- 第一堂课--课程介绍
- BGP
- 面试与总结
- 实验
- 实验一:通过直连路由方式建立eBGP对等体
- 实验二:通过环回口方式建立eBGP对等体
- 实验三:iBGP邻居配置实验(同时查看路由黑洞)
- 实验四:使用全互联的方式解决路由黑洞
- 实验五:修改下一跳属性
- 实验六:BGP的下一跳不改变场景
- 实验七:BGP ASBR下一跳方案对比
- 实验八:多点接入的下一跳
- 实验九:部署BGP对等体组
- 实验十:部署基于对等体组的动态邻居(思科)
- 实验十一:AS欺骗
- 实验十二:移除私有AS号码
- 实验十三:路由自动聚合
- 实验十四:手动聚合,验证起源代码的继承
- 实验十五:为聚合路由设置属性
- 实验十六:验证RR环境下的iBGP路由传递
- 实验十七:理解起源者ID和Cluster-id的作用
- 实验十八:BGP联邦
- 实验十九:团体属性no-export
- 实验二十:团体属性no-export-subconfed(local-as)
- 实验二十一:团体属性no-advertise
- 实验二十二:设置自定义团体属性和MED
- 实验二十三:路由选择-比较权重值
- 实验二十四:路由选择-比较本地优先级
- 实验二十五:路由选择-起源
- 实验二十六:路由选择-as-path
- 实验二十七:路由选择-到BGP更新源IGP开销小的被优选
- 实验二十八:路由选择-开启负载均衡
- 实验二十九:产生默认路由的三种方式
- 实验三十一:as-path控制列表
- 实验三十二:应用温和重配置
- 实验三十三:出站路由过滤ORF
第一堂课--课程介绍
QCIE:思科和华为设备操作和特性一起讲的
课程包含:
- 第一堂课:BGP
- 第二堂课:DNA Center(SD-Access)(思科专属)
- 第三堂课:IPSec
- DM VPN(思科)
- DS VPN(华为)
- 第四堂课:组播Multicast
- 第五堂课:SD-WAN(思科专属)
- 第六堂课:MPLS VPN
BGP
分类
按照工作范围划分,动态路由协议,分为 IGP、EGP
- IGP:OSPF、EIGRP、ISIS
- EGP:EGP、BGP。 当然现在EGP已经完成了历史使命,BGP是目前唯一一个在网运行的EGP。
介绍
BGP:边界网关协议,主要工作在AS和AS之间,AS内部也可以运行,但通常都是在网络AS出口设备之间运行,主要功能是在AS之间交换路由信息,执行基于策略的选路。
其度量办法和IGP有本质上的不同,BGP还拥有强大的路由承载能力,能够在互联网上传递数百万条路由。
知识点
自治系统AS
由同一个技术管理机构管理、使用统一选路策略的一些路由器的集合。
自治系统内部的路由协议——IGP,自治系统之间的路由协议——EGP。
IGP和BGP的区别
IGP主要解决数据的转发,BGP主要解决路由的传递和控制
IGP,运行于AS内部的路由协议,主要有: RIP, OSPF及ISIS。IGP着重于发现和计算路由
EGP,运行于AS之间的路由协议,现通常都是指BGP。BGP着重于控制路由的传播和选择最优的路由。
AS编号,两字节,1-65535 ,其中64512-65535是私有AS号码。目前的BGP实现已经可以支持四字节的AS号码。
AS号码在设备上有两种显示方式:十进制数字、点分十进制
BGP特征
BGP通过在路由上面附加多种路由属性(路径属性),以这些属性达到对路由更新传递、路径决策方面的操控目的。灵活性,可靠性(TCP),稳定性和收敛速度可调节,BGP是增量更新的、没有周期更新(通过BGP协议传递网络信息的路径通常比较远),支持VLSM、CIDR,通过一些规则来实现路由传递的环路预防。
