4 Explicit NULL Label(显示空标签),表示该标签必须被弹出(即标签被剥掉),且报文的转发必须基于IPv4。如果出节点分配给倒数第二跳节点的标签值为0,则倒数第二跳LSR需要将值为0的标签正常压入报文标签值顶部,转发给最后一跳。最后一跳发现报文携带的标签值为0,则将标签弹出。
- 1:Router Alert Label(警告标签),只有出现在非栈底时才有效。类似于IP报文的“Router Alert Option”字段,节点收到Router Alert Label时,需要将其送往本地软件模块进一步处理。实际报文转发由下一层标签决定。如果报文需要继续转发,则节点需要将Router Alert Label压回标签栈顶。
- 2:IPv6 Explicit NULL Label(显示空标签),表示该标签必须被弹出,且报文的转发必须基于IPv6。如果出节点分配给倒数第二跳节点的标签值为2,则倒数第二跳节点需要将值为2的标签正常压入报文标签值顶部,转发给最后一跳。最后一跳发现报文携带的标签值为2,则直接将标签弹出。
- 3:Implicit NULL Label(隐式空标签),倒数第二跳LSR进行标签交换时,如果发现交换后的标签值为3,则将标签弹出,并将报文发给最后一跳。最后一跳收到该报文直接进行IP转发或下一层标签转发。
- 4~13:保留
- 14:OAM Router Alert Label(MPLS的操作管理),MPLS OAM通过发送OAM报文检测和通告LSP故障。OAM报文使用MPLS承载。OAM报文对于Transit LSR和倒数第二跳LSR是透明的。
- 15:保留
- 16~1023:静态LSP和静态CR-LSP共享的标签空间
- 1024及以上:LDP、RSVP-TE、MP-BGP等动态信令协议的标签空间
- 0~15:特殊标签
- 标签可以由多种方法产生:LDP、MP-BGP。标签产生的依据是路由,为路由分配标签(TCP/IP环境中)
- 入站LSR上有路由表(RiB),但其实会被拷贝为转发信息库(FiB)、标签信息库(LiB),递归为标签转发信息库(LFib),标签信息库存储的是标签,实际上,可以将其理解为标签与路由的映射
- 一旦开启了LDP,它会自动的为每个路由分配标签值,路由协议把路由更新给邻居,LDP把标签和路由的映射信息更新给邻居
LDP为IGP路由分配标签 - LDP标签值,遵循 独立、自主、自由的原则。每台设备独立分配标签,每台设备自主分发标签,每台设备自由选择标签保留方式。
- 标签行为总结:
- 压入标签push
- 交换标签swap
- 弹出标签pop(remove,隐式空标签)
- UNTAG/No label(没有标签)出现问题,在MPLS VPN的环境中只能丢弃报文
关于标签断裂:所有的环回口配置32位主机路由,核心网不许汇总 - Aggregate(聚合),把报文拿掉MPLS之后转发给一个vpn-instance接口
- 分发标签的协议:
- LDP(标签分发协议);思科私有的有TDP,SR(segment routing)
- RSVP(资源预留协议)
- MP-BGP(多协议BGP),来分发标签
- 静态的方式分发标签
- MPLS重要理念:转控分离
- 控制层面:路由协议、标签的分发协议
- 转发层面:FIB(转发信息库)、LFIB(标签转发信息库)
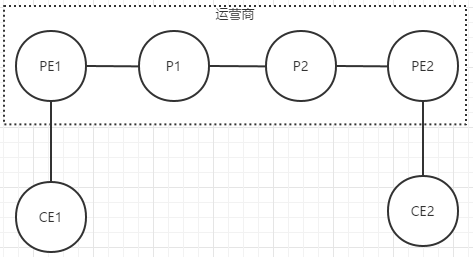
- 术语
- CE:客户边界设备。CE(Customer Edge),用户边缘设备,服务提供商所连接的用户端路由器。CE路由器通过连接一个或多个PE路由器,为用户提供服务接入。CE路由器通常是一台IP路由器,它与连接的PE路由器建立邻接关系。
通常就是传统操作 - PE:运营商边界设备。PE(Provider Edge),即Provide的边缘设备,服务提供商骨干网的边缘路由器,它相当于标签边缘路由器(LER)。PE路由器连接CE路由器和P路由器,是最重要的网络节点。用户的流量通过PE路由器流入用户网络,或者通过PE路由器流到MPLS骨干网。
通常会为每个与CE相连的部分做出特殊处理 - P:运营商内部的设备。仅仅负责帮助转发数据。P(Provider),是核心层设备,提供商路由器,服务提供商是不连接任何CE路由器的骨干网路由设备,它相当于标签交换路由器(LSR)
- LSR:标签交换路由器
- LER:标签边缘路由器(PE)
- CPE:三巨头中两个互联,为同一个客户服务
- MCE:MCE功能是Multi-CE的简称,具有MCE功能的交换机可以在BGP/MPLS VPN组网应用中承担多个VPN实例的CE功能,减少用户网络设备的投入
- vrf(华为称vpn instance):在PE设备上起到隔离作用,每一个vrf提供一个独立的路由表,同时甚至能够提供独立的路由协议进程。用一个PE为多个用户提供服务,通过VRF实例将连接到同一台PE上的不同客户隔离开来
- LSP:标签交换通道,LSP是一个单向通道,与数据流的方向一致
- FIB:转发信息库,来自路由表拷贝
- LIB:标签信息库,由标签协议根据路由产生的标签和路由的对应关系
- LFIB:标签转发信息库,把FIB和LIB两者结合在一起
- FEC:转发等价类。MPLS将具有相同特征的报文归为一类,称为转发等价类FEC,属于相同FEC的报文在转发过程中被LSR以相同方式处理。FEC可以根据源地址、目的地址、源端口、目的端口、VPN、隧道、COS等要素进行划分。例如,在传统的采用最长匹配算法的IP转发中,到同一条路由的所有报文就是一个转发等价类
- 一组或者一系列沿着相同路径转发的,且都按照相同的规则执行的数据流
- 相同的转发方式、相同的转发路径LSP、相同的转发待遇
- 同属一个FEC的报文拥有相同的标签,拥有相同标签的报文不一定同属一个FEC,由入站LSR决定报文属于哪一个FEC
- 种类:
- 属于某特定组的组播报文
- 目的IP地址匹配了某一个特定前缀的报文
- 根据DCSP字段,有相同的QoS策略的报文
- MPLS VPN中,属于同一个VPN的报文
- 报文的目的IP地址数据BGP学习到的路由,并且该路由的下一跳地址相同
- NHLFE:下一跳标签转发表项,用于指导MPLS报文的转发,包括Tunnel ID、出接口、下一跳、出标签、标签操作类型等信息。FEC到一组NHLFE的映射称为FTN(FEC-to-NHLFE),通过查看FIB表中Tunnel ID值不为0x0的表项,能够获得FTN的详细信息,FTN只在Ingress存在
- Tunnel ID:为了给使用隧道的上层应用(如VPN、路由管理)提供统一的接口,系统自动为隧道分配了一个ID,也称为Tunnel ID。该Tunnel ID的长度为32比特,只是本地有效
- ILM:入标签到一组下一跳标签转发表项的映射称为入标签映射ILM,ILM包括Tunnel ID、入标签、入接口、标签操作类型等信息。ILM在Transit节点的作用是将标签和NHLFE绑定。通过标签索引ILM表,就相当于使用目的IP地址查询FIB,能够得到所有的标签转发信息。
- CE:客户边界设备。CE(Customer Edge),用户边缘设备,服务提供商所连接的用户端路由器。CE路由器通过连接一个或多个PE路由器,为用户提供服务接入。CE路由器通常是一台IP路由器,它与连接的PE路由器建立邻接关系。
MPLS重点
MPLS报文转发
- 从CE到Ingress PE
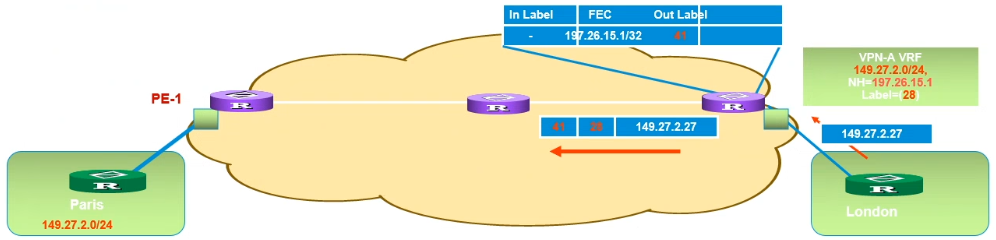