- BGP是外部路由协议,用来在AS之间传递路由信息
- 是一种增强的距离矢量路由协议
- 可靠的路由更新机制
- 丰富的Metric度量方法
- 从设计上避免了环路的发生
- 为路由附带属性信息
- 支持CIDR(无类别域间选路)
- 丰富的路由过滤和路由策略
邻居建立和发现
BGP使用TCP的179号端口,侦听179端口,源端口为随机的高位端口
建立邻居的基本条件:IP可达,TCP端口可达。
BGP单播建立邻居,也就意味着,大多数情况下,需要管理员手工的指定好邻居(peer,对等体)是谁。
路由更新:只发送增量路由(增加、修改、删除的路由信息),大大减少了传播路由时所占用的带宽,适用于Internet上传播大量的路由信息
BGP报文种类
运行BGP的路由器称之为BGP Speaker,它们之间将会交换五种类型的报文,其中Open,Keeplive以及Notification报文用于邻居关系的建立和维护。
前4种消息是在RFC4271中定义的,而Refresh的消息则是在RFC2918中定义的

- Marker(标记):16字节,固定为1
- Length(长度):两字节无符号整数。指定了消息的全长,包括头部
- Type(类型):1 字节,指示报文类型,如OPEN、UPDATE报文等
- 1 – OPEN
- 2 – UPDATE
- 3 – NOTIFICATION
- 4 – KEEPALIVE
- 5 – REFRESH
Open
负责和对等体建立邻居关系。
主要包括BGP版本,AS号等信息。试图建立BGP邻居关系的两个路由器在建立了TCP会话之后开始交换OPEN信息以确认能否形成邻居关系。

- Version:BGP的版本号。对于BGPv4来说,其值为4
- My Autonomous System:本地AS编号。通过比较两端的AS编号可以确定是EBGP连接还是IBGP连接
- Hold Time:在建立对等体关系时两端要协商Hold time,并保持一致。如果两端所配置的Hold time时间不同,则BGP会选择较小的值作为协商的结果。如果在这个时间内未收到对端发来的Keepalive消息,则认为BGP连接中断
- BGP Identifier:BGP路由器的Router ID,以IP地址的形式表示,用来识别BGP路由器。在VRP5.30系统中,如果没有通过命令router id进行配置,则按照如下规则进行选择:优选Loopback接口地址中最大的地址作为Router ID,如果没有Loopback接口配置了IP地址,则从其它配置了IP地址的物理接口中选择一个最大IP地址的作为Router ID
- Opt Parm Len(Optional Parameters Length):可选参数的长度。如果为0则没有可选参数
- Optional Parameters:是一个可选参数用于BGP验证或多协议扩展(Multiprotocol Extensions)等功能。每一个参数为一个(Parameter Type-Parameter Length-Parameter Value)三元组。
KeepAlive
该消息在对等体之间周期性(60s)地发送,检测TCP的连通性,用以维护连接。

KeepAlive报文主要用于对等体路由器间的运行状态以及链路的可用性确认。KeepAlive 报文的组成只包括一个BGP数据报头。 KeepAlive 消息在对等体之间的交换频率以保证对方保持定时器不超时为限。
缺省情况下,发送KeepAlive的时间间隔为60秒,Hold Time是180秒。每次从邻居处接收到KeepAlive 报文将重置Hold Time定时器,如果Hold Time定时器超时,就认为对等体Down掉。
对等体在接收到Open消息后,将发送Keepalive消息确认并保持连接的有效性。确认后,对等体间可以进行Update、Notification、Keepalive和Route-refresh消息的交换。
Update
该消息被用来在BGP对等体之间传递路由信息(更新、撤销)。

- 撤销路由部分:
- Withdrawn Routes Length :(2字节无符号整数) 不可达路由长度,表示Withdrawn Routes字段的数据长度。如果Withdrawn Routes Length字段数值为0,则表示Withdrawn Routes字段没有任何数据,在UPDATE消息中不会被显示
- Withdrawn Routes :(变长) 撤销路由。该字段包括一系列的IP地址前缀信息,以<length, prefix>的格式来表示,比如<19,198.18.160.0>表示一个
198.18.160.0 255.255.224.0的网络。
- 更新路由部分:
- Path Attribute Length :(2字节无符号整数)路由属性长度,表示Path Attribute字段的数据长度。如果Path Attribute Length数值为0,则表示Path Attribute字段没有任何数据,在UPDATE消息中不会被显示
- Path Attributes :(变长) 路径属性。每个路径属性都是由三元组所组成:<attribute type, attribute length, attribute value>
- Network Layer Reachability Information :(变长) 网络可达信息。包括一系列的IP地址前缀。格式与撤消路由字段一样<length, prefix>。
最小UPDATE消息的长度为23个字节(19字节的报文头+2字节的撤消路由长度+2字节的路径属性长度)。这样的UPDATE消息被称之为End-of-RIB,用于BGP GR。
- 一条UPDATE消息可以发布多条具有相同路由属性的可达路由,这些路由可共享一组路由属性。所有包含在一个给定的Update消息里的路由属性适用于该Update消息中的NLRI(网络层可达性信息)字段里的所有目的地(用IP前缀表示)。
- 一条UPDATE消息可以撤销多条不可达路由。每一个路由通过目的地(用IP前缀表示),清楚的定义了BGP Speaker之间先前通告过的路由。
- 一条UPDATE消息可以只用于撤销路由,这样就不需要包括路径属性或者网络可达信息。相反,也可以只用于通告可达路由,就不需要携带Withdrawn Routes了。不可即更新又撤销路由。
Notification
当BGP Speaker检测到错误的时候,就发送该消息给对等体(报错,用于拆除连接,释放资源)。
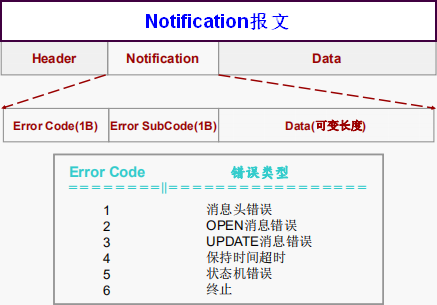
- Errorcode:错误码。1字节长的字段。每个不同的错误都使用唯一的代码表示,而每一个错误码都可以拥有一个或多个错误子码,但如果某些错误码并不存在错误子码的话,则该错误子码字段以全0表示。
- Errsubcode:错误子码

Route-refresh
用来通知对等体自己支持路由刷新能力。对等体一端不支持路由刷新的能力,如果强制刷新,则会重新建立邻居

- AFI(Address Family Identifier):地址族标识符(2字节)
- Res.(Reserved field):保留区域(1字节),发送方应将其设置为0,接收方应当忽略该区域的信息
- SAFI(Subsequent Address Family Identifier):子地址族标识符(8字节)。