- CE将报文发给其相连的VRF接口,PE在本VRF的路由表中进行查找,得到了该路由的公网下一跳地址和私网标签
- 再把该报文封装一层私网标签后,在公网的标签转发表中查找下一跳地址,在封装一层公网标签后,交予MPLS转发
- Ingress PE-->Egress PE-->CE
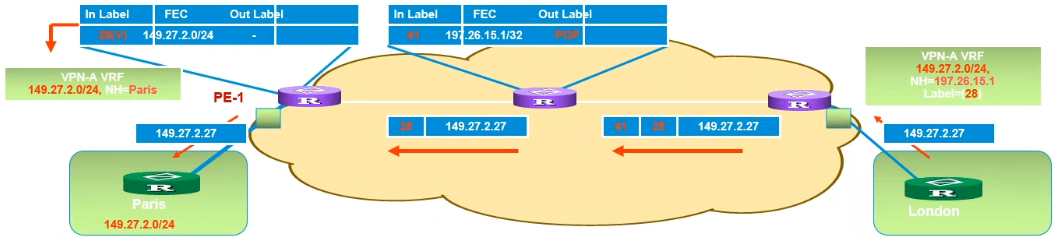
- 该报文在公网上沿着LSP转发,并根据途径的每一台设备的标签转发表进行标签交换
- 在倒数第二跳处,将外层的公网标签弹出,交给目的的PE设备
- PE设备根据内层的私网标签判断该报文属于哪一个VRF
- 弹出内层私网标签,在目的VRF中查找路由表,根据下一跳发给相应的CE
MPLS体系结构
MPLS结构:
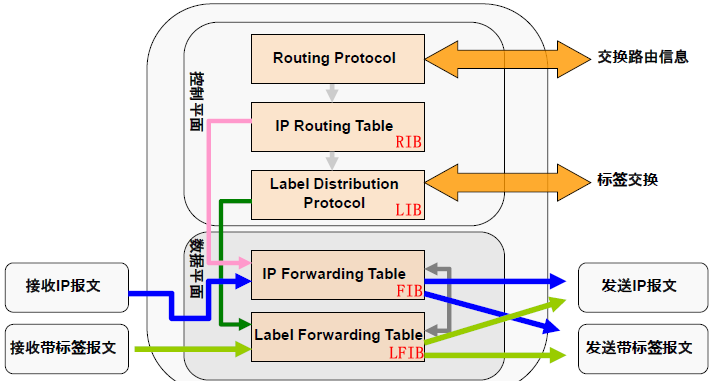
MPLS VPN中的数据转发模型:
- IP报文入站,通过路由表做转发决策,出方向的路由上有标签转发信息,则可以选择压入标签
- 标签报文入站,通过标签转发表做出转发决策,出方向如果有标签则执行标签交换,然后转发,如果出方向没有标签,则移除标签然后路由转发
MPLS体系结构:
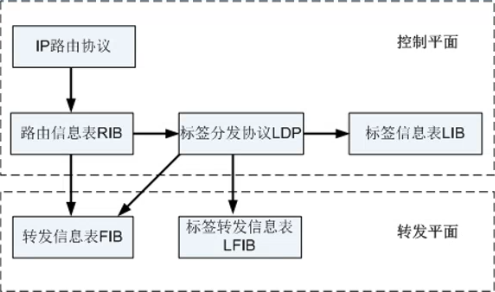
控制平面
负责产生和维护路由信息以及标签信息
- 路由信息表RIB:由IP路由协议生成,用于选择路由
- 标签分发协议:负责标签的分配,标签转发信息表的建立,标签交换路径的建立、拆除等工作
- 标签信息表LIB:由标签分发协议生成,用于管理标签信息
转发平面
即数据平面,负责普通IP报文的转发以及带MPLS标签报文的转发
- 转发信息表FIB:从RIB提取必要的路由信息生成,负责普通IP报文的转发
- 标签转发信息表LFIB:简称标签转发表,由标签分发协议在LSR上建立LFIB,负责带MPLS标签报文的转发
MPLS标签嵌套
内层标签(栈底标签):靠近用户数据,MP-BGP分配
外层标签:靠近二层头,LDP分配,作为MP-BGP路由的下一跳地址
一般情况为2层,跨域的一般3层标签,CSC架构一般4层标签

- PID标识二层头部后面的报文类型
- Ethernet
- 0x0800 IPv4
- 0x8847 MPLS单播报文
- 0x8848 MPLS多播报文
- PPP
- 0x8021 IPv4
- 0x8281 MPLS单播报文
- 0x8283 MPLS多播报文
- Ethernet
- S标识是否是栈底标签
- 标签嵌套应用
- MPLS VPN
- MPLS TE
路由传递和数据转发
- MP-BGP跨越核心网络传递客户路由,中间存在路由黑洞,路由的下一跳是PE设备的环回口
- VPN路由在PE设备上产生,PE(PE1)设备通过MP-BGP为VPN路由分配一个标签(内层),该标签随着VPN路由被MP-BGP传递至远端对等体(PE2)
- PE2上就有远端站点的路由和标签,通过LDP协议为MP-BGP(VPN)路由的下一跳分配外层标签
- 数据从客户始发,由CE2转发到PE2
- PE2查找vrf路由表,压入内层标签,查找全局路由表,压入外层标签
- 标签报文沿着核心网(core network)转发,逐跳交换外层标签,外层标签次末跳弹出
实施MPLS VPN的基本步骤
- MPLS Core/Core network/核心网 的IGP
- Core network的LDP
- PE之间部署MP-BGP,实施VPNv4
- 在PE设备上部署VRF/VPN-instance
- 在PE-CE之间部署路由交互
- 将vrf的路由与MP-BGP双向重分布
LDP
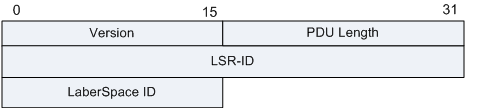
基本概念
- LDP是用来在LSR之间建立LDP会话并交换Label/FEC映射信息的协议
- LDP
- 用UDP发现邻居:组播(224.0.0.2)在链路上发送hello报文,目标端口646,通告传输地址
- 用TCP建立邻居:目标端口646
LDP消息
类型

- Discovery message:宣告和维护网络中一个LSR的存在
- Session message:建立、维护和终止LDP邻居之间的LDP会话
- Advertisement message:生成、改变和删除FEC的标签映射
- Notification message:宣告告警和错误信息
作用
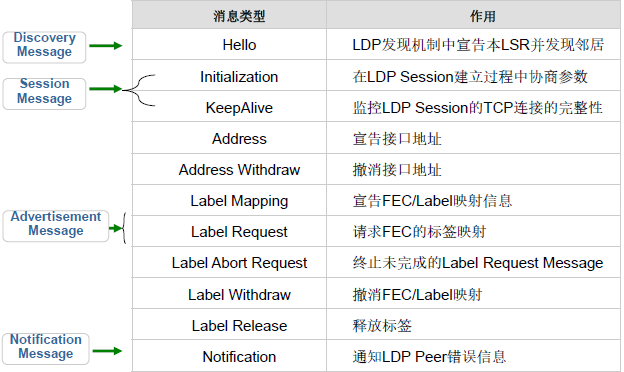
头部格式类型

LDP发现机制
- LDP基本发现机制
发现直接连接在同一链路上的LSR邻居 - LDP扩展发现机制
发现非直连的LSR邻居,即跨越设备的LDP会话
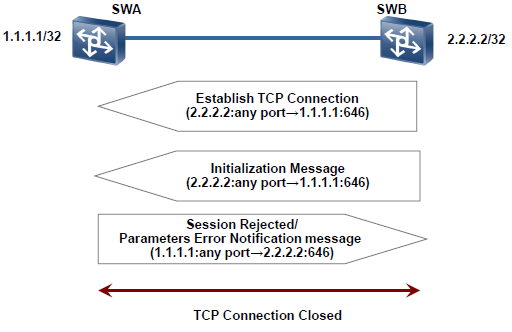
LDP会话建立过程
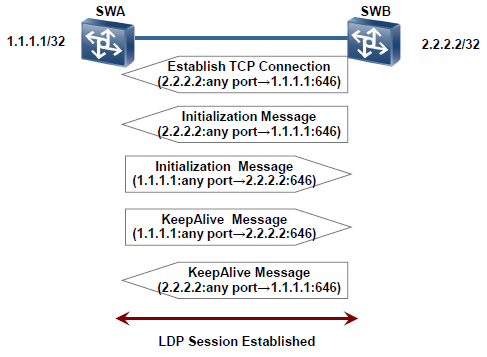
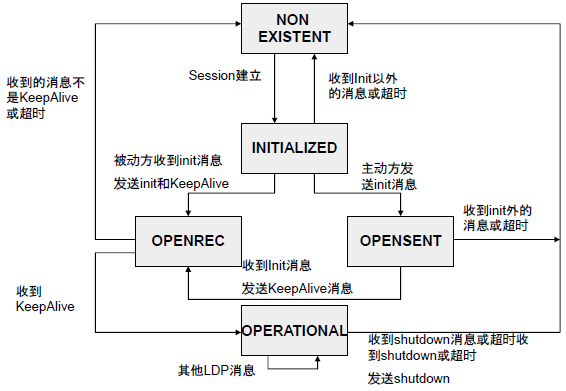
LDP状态机
LDP标签管理
0代表基于平台的标签,基于平台的标签空间中,LSR为一个目的网段分配一个标签,并将该标签
发送给所有的LDP Peers。
标签分发(通告)模式
缺省情况下,华为根据32位地址的主机IP路由(不包括接口的32位地址的主机IP路由)触发LDP建立LSP;思科为所有的IGP路由分发标签。
使用命令mpls ldp advertisement [dod|du]进行修改
DoD 下游按需(被动)模式
(思科采取的模式)
每台LSR主动向LSP中的下一跳LSR请求绑定于特定FEC的标签
每台LSR只会从下游LSR为每一个FEC接收到一个捆绑的标签
这里所说的下游,是指IP路由表中的下一跳路由器
UD(或者DU)下游自主(主动)模式
每台LSR主动向邻接LSR分发捆绑的标签,也就是说不需要邻居来请求
标签分配控制模式(LSP控制模式)
独立标签分配控制
(思科采取的模式)
当使用独立的LSP控制时,每个LSR都可以在需要时随时向其邻居通告标签映射。
例如,
- 当以独立的下游按需模式(UD模式)运行时,LSR可以立即回答对标签映射的请求,而无需等待来自下一跳的标签映射。
- 当以独立的下游非请求模式(DOD模式)运行时,只要准备对标签交换该FEC,LSR就会向其邻居通告FEC的标签映射。
使用独立模式的结果是可以在接收下游标签之前通告上游标签
有序标签分配控制
(华为采取的模式)
当使用LSP顺序控制时,LSR可以仅针对FEC为其启动具有FEC下一跳标签映射的FEC或LSR为出口的FEC发起标签映射的传输。
对于不是LSR出口且不存在映射的每个FEC,LSR必须等到收到来自下游LSR的标签,然后再映射FEC并将相应的标签传递给上游LSR。
对于某些FEC,LSR可能是出口,而对于其他FEC,LSR可能不是出口。对于特定的FEC,LSR可以充当出口LSR,在以下任何条件下:
- FEC是指LSR本身(包括其直接连接的接口之一)。
- FEC的下一跳路由器在标签交换网络之外。
- 通过跨越路由域边界即可到达FEC元素,例如OSPF摘要网络的另一个区域,或OSPF AS外部和BGP路由的另一个自治系统
标签保留模式
LLR 自由标签保留模式
(华为、思科采取的模式)
保留所有标签,被使用的保存到LFIB中
这样如果网络发生变化,可以快速收敛
CLR 保守标签保留模式
(思科 LC-ATM接口)
不使用的标签不保留,节省维护资源
总结
- 思科:DU+Independent+LLR,即自主分发+独立分配+自由保留
- 华为:DU+Order+LLR,即自主分发+有序分配+自由保留,华为配置独立标签分配控制命令为
mpls ldp && label distribution control-mode independent - 标签分发模式:
- 下游自主方式DU:给邻居通告标签
对于一个特定的FEC,LSR无需从上游获得标签请求消息即进行标签分发,该模式为默认行为 - 下游按需方式DOD:
LSR会主动向下游请求特定的FEC(路由下一跳)的分配信息,下游LSR获得标签请求消息之后才进行标签分发
- 下游自主方式DU:给邻居通告标签
- 标签捆绑/分配控制(LSP控制模式):为FEC分配标签
- Independent 独立控制:
一旦发现一个FEC,就会为其创建一个本地捆绑标签(分配),即使该路由并不是本地起源的,缺点在于可能在成LSP建立不完整的情况下开始转发报文 - Order 有序控制(非独立控制):
仅当自身为出站LSR,或者从下游收到该FEC的标签才进行分配
- Independent 独立控制:
- 标签保留/保持模式:LSP的保持
- Conservative 保守的 CLR:
仅当邻居是相应路由的下一跳的时候才保留 - Liberal 自由的 LLR:
统统保留,一旦IGP路径切换,其实表桥已经存在
- Conservative 保守的 CLR:
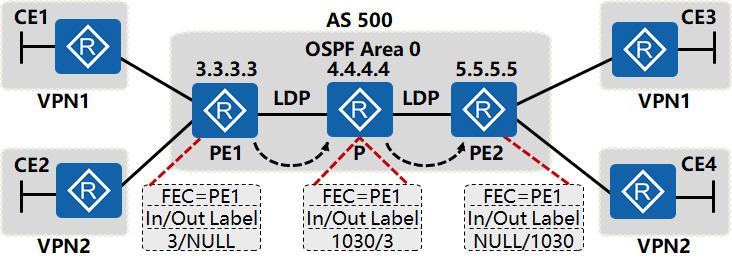
PHP次末跳弹出(倒数第二跳弹出)
在LSP的最后一跳节点,已不再需要在进行标签交换,此时,可以配置倒数第二跳弹出特性PHP,在倒数第二跳节点处将标签弹出,最后一跳节点直接进行IP转发或者下一层标签转发,减少最后一跳标签交换负担。
Egress PE向倒数第二跳节点分配隐式空标签,值为3。
在次末跳交换为隐式空标签,意味着应当弹掉这层标签,如果只有一层标签,则变成IP报文了,同时请注意,该转发决策由LFIB决定,转发出接口、二层重写信息已经就绪。
LDP环路检测机制
- IGP环路检测机制:TTL环路检测
- 帧模式中的MPLS中使用TTL,信源模式中的MPLS中为TTL
- LDP环路检测机制
- 距离向量法
标签绑定报文中记录路径信息,即标签交换路由器会检查本设备的ID是否包含在路径信息中。路由路径中没有本设备的ID,那么添加,否则认为出现了环路,终止LSP建立。类似于BGP的as-path参数 - 最大跳数法
标签绑定报文中包含跳数信息,即每经过一个子网(设备)跳数值会增加1,一旦跳数值超过规定的最大值,则认为出现环路,从而终止LSP建立
- 距离向量法
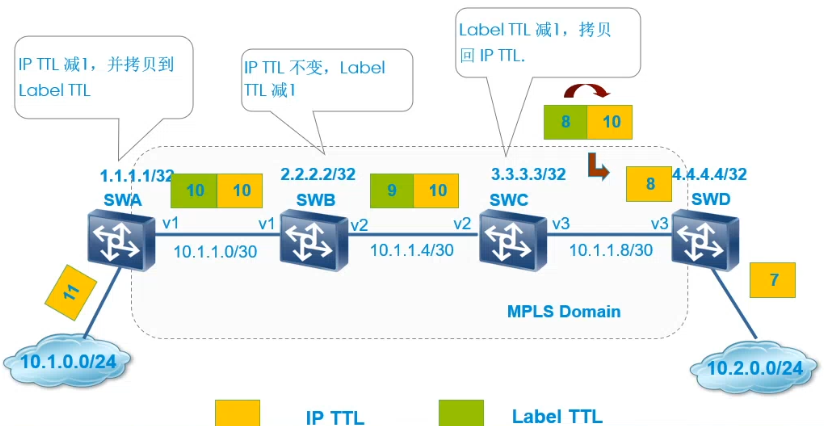
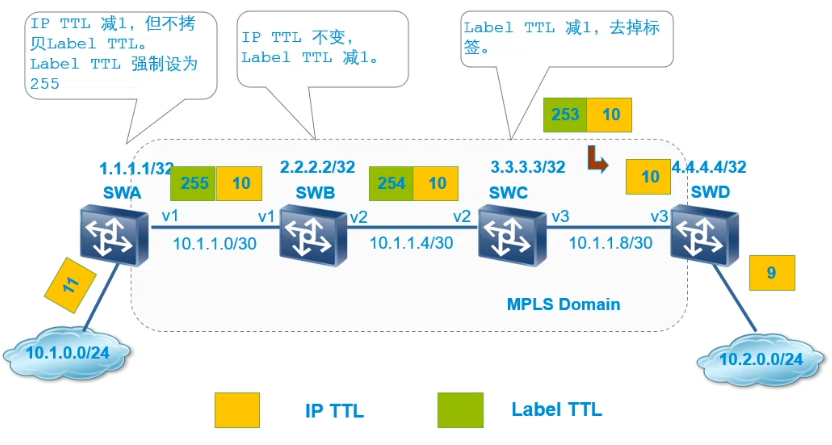
MPLS对TTL的处理(Uniform模式)
统一模式
Uniform统一模式,IP的TTL和标签的TTL相互拷贝:
- 在入口PE不做改变的把IP的TTL拷贝到标签TTL
- 在MPLS区域按照外层的TTL进行转发,在次末跳上把标签的TTL拷贝回IP
- 多层标签默认只处理外层标签,只有外层标签弹出之后再处理内层标签
管道模式
在入接点,IP TTL值减1,MPLS TTL字段为固定值,此后报文在MPLS网络中按照标准的TTL处理方式处理。在出节点会将IP TTL字段的值减1。
即IP分组经过MPLS网络时,无论经过多少跳,IP TTL只有在入接点和出节点时分别减1。
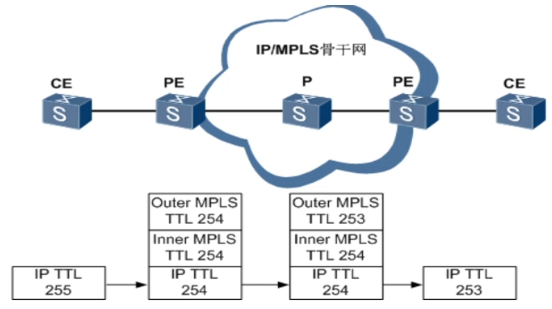
PIPE管道模式,核心网对用户是透明的,整个MPLS区域被看做一个设备,标签的TTL和IP的TTL没有相互拷贝。
核心网络处理方式
如果我们需要隐藏MPLS核心网,则强制进入MPLS核心网的报文,将标签上的TTL强制设置为255
核心网络处理方式为将标签的TTL设置为255,IP标签在MPLS网络中不改变,当标签弹出之后再重新启用IP的TTL
MPLS VPN
VPN模型
Overlay VPN
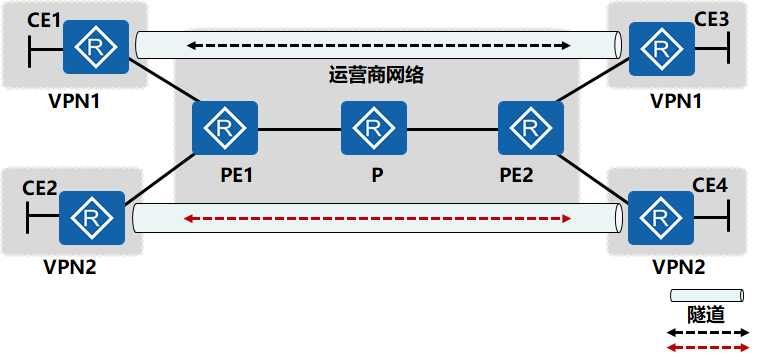
Overlay VPN可以在CE设备上建立隧道,也可以在PE设备上建立隧道,特点:客户路由协议总是在客户设备之间交换,而运营商对客户网络结构一无所知。典型的协议:二层——帧中继;三层——GRE与IPSec;应用层——SSL VPN。
- 在CE与CE之间建立隧道,并直接传递路由信息,路由协议数据总是在客户设备之间交换,运营商对客户网络结构一无所知
- 优点:不同的客户地址空间可以重叠,保密性、安全性非常好
- 缺点:本质是一种“静态”VPN,无法反应网络的实时变化,并且当有新增站点时,需要手工在所有站点上建立与新增站点的连接,配置与维护复杂,不易管理
- 在PE上为每一个VPN用户建立相应的隧道,路由信息在PE与PE之间传递,公网中的P设备不知道私网的路由信息。
- 优点:客户把VPN的创建及维护完全交给运营商,保密性、安全性比较好
- 缺点:不同的VPN用户不能共享相同的地址空间
Peer-to-Peer VPN
在CE设备与PE设备之间交换私网信息,由PE设备将私网信息在运营商网络中传播,实现了VPN部署及路由发布的动态性,解决了Overlay VPN的“静态”性质不太适合大规模应用和部署的问题。
共享PE
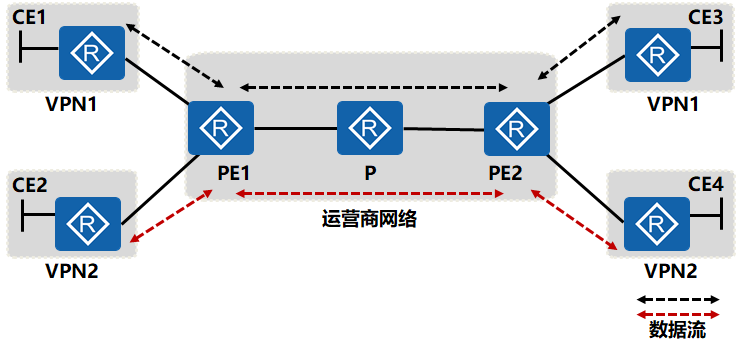
所有VPN用户的CE设备都连到同一台PE上,PE与不同的CE之间运行不同的路由协议(或者是相同路由协议的不同进程)。由始发PE将路由发布到公网上,在接收端的PE上将路由过滤后再发给相应的CE设备。
- Peer-to-Peer是在CE与PE之间交换私网路由信息,然后由PE将私网路由在运营商网络中传播,由于CE与PE之间运行了路由协议,所以私网路由会自动地传播到PE上;由于Peer-to-Peer VPN将私网路由泄露到公网上,所以必须通过严格的路由过滤和选择机制来控制私网路由的传播。
- 缺点:
- 为了防止连接在同一台PE上的不同CE之间互通,必须在PE上配置大量的ACL,但这种操作也增加了管理PE设备的负担
- VPN客户之间如果出现地址重叠问题,PE设备无法识别重叠的地址。
图中的Peer-to-Peer VPN使用的是共享PE的接入方式,为了减少配置复杂度,便于管理,可以采用Peer-to-Peer VPN的专用PE接入方式。
专用PE
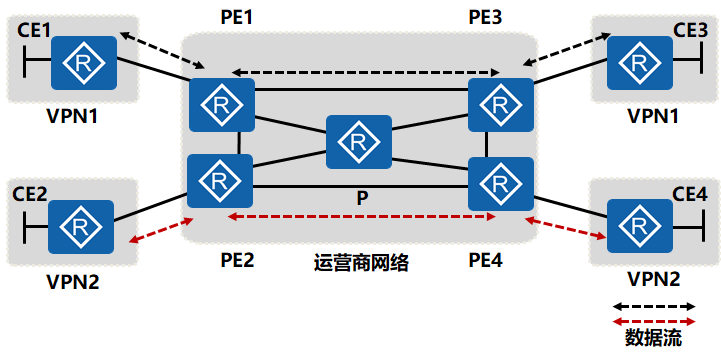
- Peer-to-Peer VPN的专用PE的接入方式特点:运营商为每一个VPN单独准备一台PE设备,PE和CE之间可以运行任意的路由协议,与其他VPN无关。
- 优点:无需配置任何的ACL,配置复杂度、管理难度有所降低
- 缺点:每新增一个VPN站点都需要新增一台专用的PE设备,代价过于昂贵。而且没有解决VPN客户之间地址空间重叠的问题。
解决的问题
地址空间重叠
两个客户的VPN存在相同的地址空间,传统VPN网络结构中的设备无法区分客户重叠的路由信息,即地址空间的重叠问题。
- PE设备怎么区分不同VPN客户的相同路由?
可以通过在同一台PE设备上为不同的VPN建立单独的路由,这样冲突的的路由就被隔离开来 - 冲突路由在公网中传播时,接收端PE如何正确导入VPN客户路由?
在路由传递过程中,为不同的VPN路由添加不同的标识,以示区别,这些标识可以作为BGP属性进行传递 - PE设备收到IP数据包后,如何正确的发送给目的VPN客户?