在所有BGP路由器使能Route-refresh能力的情况下,如果BGP的入口路由策略发生了变化,本地BGP路由器会向对等体发布Route-refresh消息,收到此消息的对等体会将其路由信息重新发给本地BGP路由器。这样,可以在不中断BGP连接的情况下,对BGP路由表进行动态刷新,并应用新的路由策略。
消息的应用
- BGP使用TCP建立连接,本地监听端口为179。和TCP连接建立相同,BGP连接的建立也要经过一系列的对话和握手。TCP通过握手协商通告其端口等参数,BGP的握手协商的参数有:BGP版本、BGP连接保持时间、本地的路由器标识(Router ID)、授权信息等。这些信息都在Open消息中携带。
- BGP连接建立后,如果有路由需要发送则发送Update消息通告对端。Update消息发布路由时,还要携带此路由的路由属性,用以帮助对端BGP协议选择最优路由。
- 在本地BGP路由变化时,要通过Update消息来通知BGP对等体。
- 经过一段时间的路由信息交换后,本地BGP和对端BGP都无新路由通告,趋于稳定状态。此时要定时发送KEEPALIVE消息以保持BGP连接的有效性。对于本地BGP,如果在保持时间内,未收到任何对端发来的BGP消息,就认为此BGP连接已经中断,将断开此BGP连接,并删除所有从该对等体学来的BGP路由。
- 当本地BGP在运行中发现错误时,要发送NOTIFICATION消息通告BGP对等体
路由产生
- IGP
- 汇总,但需要有明细
- network既能激活接口又能产生接口所在网络的路由
- 重分布
- BGP
- network(精确的将一条IGP路由放入BGP table)
- 原子聚合(汇总,需要至少一条明细的存在)
- 路由注入(路由拆分,需要聚合路由的存在)
- 重分布
注意,BGP的条目,下一跳IP地址在IGP路由表中可查询到,并且可达(但其实BGP并不检测到底能不能通),该条目才能被BGP的选路算法优选(路由计算)
BGP报文TTL值
eBGP报文的TTL 默认是1
iBGP报文的TTL 默认是255
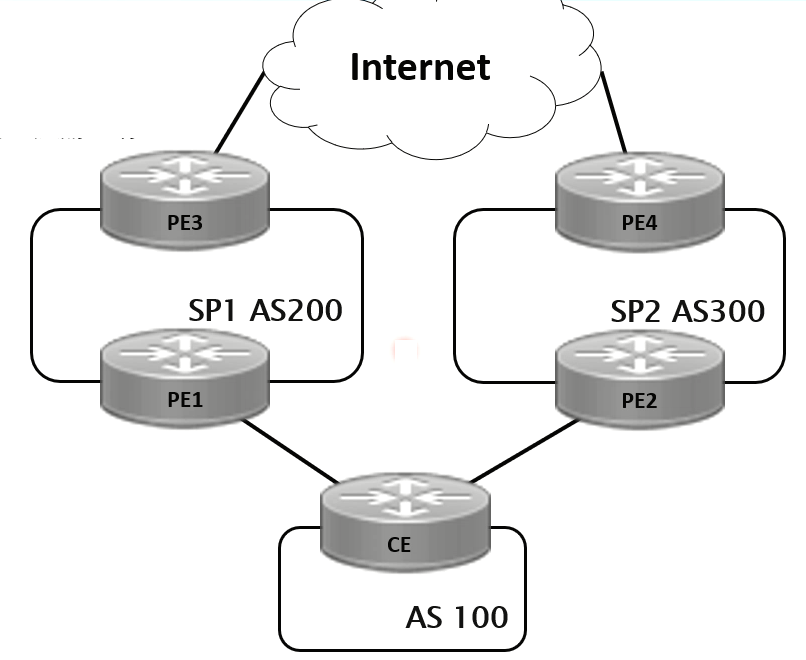
路由黑洞
简单的说,它会默默的将数据包丢弃,使所有数据包有去无回,主要原因是没有相应的路由,本质是IP逐跳转发导致数据包丢失
路由黑洞
在本课程拓扑中,R1和R4建立iBGP对等体,R4上ping -a 4.4.4.4 1.1.1.1不通
【R4上bgp路由表中1.1.1.1的优选路由的下一跳为11.1.1.1,但是show ip cef的结果为1.1.1.1的下一跳为10.1.34.3,出口为g0/0/2,主要原因是OSPF选择路由的方式是基于带宽的,导致R4最终路由选择下一跳为R3,但是R3上没有11.1.1.1的路由】
解决方案
- 将BGP引入IGP中
- 使用情景:AS之间通过BGP传递少量经过聚合的前缀。如果是把来自IBGP的路由引入到IGP,则需要开关。
iBGP对等体之间的转发路径上出现路由黑洞,可以使用全互联、MPLS、路由反射器RR解决
- 使用情景:AS之间通过BGP传递少量经过聚合的前缀。如果是把来自IBGP的路由引入到IGP,则需要开关。
- 全互联
- 使用情景:适用于对等体数量较少的网络
- MPLS
- 更加适用于新的网络
- 路由反射器RR
- 本质是一种针对与iBGP全互联的优化方案
iBGP的水平分割规则:来自iBGP对等体的路由,不能传递给iBGP对等体 。路由反射器是专门破坏这个规则的
- 本质是一种针对与iBGP全互联的优化方案
BGP的下一跳规则
- BGP speaker在向外更新路由的时候,如果对方是iBGP对等体,默认不修改下一跳属性