由于IP报文不可更改,可以在IP报文头前加一些信息。由始发路由器打上标记,接收路由器在收到带标记的的数据包时,根据标记转发给正确的VPN
专用PE的解决方案
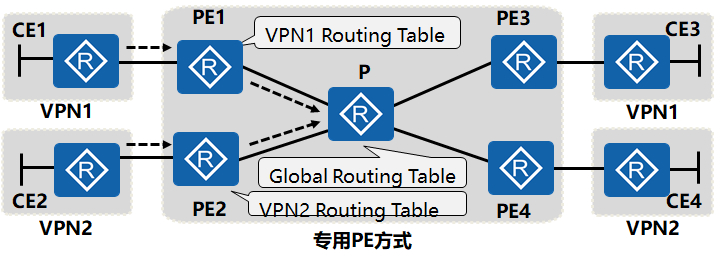
专用PE设备分工明确,每个PE设备只保存自己的VPN路由,P设备只保存公网路由。因此解决共享PE设备上地址空间重叠的思路是:将专用PE设备与P设备的功能在同一台PE设备上完成,并实现VPN路由的隔离。
共享PE的解决方案
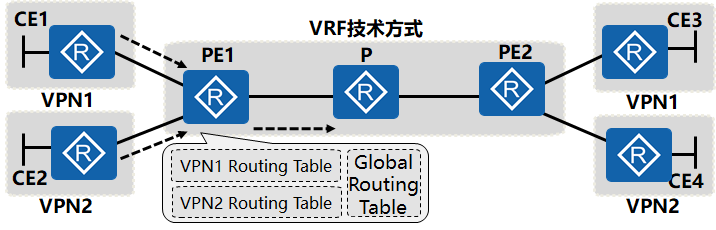
在共享PE设备上使用VRF技术将重叠的路由隔离:每个VPN的路由放入自己对应的VPN Routing Table中。
PE设备在维护多个VPN Routing Table时,同时还维护一个公网的路由表。
- 共享PE设备上实现重叠路由的隔离就是在PE设备上将来自每个VPN的路由放入自己对应的VPN Routing Table中,每个VPN Routing Table只记录对应VPN中学来的路由,就像是专用PE一样。这个VPN Routing Table称谓VRF,即VPN路由转发表。
- 每一个VRF都需要对应一个VPN instance,VPN用户对应的接口绑定到VPN instance中。
- 对于每个PE,可以维护一个或多个VPN instance ,同时维护一个公网的路由表(也叫全局路由表),多个VPN instance实例相互独立且隔离。其实实现VPN instance并不困难,关键在于如何在PE上使用特定的策略规则来协调各VPN instance和全局路由表之间的关系。
区分冲突路由(RD,Route Distinguisher)
将VPN路由发布到全局路由表之前,使用一个全局唯一的标识和路由绑定,以区分冲突的私网路由,这个标识被称为RD
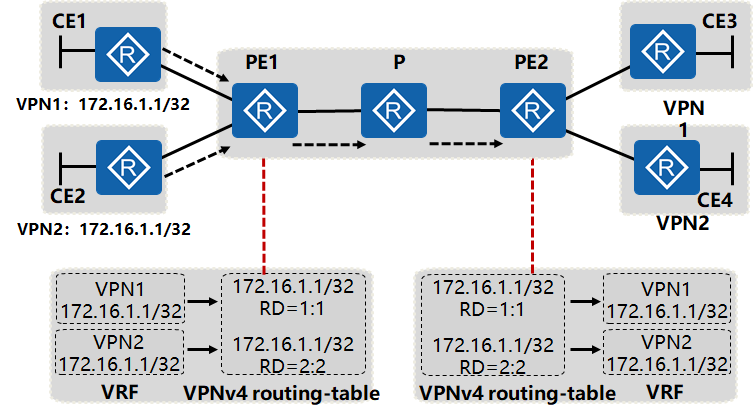
- RD即VPN路由标识符,由8字节组成,配置时同一PE设备上分配给每个VPN的RD必须唯一
- RD用于区分使用相同地址空间的IPv4前缀,增加了RD的IPv4地址称为VPN-IPv4地址(即VPNv4地址)
- 运营商设备采用BGP协议作为承载VPN路由的协议,并将BGP协议进行了扩展,称为MP-BGP。PE从CE接收到客户的IPv4私网路由后,将客户的私网路由添加各种标识信息后变为VPNv4路由放入MP-BGP的VPNv4路由表中,并通过MP-BGP协议在公网上传递。
VPN路由的引入(RT,Route Target)
Hub-Spoke场景中VPN路由的引入问题:
如图所示,某公司分部1与分部2中存在172.16.1.1/32与172.16.2.1/32的私网地址,公司希望实现各分部只能与总部通信,分部之间不能相互通信。分配给分部1的VPN RD为1:1,分配给分部2的VPN RD为2:2。如果要使用RD解决路由引入VPN的问题,总部与分部1通信,则RD的值需要配置成1:1,总部与分部2通信,则RD的值需要配置成为2:2。但RD的值在本地PE上是唯一的,并且只能配置一个。因此,不能使用RD来解决路由正确引入的问题。
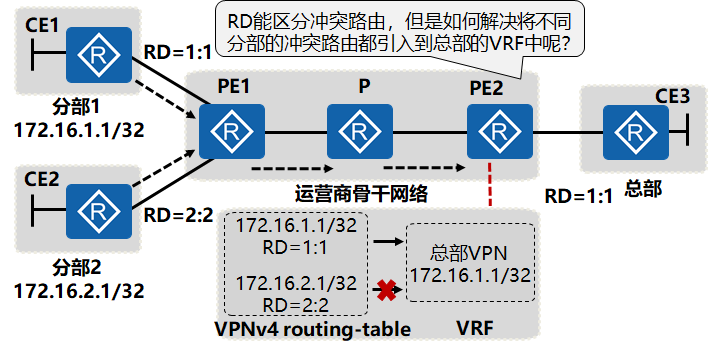
RD不能解决VPN路由正确引入VPN的问题。需要一种类似于Tag的标识,这个标识由人工分配,发送端PE发送时打上标识,接收端PE收到后,根据需要将带有相应标识的路由引入VPN。
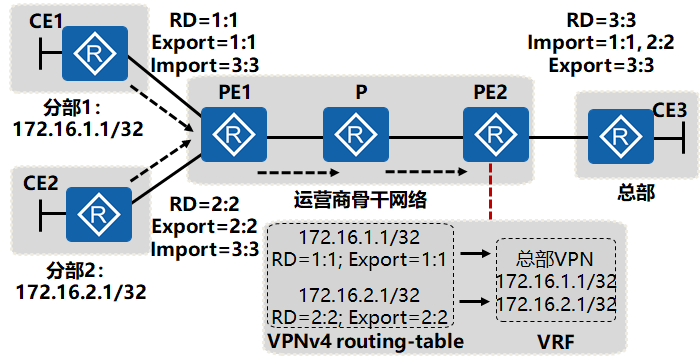
RT属性用于将路由正确引入VPN,有两类VPN Target属性,Import Target和Export Target,分别用于VPN路由的导出与导入。
- 如图所示,希望实现分部只能与总部通信,分部之间不能通信。
- 分配给分部1的Export Target为1:1,Import Target为3:3
- 分配给分部2的Export Target为2:2,Import Target为3:3
- 分配给总部的Export Target为3:3,Import Target为1:1,2:2
- PE2上收到对端PE1发送的VPNv4的路由后,检查其Export Target。因为总部的Import Target为1:1,2:2,所以值为1:1或2:2的路由被引入总部的VRF。PE1的VPNv4的路由引入各分部VRF的过程类似。
- RT封装在BGP的扩展Community属性中,在路由传递过程中作为可选可传递属性进行传递
- RT的本质是每个VRF表达自己的路由取舍及喜好的属性,有两类VPN Target属性:
- Export Target:本端的路由在导出VRF,转变为VPNv4的路由时,标记该属性
- Import Target:对端收到路由时,检查其Export Target属性。当此属性与PE上某个VPN实例的Import Target匹配时,PE就把路由加入到该VPN实例中。
- 使用RT实现本端与对端的路由正确引入VPN,原则为:
- 本端的Export Target=对端的Import Target
- 本端的Import Target=对端的Export Target
冲突路由的查找
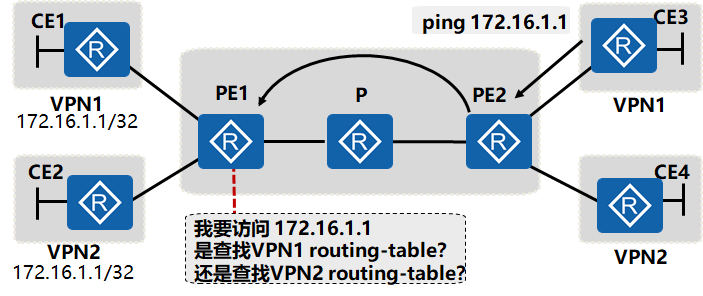
因为数据包没有携带任何标识,所以在ICMP的数据包到达PE1时,PE1并不知道该查找哪个VPN的路由表找到正确的目标地址。解决该问题的方案有两种:
- 在数据包中增加标识信息,并且使用RD作为区分数据包所属VPN的标识符,数据转发时也携带RD信息。缺点是由于RD由8字节组成,额外增大数据包,会导致转发效率降低
- 借助公网中已经实施的MPLS协议建立的标签隧道,采用标签作为数据包正确转发的标识,MPLS标签支持嵌套,可以将区分数据包所属VPN的标签封装在公网标签内。
使用标签嵌套解决数据转发过程中冲突路由的查找问题:
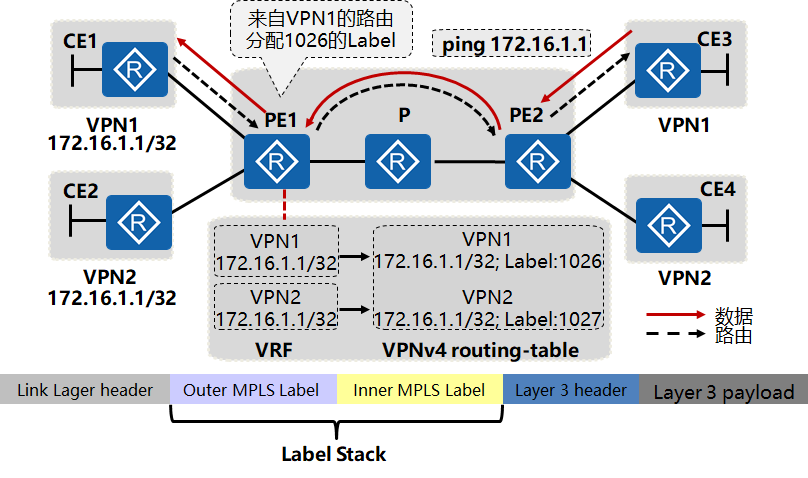
Outer MPLS Label在MPLS VPN中被称为公网标签,用于MPLS网络中转发数据。一般公网标签会在到达PE设备时已被倒数第二跳剥掉,漏出Inner Label。Inner MPLS Label在MPLS VPN中被称为私网标签,用于将数据正确发送到相应的VPN中,PE依靠Inner Label区分数据包属于哪个VPN。
工作原理
MPLS VPN的工作过程分为两部分:
MPLS VPN路由的传递过程
1. CE与PE之间的路由交换
PE与CE之间可以通过静态路由协议交换路由信息,也可以通过动态路由协议(如:RIP,OSPF,ISIS,BGP等)交换路由信息
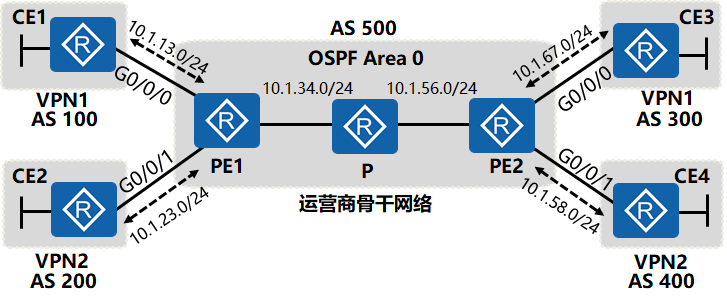
2. VRF路由注入MP-BGP的过程
VRF中的IPv4路由被添加上RD、RT与标签等信息成为VPN-IPv4的路由放入到MP-BGP的路由表中,并通过MP-BGP协议在PE设备之间交换路由信息
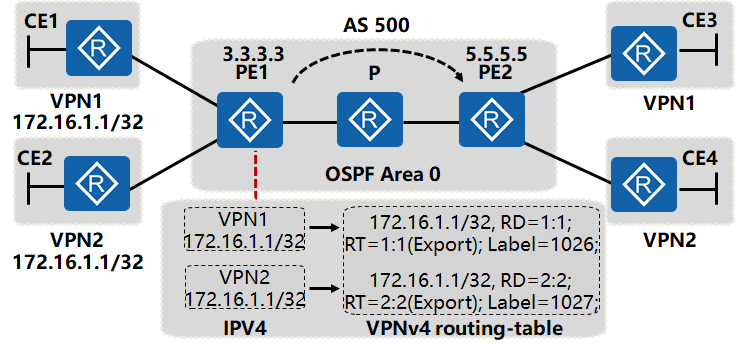
3. 公网标签的分配过程
MPLS协议在运营商网络分配公网标签,建立标签隧道,实现私网数据在公网上的转发。
PE之间运行的MP-BGP协议为VPN路由分配私网标签,PE设备根据私网标签将数据正确转发给相应的VPN。
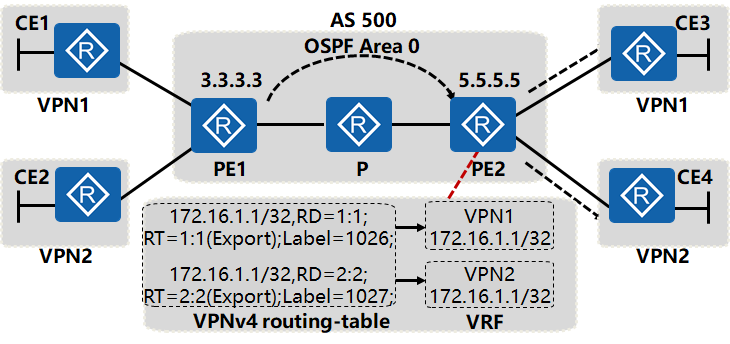
4. MP-BGP路由注入VRF的过程
PE2在接收到PE1发送的VPNv4路由后将检查路由的扩展团体属性,将携带的Export Target值与本端VPN的Import Target值比较,数值相同则将路由引入VPN的路由表,实现路由的正确导入。
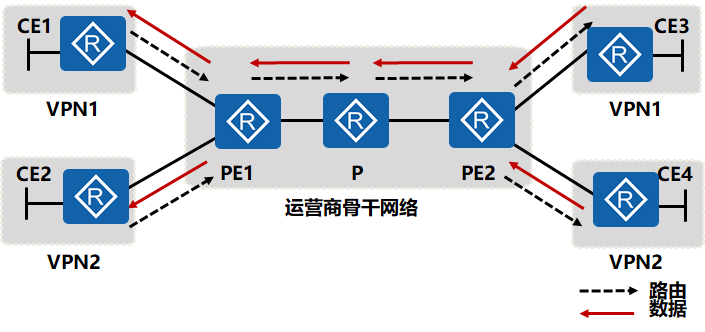
MPLS VPN数据的转发过程
1. CE设备到PE设备的数据转发
数据从CE4转发给PE2,在PE2设备上需要查找VPN2的路由表,确定数据进行标签转发后,再查找下一跳与出接口,根据分配的标签进行MPLS的封装。
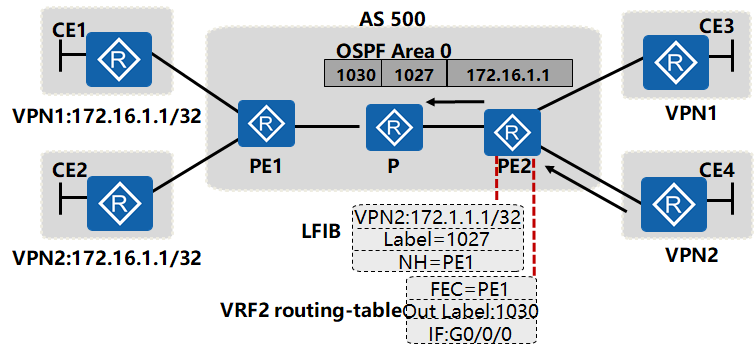
- CE4所连接的VPN2的用户要与对端VPN2中的172.16.1.1/32用户通信,PE2收到数据包后,查找本地VPN2的路由表,发现数据包需要进行标签转发,分配的私网标签为1027,到达目标地址的下一跳为PE1
- PE2通过查找LFIB表,发现到达PE1被分配的公网标签为1030,出接口为G0/0/0,PE2将数据包进行MPLS封装,内层为1027,外层为1030,从接口G0/0/0转发出去。
2. 公网设备上的数据转发
数据包在公网上转发时,通过MPLS协议已建立好的标签隧道将数据报文转发到PE1。转发过程中,只改变公网标签。
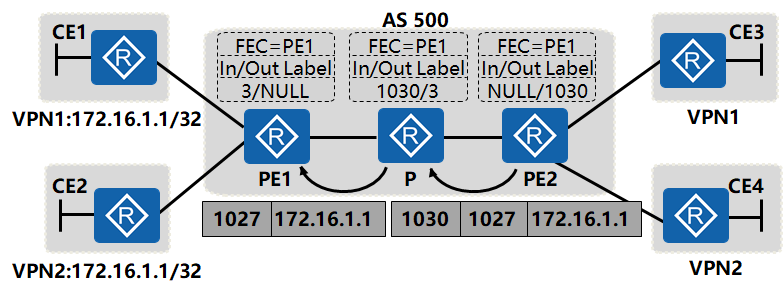
PE2收到VPN用户的数据包后,封装上MPLS的标签,将私网数据通过MPLS建立的标签隧道进行转发,PE2上数据包封装的公网标签为1030,转发给P设备后,查找LFIB表,进标签为1030的数据包,对应的出标签为3,即将公网标签标签剥离后,将数据包发送给PE1,PE1收到的是只有内层私网标签的数据包。
3. PE设备到CE设备的数据转发
PE1收到剥离公网标签的数据包后,根据私网标签查找转发数据包的下一跳,将数据包正确发送给相应VPN客户
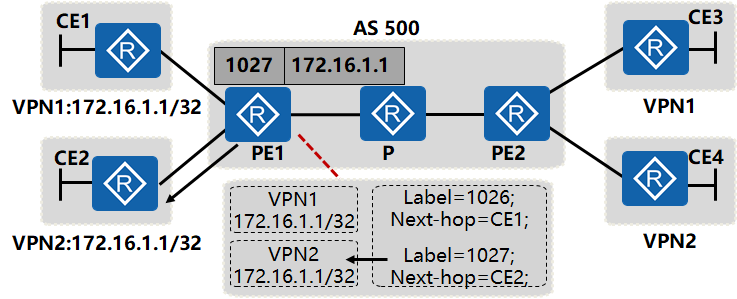
PE1收到只有一层标签的数据包,查找标签表,发现标签为1027的数据包对应的下一跳为CE2,于是PE2将数据包剥离私网标签,进行IP封装,查找出接口,将数据包发送给CE2处理,数据包到达正确的目标用户 。
总结
路由传递
RD:路由区分器 ,是一个64bit的数值,PE设备将这个值加在来自vrf的IPv4或者IPv6路由前面形成VPNv4/VPNv6路由,该路由被通告进MP-BGP
VRF是在PE设备上起到路由隔离作用,而RD是在传递过程中起到路由区分作用
在PE设备上产生了经过RD做了全局区分的VPNv4路由,那么现在需要解决路由如何通过MP-BGP传递的问题:建立一个专为VPNv4服务的地址族下的邻居会话。通过一个附加的操控方案,保障只有那些有需要被传递至指定PE设备的路由才会被传递。RT route-target, 一个BGP扩展团体属性,通过针对BGP收发路由定义根据扩展团体属性RT的策略实现
数据转发
当PE设备产生VPNv4路由时,会通过MP-BGP为其分配一个标签。
IP报文进入PE设备,根据目标IP地址查找LFIB。
内层标签用于数据到达远端之后,决定转发至哪个接口(vrf里面),外层标签用于在MPLS核心网中转发数据。
部署PE-CE路由的小提示
- 如果使用静态,则PE需要在vrf下写静态;
- 如果使用IGP,则需要双向重分布;
- 如果是BGP,则不需要重分布,但PE在vrf地址族下做配置;
内层标签由PE MP-BGP分配,标识报文到达本PE后转发至哪个出接口或者vrf;
外层标签由LDP分配,在Core network依据外层标签转发;
标签在产生VPNv4路由时,由MP-BGP分配,同时标签将跟随路由更新给对等体
防环
多宿主环境下的SoO(EIGRP协议)
SoO(sign of origin)BGP的扩展团体属性用于在多出口情况下阻止环路。唯一的SoO值必须为每个VPN站点配置,该值(sitemap)应用于PE-CE连接的接口下,SoO值通过一个route-map配置,其本质是不把收到的路由再传给客户站点,部署在PE的vrf接口下,其值一般为ASN:nn或者IP-address:nn
EIGRP协议接入MPLS VPN的防环:
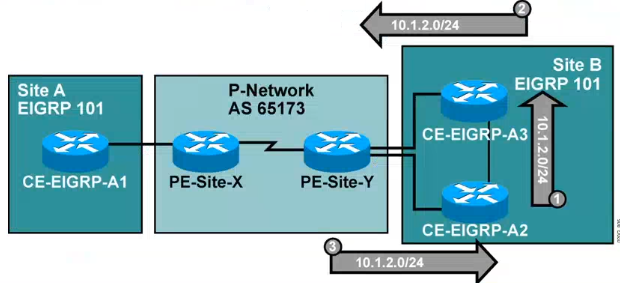
在双出口(多归属)的环境,极有可能会出现路由环路,图中10.1.2.0/24,SoO之后在PE收到的时候就不会再传给CE,即PE-Y不会再传给CE-A2
原理
- 从CE收到的路由引入MP-BGP,增加扩展团体属性值自定义SoO
- 其它PE设备不将携带特定SoO属性值的路由传递给同站点的CE
- 相同SoO值,被PE认为是同站点
举例说明
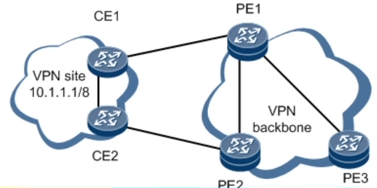
- 在PE1上针对CE1对等体指定SoO属性,该属性相当于标识了CE1所在Site
- 当CE1发布路由给PE1时,PE1为这些路由携带上该SoO属性
- PE1通过骨干网将这些路由发布给PE2时也将携带此SoO属性
- PE2将这些路由发布给自己的CE2对等体时,如果PE2发现路由中携带的SoO属性与其上针对CE2对等体配置的SoO属性相同,说明这些路由就是由该Site(CE1所在的site)发出的,从而拒绝将路由发布给CE2对等体,从而避免了VPN site内路由环路的产生
OSPF的防环
Domain-ID
- 域标识符(Domain ID)用来标识和区分不同的域
- 本地OSPF区域和VPN远端的OSPF区域间如果相互发布区域间路由Type3 LSA,则这些区域必须属于同一个OSPF域,即使用domain-id命令配置相同的OSPF域标识
- 通常情况下,从PE路由器引入的路由将会作为External-LSA发布出去,但对属于同一个OSPF域不同节点的目的地,这样的路由应该作为Type3 LSA发布,这就需要为同一个OSPF域使用相同的域标识符,华为设备默认为NULL,思科设备上默认为进程ID
- 当有了vrf之后,就会有domain-id的概念,即不同的ospf域,默认情况下为ospf的进程号,所有当两端的进程号不一致时,会被认为是External-LSA。当然也可以手动配置domain-id
三类LSA防环(Down bit)
多协议BGP引入OSPF时自动增加Down位,会在区域内保留,其他PE检测到Down位,拒绝把OSPF引入BGP,即此条三类LSA的路由不参与路由选择,也保证数据的优先转发。
vrf或者vpn实例下绑定的OSPF进程,对带有down bit的三类LSA不能计算
OSPF接入MPLS VPN,本身自己设置了防环规则和解决方案,是自动的,华为可以使用vpn-instance-capability simple进行关闭
从PE引入到OSPF LSDB的外部LSA,down bit置位
外部路由的环路预防(5类/7类LSA防环)
外部路由(5、7类):TAG(BGP的AS号码),PE检测到5类LSA的TAG=设备自身的AS号码则拒绝引入。
默认情况下,与vrf实例绑定的OSPF不仅检测三类LSA的down bit,还检测TAG
sham-link(v-link虚假链路)
- 场景:站点之间存在其它专有链路(后门链路,如下图中R8与R10间粉红色背景的链路)的情况下
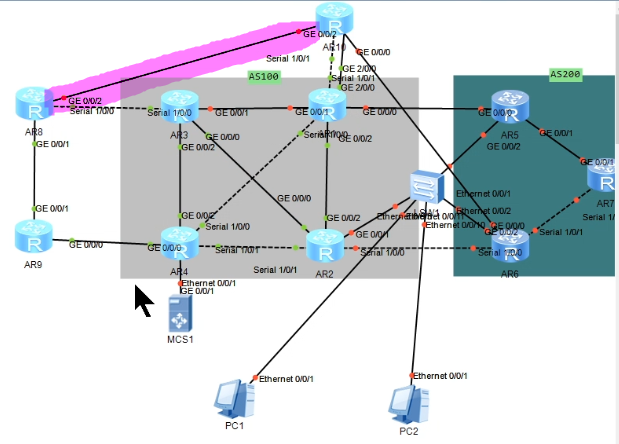
- 原理:在PE上的vrf实例之间通过单播建立sham-link,然后单播传递LSA,还原MPLS环境下OSPF的LSA报文的正常传输
- 配置:
- 在PE设备上为vrf创建独立环回口,必须/32
- 将其注入BGP的vrf对应地址族,绝不允许注入OSPF
- 配置sham-link
在sham-link中,内层标签由多协议BGP分配,从vrf的客户路由协议OSPF到BGP的重分布是需要做的,否则没有内层标签
OSPF的MEC/VRF-LITE
MCE是Multi-VPN-Instance CE(多实例CE)的简称,具有MCE功能的设备在BGP/MPLS IP VPN组网应用中承担多个VPN实例的CE功能,减少用户网络设备的投入,一个私有网络内的用户需要划分成多个VPN,不同的VPN用户的业务需要完全隔离
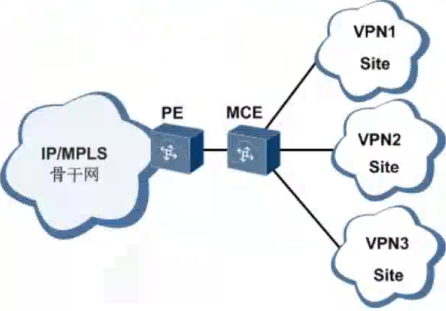
VPNv4的路由反射器与所有PE建立邻居关系,负责反射路由。cisco和huawei的区别:默认情况下,cisco的VPNv4反射器收取所有VPNv4路由,但华为的正好相反。
BGP接入MPLS VPN
BGP接入MPLS VPN解决的问题
可以不用做OSPF与BGP的双向重分布
如果不采用默认路由的方式,如何传递明细路由呢?
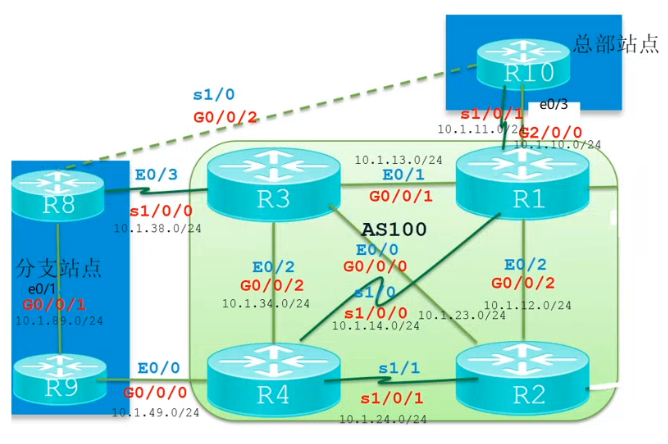
问题描述
例如使用默认路由的方式,如果R8/9访问互联网,则访问互联网的流量也经过总部的R10。
目前R8与R9的路由可以正常传到R1,然后传递给R10,但是R10不会再传递给R1(ebgp防环)。
此时需要解决的问题如下:
- R10如何将路由传递给R1【ebgp防环】
- R8将路由通过R3-R2-R1传递给R10,R10再传递下来(给R1)之后,会导致R1上有两条R8的路由,这两条路由不能共存,此时会选择从R8发来的路由,而不选择从R10传过来的【bgp的路由优选】
- R2是vpnv4的路由反射器,路由从R1传递给R2,站在R2路由反射器的角度看,R3和R1上都有R8的路由,这只能选择一个【RD需要区分开】
- 如何控制收发的问题
对应的解决方案
- 中心场点的PE修改eBGP防环
- 中心场点PE通过多vrf区分传出和传入的路由
- 中心场点PE通过不同RD区分传出和传入的路由,以使得VPNv4的RR能够同时保存传出和传入的路由
- 通过RT控制传出的路由和传入的路由的更新方向,中心PE:vrfA收、vrfB发;分支PE:发给vrfA、收取vrfB。
- Import Route-Policy可以过滤VPN实例IPv4地址族引入的路由信息,以及为通过过滤的路由信息设置路由属性
- Export Route-Policy命令用于将当前VPN实例的IPv4地址族与一条出方向的Route-Policy进行关联
- Routing-table limit命令用来配置当前VPN实例地址族下所能容纳的路由数量
MPLS VPN故障排查
用户不能互访
- 控制平面故障
- CE之间是否有路由可达
- CE是否发布路由给PE,检查PE与CE之间的路由
- PE是否发布路由给PE
- PE之间是否建立MP-IBGP邻居
- PE之间LSP是否建立
- 检查MPLS和LDP配置
- 数据平面故障
- 是否存在MTU问题
实验
实验拓扑:

预配置:
# R1
sys
sys R1
ospf 1
a 0
network 0.0.0.0 255.255.255.255
int lo 0
ip addr 11.1.1.1 32
int lo 1
ip addr 11.11.11.11 32
int g0/0/0
ip addr 12.1.1.1 24
# R2
sys
sys R2
ospf 1
a 0
network 0.0.0.0 255.255.255.255
int lo 0
ip addr 22.1.1.1 32
int g0/0/0
ip addr 12.1.1.2 24
int g0/0/1
ip addr 23.1.1.2 24
# R3
sys
sys R3
ospf 1
a 0
network 0.0.0.0 255.255.255.255
int lo 0
ip addr 33.1.1.1 32
int g0/0/0
ip addr 23.1.1.3 24
int g0/0/1
ip addr 34.1.1.3 24
# R4
sys
sys R4
ospf 1
a 0
network 0.0.0.0 255.255.255.255
int lo 0
ip addr 44.1.1.1 32
int g0/0/0
ip addr 34.1.1.4 24
int g0/0/1
ip addr 45.1.1.4 24
# R5
sys
sys R5
ospf 1
a 0
network 0.0.0.0 255.255.255.255
int lo 0
ip addr 55.1.1.1 32
int lo 0
ip addr 55.55.55.55 32
int g0/0/0
ip addr 45.1.1.5 24
实验一:MPLS-LDP
# 配置LDP
# R1
mpls lsr-id 11.1.1.1 # 全局配置,系统视图
mpls # 进入MPLS视图
mpls ldp # 开启LDP协议
int g0/0/0 # 接口下开启MPLS和LDP
mpls
mpls ldp
# R2
mpls lsr-id 22.1.1.1
mpls
mpls ldp
int g0/0/0
mpls
mpls ldp
int g0/0/1
mpls
mpls ldp
# R3
mpls lsr-id 33.1.1.1
mpls
mpls ldp
int g0/0/0
mpls
mpls ldp
int g0/0/1
mpls
mpls ldp
# R4
mpls lsr-id 44.1.1.1
mpls
mpls ldp
int g0/0/0
mpls
mpls ldp
int g0/0/1
mpls
mpls ldp
# R5
mpls lsr-id 55.1.1.1
mpls
mpls ldp
int g0/0/0
mpls
mpls ldp
# 检查
# R1~5
dis mpls ldp peer
# R1
ping lsp -a 11.1.1.1 ip 55.1.1.1 32 # 测试LSP(标签是单向交换的)
实验二:R2和R4建立远端LDP会话
应用于L2 VPN以及会话保护
常见的LDP邻居问题:
- IGP协议错误导致RID地址不可达(环回接口掩码错误,华为仅仅为/32的路由分标签)
- 修改传输地址
- 认证,LDP支持认证
- ACL引发的问题
# R2
mpls ldp remote-peer QYT
remote-ip 44.1.1.1
# R4
mpls ldp remote-peer QYT
remote-ip 22.1.1.1
# 查看
# R2/4
dis mpls ldp remote-peer
dis mpls ldp lsp
实验三:PHP
# 查看(默认为隐式空标签)
# R4
dis mpls ldp lsp
dis mpls lsp # 查看去往55.1.1.1的标签
# 同时抓取AR4的两个接口进行报文对比,g0/0/0接口有标签,g0/0/1接口无标签
# R5
mpls
label advertise explicit-null # 显示空标签
# R4
reset mpls ldp all
# 此时重复上面抓包动作,发现g0/0/1接口有标签0
实验四:研究MPLS解决BGP路由黑洞的原理
1和5使用传统的IP转发,2、3、4使用MPLS转发
- 配置IGP路由
- 配置静态路由,1、2、4、5
- 配置BGP并通告静态路由
- R2、3、4开启 LDP
- 测试
# 配置IGP路由:预配置
# 配置静态路由
# R1
ip route-static 55.55.55.55 32 12.1.1.2
# R2
ip route-static 11.11.11.11 32 12.1.1.1
# R4
ip route-static 55.55.55.55 32 45.1.1.5
# R5
ip route-static 11.11.11.11 32 45.1.1.4
# 配置BGP并通告静态路由
# R2
bgp 100
peer 44.1.1.1 as-number 100
peer 44.1.1.1 next-hop-local
peer 44.1.1.1 connect-interface lo 0
network 11.11.11.11 32
# R4
bgp 100
peer 22.1.1.1 as-number 100
peer 22.1.1.1 next-hop-local
peer 22.1.1.1 connect-interface lo 0
network 55.55.55.55 32
# 测试
# R1
ping -a 11.11.11.11 55.55.55.55 # 此时R1无法ping通R5
# R1/2/4/5
undo mpls # 关闭mpls,然后重新配置
# R2
mpls lsr-id 22.1.1.1
mpls ldp
int g0/0/1
mpls
mpls ldp
# R4
mpls lsr-id 44.1.1.1
mpls ldp
int g0/0/0
mpls
mpls ldp
# 查看邻居
# R2/3/4
dis mpls ldp peer
# R2
ping lsp -a 22.1.1.1 ip 44.1.1.1 32 # R2和R4是通的,但此时R1和R5不通,原因是在R2的路由表中去往55.55.55.55的IBGP路由下一跳为44.1.1.1(44.1.1.1是OSPF路由,下一跳为23.1.1.3,出接口为g0/0/1),递归之后为23.1.1.3,不通过lsp隧道进行转发,因此需要使用下面的命令,即R3上没有55.55.55.55的路由,这条路由的路径是1-2-4-5
# R2\4
route recursive-lookup tunnel
# 此时R1上:ping -a 11.11.11.11 55.55.55.55 是能够通的
实验五:基本MPLS VPN部署
- 部署域内IGP(预配置)
- 部署域内LDP(上面实验已经配置)
- 部署MP-BGP,建立起VPNv4邻居
- 定义VPN实例并绑定到接口(注意此步会清空接口配置),不要忘记配置静态路由
- 在PE设备上为VPN实例与VPNv4交互路由
# 删除ospf
# R1/5
undo ospf 1
# R2
int g0/0/0
undo ospf en 1 ar 0
# R4
int g0/0/01
undo ospf en 1 ar 0
# 开始配置
# 部署MP-BGP,建立起VPNv4邻居
# R2
bgp 100
ipv4-family unicast
undo network 11.11.11.11 32
undo peer 44.1.1.1 enable
q
ipv4-family vpnv4 unicast
peer 44.1.1.1 enable
q
# R4
bgp 100
ipv4-family unicast
undo network 55.55.55.55 32
undo peer 22.1.1.1 enable
q
ipv4-family vpnv4 unicast
peer 22.1.1.1 enable
# 定义VPN实例并绑定到接口
# R2
ip vpn-instance qyt666
route-distinguisher 100:100
vpn-target 100:24 export-extcommunity
vpn-target 100:42 import-extcommunity
int g0/0/0
ip binding vpn-instance qyt666 # 此时地址会被清空,需要重新配置
ip addr 12.1.1.2 24
q
undo ip route-static 11.11.11.11 32 12.1.1.1
ip route-static vpn-instance qyt666 11.11.11.11 32 12.1.1.1
# R4
ip vpn-instance qyt666
route-distinguisher 100:100
vpn-target 100:42 export-extcommunity
vpn-target 100:24 import-extcommunity
int g0/0/1
ip binding vpn-instance qyt666
ip addr 45.1.1.4 24
q
undo ip route-static 55.55.55.55 32 45.1.1.5
ip route-static vpn-instance qyt666 55.55.55.55 32 45.1.1.5
# 在PE设备上为VPN实例与VPNv4交互路由
# R2
bgp 100
ipv4-family vpn-instance qyt666
network 11.11.11.11 32
# R4
bgp 100
ipv4-family vpn-instance qyt666
network 55.55.55.55 32
# 测试
# R2/4
dis ip rou vpn-instance qyt666
dis mpls lsp
dis bgp vpnv4 all rou
dis ip vpn-instance verbose
# R1
ping -a 11.11.11.11 55.55.55.55
下面实验使用BGP专题的路由:
实验六:OSPF接入MPLS VPN
只需要开启R1/2/3/4/8/9/10,其中R10为总部支点,R8/9为分支站点,R1/2/3/4为运营商网络
配置步骤:
- 配置核心网域内IGP
- 配置域内LDP
- 配置域内MP-BGP
- 配置VRF绑定到接口(注意IP地址)、定义RD、RT
- 配置PE-CE路由交互及重分布
# 1. 配置核心网域内IGP
# R4
int lo 0
ip addr 44.1.1.1 24
# 2. 配置域内LDP
# R1
mpls
mpls lsr-id 11.1.1.1
mpls ldp
q
int g0/0/1
mpls ldp
int g0/0/2
mpls ldp
int s1/0/0
mpls ldp
# R2
mpls
mpls lsr-id 22.1.1.1
mpls ldp
q
int s1/0/1
mpls ldp
int g0/0/2
mpls ldp
int g0/0/0
mpls ldp
# R3
mpls
mpls lsr-id 33.1.1.1
mpls ldp
q
int g0/0/0
mpls ldp
int g0/0/2
mpls ldp
int g0/0/1
mpls ldp
# R4
mpls
mpls lsr-id 44.1.1.1
mpls ldp
lsp-trigger all # 默认是host,只为主机路由(/32)分配标签,此处改成host,否则lo0的地址无法分配标签
q
int s1/0/1
mpls ldp
int g0/0/2
mpls ldp
int s1/0/0
mpls ldp
# 测试
# R1
ping lsp -a 11.1.1.1 ip 44.1.1.1 32
dis mpls ldp lsp
dis mpls ldp peer
# 3. 配置域内MP-BGP
# R1
bgp 100
ipv4-family vpnv4 unicast
peer 44.1.1.1 enable
# R4
bgp 100
ipv4-family vpnv4 unicast
peer 11.1.1.1 enable
# 查看
# R1/4
dis bgp vpnv4 all peer
# 4. 配置VRF绑定到接口(注意IP地址)、定义RD、RT
# R1
ip vpn-instancce michael
route-distinguisher 100:1
vpn-target 100:110 export-extcommunity
vpn-target 100:409 import-extcommunity
q
int g2/0/0
ip binding vpn-instance michael
ip address 10.1.110.1 24
# R4
ip vpn-instancce michael
route-distinguisher 100:1
vpn-target 100:409 export-extcommunity
vpn-target 100:110 import-extcommunity
q
int g0/0/0
ip binding vpn-instance michael
ip address 10.1.49.4 24
# 5. 配置PE-CE路由交互及重分布
# R9
int lo 0
ip addr 99.1.1.1 32
int g0/0/0
ip addr 10.1.49.9 24
ping 10.1.49.4
# R10
int lo 0
ip addr 110.1.1.1 32
int g2/0/0