- BGP speaker在向外更新路由的时候,如果对方是eBGP对等体,默认将会修改下一跳属性为自身更新源地址
修正下一跳,解决下一跳不可达的问题
操作系统预定义了两个BGP下一跳属性的修改行为: 下一跳自我【通常,会在ASBR上针对内部的iBGP对等体应用下一跳自我】下一跳不改变【多用于域间 MPLS VPN】
eBGP防环
eBGP防环靠自治系统路径列表属性。BGP会在将路由传递给eBGP邻居的时候,在列表的最前面加上自身的AS号码,当收到一个来自eBGP邻居的路由时,将会检测这个属性,如果包含本地AS号码,则拒收该路径上来的路由。
工作机制
BGP路由传递
- BGP通过单播方式构建TCP会话以建立BGP邻居,并保持该会话
- 建立连接的两台设备互为对等体,为了确保两边设备的BGP进程都正在运行,要求两端的设备通过该TCP连接周期性的发送KeepAlive消息,以向对端确认自己还存活
- BGP通过定义策略或者规则来穿越AS,所以BGP是as-by-as的而非IGP的基于路由器
BGP可靠的路由更新
- 传输协议:TCP,端口号179
- 无需周期性更新
- 路由更新:只发送增量路由(增加、修改、删除的路由信息),大大减少了传播路由时所占用的带宽,适用于在Internet上传播大量的路由信息
- 周期性(60s)发送keepAlive报文检测TCP的连通性
TCP路由传递,基于高层的路由服务,不必依赖IP支持。增量更新减少资源占用,keepalive保持TCP会话
BGP状态机
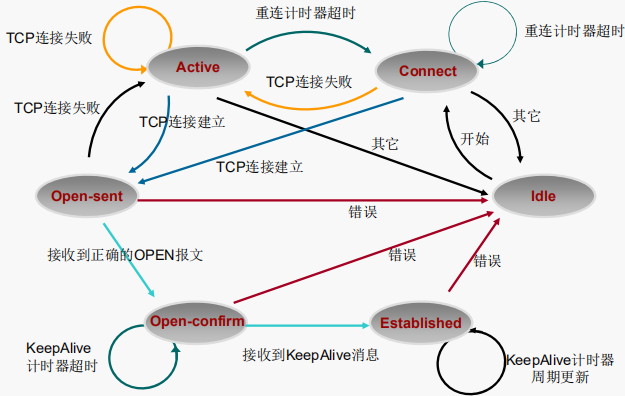
- Idle:
BGP连接的第一个状态。在空闲状态,BGP在等待一个启动事件。启动事件出现以后,BGP初始化资源,复位连接重试计时器(Connect-Retry),- 发起一条TCP连接,同时转入Connect(连接)状态。
- Connect:
在此状态,BGP发起第一个TCP连接,- 如果连接重试计时器超时,就重新发起TCP连接,并继续保持在Connect状态,
- 如果TCP连接成功,就转入OpenSent状态,
- 如果TCP连接失败,就转入Active状态。
- Active:
在此状态,BGP总是在试图建立TCP连接,- 如果连接重试计时器(Connect-Retry)超时,就退回到Connect状态,
- 如果TCP连接成功,就转入OpenSent状态,
- 如果TCP连接失败,就继续保持在Active状态,并继续发起TCP连接。
- OpenSent:
在此状态,TCP连接已经建立,BGP也已经发送了第一个Open报文,剩下的工作,BGP就在等待其对等体发送Open报文。并对收到的Open报文进行正确性检查,- 如果有错误,系统就会发送一条出错通知消息并退回到Idle状态,
- 如果没有错误,BGP就开始发送Keepalive报文,并复位Keepalive计时器,开始计时。同时转入OpenConfirm状态。
- OpenConfirm:
在OpenConfirm状态,BGP等待一个Keepalive报文,同时复位保持计时器,- 如果收到了一个Keepalive报文,就转入Established阶段,BGP邻居关系就建立起来了。
- Established:
在Established状态,BGP邻居关系已经建立,这时,BGP将和它的邻居们交换Update报文,同时复位保持计时器。
除Idle状态以外的其它五个状态出现任何Error的时候,BGP状态机就会退回到Idle状态。
在BGP对等体建立的过程中,通常可见的三个状态是:Idle、Active、Established。Idle状态下,BGP拒绝任何进入的连接请求,是BGP初始状态。
Active状态下,BGP将尝试进行TCP连接的建立,是BGP的中间状态。