ip addr 10.1.110.10 24
ping 10.1.110.1
# 进程号码配置为109,注意如果核心网的IGP是OSPF,PE的进程号不能与全局冲突
# R9
ospf 109
a 0
int lo 0
ospf enable 109 area 0
int g0/0/0
ospf network-type p2p
ospf enable 109 area 0
# R10
ospf 109
a 0
int lo 0
ospf enable 109 area 0
int g2/0/0
ospf network-type p2p
ospf enable 109 area 0
# R1
ospf 109 vpn-instance michale
a 0
int g2/0/0
ospf network-type p2p
ospf enable 109 area 0
# R4
ospf 109 vpn-instance michale
a 0
int g0/0/0
ospf network-type p2p
ospf enable 109 area 0
# 双向重分布
# R1
bgp 100
ipv4-family vpn-instance michael
import-route ospf 109
q
ospf 109
import-route bgp
q
dis ip rou pro ospf
dis ip rou pro bgp
# R4
bgp 100
ipv4-family vpn-instance michael
import-route ospf 109
q
ospf 109
import-route bgp
dis ip rou pro ospf
dis ip rou pro bgp
实验七:配置ospf的domain-id
# R1
ospf 109
domain-id 109
# 此时在R9上dis ip rou pro ospf,可以看到所有的路由都变成外部路由O_ASE
# R4
ospf 109
domain-id 109
# 此时再在R9上dis ip rou pro ospf,可以看到所有的路由110.1.1.1/32又变回OSPF内部路由了
实验八:三类LSA防环逆向实验
关闭down bit 检测,允许计算路由,从而产生环路
# R8
ospf 109
area 0
int lo 0
ip add 88.1.1.1 32
ospf en 109 a 0
int s1/0/0
ip addr 83.1.1.8 24
ospf en 109 a 0
ospf network-type p2p
int g0/0/1
ip addr 89.1.1.8 24
ospf en 109 a 0
ospf network-type p2p
#R9
int g0/0/1
ip addr 89.1.1.9 24
ospf en 109 a 0
ospf network-type p2p
# R3
ip vpn-instance michael
ipv4-family
route-distinguisher 100:1
vpn-target 100:308 export-extcommunity
vpn-target 100:110 import-extcommunity
q
int s1/0/0
ip binding vpn-instance michael
ip add 83.1.1.3 24
ospf en 109 a 0
ospf network-type p2p
q
ospf 109 vpn-instance michael
a 0
q
import-route bgp
bgp 100
ipv4-family vpn-instance michael
import-route ospf 109
q
ipv4-family vpnv4
peer 11.1.1.1 enable
# R1
bgp 100
ipv4-family vpnv4
peer 33.1.1.1 enable
# R4
ospf 109
domain-id 1
# R3
ospf 109
domain-id 1
# 查看
# R3
dis ip rou vpn-instance michael pro ospf # 此时没有ospf的路由
dis ospf 109 lsdb # 110.1.1.1的路由时三类LSA
# 关闭down bit 检测
# R3
ospf 109
vpn-instance-capability simple
# 然后再在R3上进行查看
dis ip rou vpn-instance michael pro ospf # 此时有多条ospf的路由
实验九:在R1和R4之间部署 sham-link
# R1
undo ospf 109
ospf 901 vpn-instance michael
a 0
import-route bgp
domain-id 0.0.0.1
q
ip vpn-instance michael
vpn-target 100:308 import-extcommunity
# R3
ospf 109
undo vpn-instance-capability
# R8
int g0/0/2
ip addr 108.1.1.8 24
ospf network-tyoe p2p
ospf enable 109 area 0
# R10
int g0/0/2
ip addr 108.1.1.10 24
ospf network-tyoe p2p
ospf enable 109 area 0
# 配置sham-link
# R1
int lo 6
ip binding vpn-instance michael
ip addr 11.11.11.11 32
bgp 100
ipv4-family vpn-instance michael
network 11.11.11.11 32
# R4
int lo 6
ip binding vpn-instance michael
ip addr 44.44.44.44 32
bgp 100
ipv4-family vpn-instance michael
network 44.44.44.44 32
# 查看是否通信,然后继续配置
# R4
dis ip rou vpn-instance michael
ping -vpn-instance michael -a 44.44.44.44 11.11.11.11
tracert -vpn-instance michael -a 44.44.44.44 11.11.11.11
# R4
ospf 109
area 0
sham-link 44.44.44.44 11.11.11.11
# R1
ospf 901
area 0
sham-link 11.11.11.11 44.44.44.44
# 此时sham-link与串口链路同时存在,各自独立,串口链路下的三类LSA仍然存在,如果想去掉三类LSA,则需要在R1和R4上去掉bgp进入ospf的重发布,此时只有sham-link工作
# R1
# ospf 901
# undo import-route bgp
# R4
# ospf 109
# undo import-route bgp
# 查看路由情况
# R8
int g0/0/2
ospf cost 100
# R10
int g0/0/2
ospf cost 100
dis ip rou pro ospf # 此时ospf路由都走R1方向
# R9
int lo 1
ip add 99.99.99.99 32
ospf enable 109 a 0
# R9更新路由之后再在R10上进行查看
实验十:配置路由反射器(本实验是下一个实验的预配置)
R2作为反射器
# 首先需要断开R8与R9、R10的连接
# R8
int g0/0/1
shutdown
int g0/0/2
shutdown
# 开始配置R2为路由反射器
# R1:PE
bgp 100
undo peer 33.1.1.1
undo peer 44.1.1.1
ipv4-family vpnv4
peer 22.1.1.1 enable
# R3:PE
bgp 100
undo peer 11.1.1.1
undo peer 44.1.1.1
ipv4-family vpnv4
peer 22.1.1.1 enable
# R4:PE
bgp 100
undo peer 33.1.1.1
undo peer 11.1.1.1
ipv4-family vpnv4
peer 22.1.1.1 enable
# R2:反射器
bgp 100
ipv4-family vpnv4
peer 11.1.1.1 enable
peer 11.1.1.1 reflect-client
peer 33.1.1.1 enable
peer 33.1.1.1 reflect-client
peer 44.1.1.1 enable
peer 44.1.1.1 reflect-client
undo policy vpn-target # 放行路由
# 查看路由
# R2
dis bgp vpnv4 all rou
实验十一:使用VRF-LITE将用户接入MPLS VPN(hub-spoke)
实验内容
R10与R1 建立两个OSPF邻居关系
R10上不做vrf,R1做两个vrf实例
构建一个hub-spoke结构的IP路由网络
数据转发路径为 site-a(R8) -- hub(R10) -- site-b(R9)
R1上两个vrf:一个负责收取来自spoke站点的路由,传递给hub;一个负责收取来自hub的路由,传递给spoke。
重点
在中心场点OSPF下发默认路由
中心场点PE加参数,将OSPF默认路由导入VPNv4
分支站点PE通过OSPF将BGP默认路由通告给CE
# R1
ospf 901
import-route bgp
a 0
undo sham-link 11.11.11.11 44.44.44.44
# R4
ospf 109
import-route bgp
a 0
undo sham-link 44.44.44.44 11.11.11.11
# 此时R8(88.1.1.1)与R9(99.1.1.1)上没有对方的路由,但是R10(110.1.1.1)的路由再R8与R9上都有。即两个spoke站点(R8/9)不能互通,但是可与中心站点(R10)互通
# R10:为了让R8与R9能够通信(但是数据必须经过R10),需要下放一条默认路由
undo ospf 901
ospf 109
default-route-advertise always
# R1:查看下发的默认路由:dis ip rou vpn-instance micheal
# 此时OSPF下放的默认路由,但是此条路由无法引入BGP
# R1
bgp 100
ipv4-family vpn-instance michael
undo network 11.11.11.11 32
default-route imported # 将ospf的默认路由也引入进来
dis bgp vpnv4 all rou
# R3:查看路由,但是此时bgp的默认路由无法进行ospf
dis bgp vpnv4 all rou
ospf 109
default-route-advertise
# R9/8:此时R9/8上有默认路由,但是能给对方发数据,无法收到对方的回应数据
dis ip rou
# R4
ospf 109
default-route-advertise
# R9/8:此时能够进行通信
# R9
ping -a 99.1.1.1 88.1.1.1
tracert -a 99.1.1.1 88.1.1.1 # 10.1.49.4-->10.1.34.3-->10.1.23.2-->10.1.12.2-->83.1.1.3-->83.1.1.8
实验十二:BGP接入MPLS VPN
规划AS号码 ,假设使用的AS不分公有私有
R10 AS1000,R8 AS1008,R9 AS1009
# 删除OSPF
# R1
undo ospf 901
# R3/4/8/9/10
undo ospf 109
# R10
int lo 0
undo ospf enable 109 area 0
int g2/0/0
undo ospf enable 109 area 0 # 目前ospf已经undo了,关于接口下的ospf使能已经失效,可以不删除
# R9
int g0/0/0
ip addr 49.1.1.9 24
undo ospf en 109 a 0
# R4
int g0/0/0
ip addr 49.1.1.4 24
undo ospf en 109 a 0
# 删除下放的默认路由和引入的路由
# R1
bgp 100
ipv4-family vpn-instance michael
undo default-route imported
undo import-route ospf 901
# R3
bgp 100
ipv4-family vpn-instance michael
undo import-route ospf 109
# R4
bgp 100
undo ipv4-family vpn-instance michael
ipv4-family vpn-instance michael
# BGP接入MPLS VPN
# CE端做正常的BGP配置
# R10
bgp 1000
peer 10.1.110.1 as-number 100
network 110.1.1.1 32
# R9
bgp 1009
peer 49.1.1.4 as-number 100
network 99.1.1.1 32
# R9
bgp 1008
peer 83.1.1.3 as-number 100
network 88.1.1.1 32
# PE端,在vrf地址族下针对CE做BGP对等体
# R1
bgp 100
ipv4-family vpn-instance michael
peer 10.1.110.10 as-number 1000
# R4
bgp 100
ipv4-family vpn-instance michael
peer 49.1.1.9 as-number 1009
# R3
bgp 100
ipv4-family vpn-instance michael
peer 83.1.1.8 as-number 1008
# 测试
# R1/4/3
ping -vpn-instance michael 10.1.110.10
dis bgp vpnv4 all rou
dis bgp vpnv4 all peer
# 查看hub点R10的路由
dis ip rou pro bgp # 可以收到来自R8和R9的两条路由88.1.1.1和99.1.1.1,但是分支站点R8/R9上只有总部路由110.1.1.1,没有分支站点之间的路由
# R10:总部针对邻居下发默认路由
bgp 100
peer 10.1.110.1 default-route-advertise
# R1:在邻居上查看相应默认路由
dis bgp vpnv4 all rou
# R8/9:查看远端的收到的下发的默认路由
dis ip rou
ping -a 88.1.1.1 99.1.1.1
tracert -a 88.1.1.1 99.1.1.1 # R8上:83.1.1.3--10.1.23.2--***--10.1.12.2--10.1.23.3--49.1.1.4--49.1.1.9
实验十三:如果不采用默认路由的方式,如何传递明细路由呢?(BGP接入MPLS VPN)
场景一:
客户使用hub-spoke架构网络,并要求传递明细路由
解决方法:
- 中心场点的PE修改eBGP防环
- 中心场点PE通过多vrf区分传出和传入的路由
- HUB--数据去往中心站点
- Spoke--数据去往分支站点
- 中心场点PE通过不同RD区分传出和传入的路由,以使得VPNv4的RR能够同时保存传出和传入的路由
- 通过RT控制传出的路由和传入的路由的更新方向
场景二:
客户所有站点使用相同AS: 针对CE设备操作,将所有AS路径上的AS号码修改为本地AS号码
解决方法:
- 完成BGP配置
- HUB点PE针对从hub收取路由的vrf实例下BGP peer allowas-in
- 针对所有站点做as-override,即将as-path中的所有AS号码替换为本地AS号码
场景三:
多宿主站点接入MPLS VPN(SoO一般配置在PE设备上)
场景四:
vrf实例下的额外路由操控策略
解决方法:
RT用于在PE设备之间控制路由的更新
vrf实例下,可以增加额外的策略,用做辅助手段来控制vrf实例的路由表(入),或者出自本vrf实例的VPNv4路由的RT
# R10
bgp 1000
undo peer 10.1.110.1 default-route-advertise
q
int s1/0/1
ip addr 10.1.111.10 24
# 1. 完成BGP配置
# R1
int g0/0/2
undo ospf en 901 a 0
undo ospf network-type
q
undo ip vpn-instance michael
ip vpn-instance HUB
route-distinguisher 100:10
q
q
ip vpn-instance SPOKE
route-distinguisher 100:20
int g2/0/0
ip binding vpn-instance HUB
ip address 10.1.110.1 24
int s1/0/1
ip binding vpn-instance SPOKE
ip address 10.1.111.1 24
q
bgp 100
ipv4-family vpn-instance HUB
peer 10.1.110.10 as-number 1000
ipv4-family vpn-instance SPOKE
peer 10.1.111.10 as-number 1000
# R10
bgp 1000
peer 10.1.111.1 as-number 100
# R3
bgp 100
ipv4-family vpn-instance michael
undo peer 83.1.1.8
peer 83.1.1.8 as-number 1000
# R4
bgp 100
ipv4-family vpn-instance michael
undo peer 49.1.1.9
peer 49.1.1.9 as-number 1000
# R8
undo bgp 1008
bgp 1000
network 88.1.1.1 32
peer 83.1.1.3 as-number 100
# R9
undo bgp 1009
bgp 1000
network 99.1.1.1 32
peer 49.1.1.4 as-number 100
# 查看路由
#R2/1
dis bgp vpnv4 all rou # 路由反射器R1上有全部路由,但R1上没有分支站点路由
# 2. 针对所有站点做as-override
# R1
ip vpn-instance HUB
vpn-target 100:308 import-extcommunity
vpn-target 100:409 import-extcommunity
q
dis bgp vpnv4 all rou # 此时有R8/9的路由,但因为bgp防环的原因,此时路由无法传递给hub
bgp 100
ipv4 vpn-instance HUB
peer 10.1.110.10 substitute-as # 将as-path中的所有AS号码替换为本地AS号码,即重写as号
# 3. HUB点PE针对从hub收取路由的vrf实例下BGP peer allowas-in
# R1
bgp 100
ipv4 vpn-instance SPOKE
peer 10.1.111.10 allow-as-loop 2
# 查看路由
# R1/2/3
dis bgp vpnv4 all rou # R3上没有R9的路由,下一步需要做RT
# R1
ip vpn-instance SPOKE
vpn-target 100:110 export-extcommunity # 此时再看R3/4,均有R8和R9的路由
# R4
ipv4-family vpn-instance michael
peer 49.1.1.9 substitute-as
# R3
ipv4-family vpn-instance michael
peer 83.1.1.8 substitute-as
# 查看路由
# R8/9
dis bgp rou # 此时能收到所有的路由
tracert -a 88.1.1.1 99.1.1.1 # 83.1.1.3-10.1.23.2-10.1.111.1-10.1.111.10-10.1.110.1-10.1.12.2-10.1.23.3-49.1.1.4-49.1.1.9
实验十四:VRF下的路由操控(上个实现的场景三)
# 配置SoO
# R3
bgp 100
ipv4-family vpn-instance michael
peer 83.1.1.8 soo 123:123