Established状态下,BGP对等体间可以交换Update报文、Route-refresh报文、Keepalive报文和Notification报文。
BGP对等体双方的状态必须都为Established,BGP邻居关系才能成立,双方通过Update报文交换路由信息
BGP的数据库
- IP路由表 (IP-RIB):全局路由信息库,包括所有IP路由信息
dis ip rou - 邻居表:对等体邻居清单列表
dis bgp peer - BGP路由表 (Loc-RIB):BGP路由信息库,包括本地BGP Speaker选择的路由信息
dis bgp rou - Adj-RIB-In:对等体宣告给本地Speaker的未处理的路由信息库
- Adj-RIB-Out:本地Speaker宣告给指定对等体的路由信息库
BGP策略引擎和路径选择
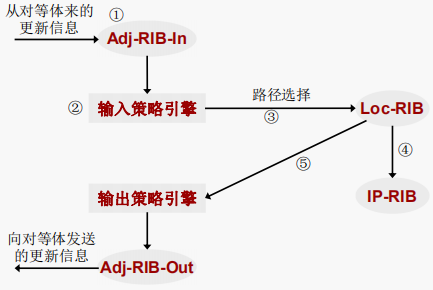
本地被优选的路由,才允许更新给对等体
主动与被动连接TCP
neighbor 11.1.1.1 transport connection-mode [active|passive] # 思科
执行peer 11.1.1.1 lister-only命令之后,则对等体不会主动发起连接,会导致已经建立的邻居会话中断,本端等待对端发起连接请求之后,重新建立邻居会话。
BGP路由(通告)传递原则
- 连接建立时,BGP Speaker只能把本身用的最优路由通告给对等体;多条路径时,BGP Speaker只选择最优路由放入路由表
- BGP Speaker从eBGP获得的路由会向它所有的BGP对等体(包括eBGP和iBGP)通告
通告给eBGP对等体时首先要保证的是AS号码不能出环,否则即使通告也会被过滤掉 - BGP Speaker从iBGP获得的路由不会通告给它的iBGP邻居
- BGP Speaker从iBGP获得的路由是否通告给它的eBGP对等体要依IGP和BGP同步的情况来
决定
【BGP与IGP同步的概念:BGP Speaker不将从iBGP对等体获得的路由信息通告给它的eBGP对等体,除非该路由信息也能通过IGP获得】
BGP路径属性
- 下一跳:决定如何转发、路由优选的前提
- 起源代码:标识路由出身的,有优劣之分
- as-path(AS路径):eBGP防环的关键、路由的传递路径
以上三个属性,是BGP的公认强制属性,即所有的BGP前缀,必须拥有这三个属性
AS号码欺骗
- 对等体采用伪AS号与本端建立连接,常用于运营商修改网络部署的场景,即用于网络变更、DM VPN(动态VPN)部署等
- 如果本端使用伪AS号码与对端建立eBGP邻居,那么发送给邻居的AS_Path列表就只携带伪AS号码(华为,即华为只有完全欺骗模式)
# 思科
neighbor 55.1.1.1 local-as 65535 # 欺骗邻居,伪装自己是 as 65535
no-prepend # 从eBGP邻居收到的路由不增加虚假AS号码
replace-as # 在向eBGP更新路由的时候,将本地真实AS号码替换为虚假AS号码
dual-as # 接收来自eBGP对等体的连接,真实AS、虚假AS均可
移除私有AS号码
- 运营商为没有公网AS号码但是又想用BGP协议的用户提供服务。通常来讲,为了保障BGP的路径决策正确,或者其它因素,应当维持AS路径列表长度。常见的做法,就是将用户的AS号码替换为SP边界的AS号码。
- 公有AS号可以直接在Internet上使用,私有AS号不能直接发布到Internet上,否则造成环路现象,因此私有AS号仅在内部路由域中使用。
- 配置命令后,如果BGP路由信息的as_path属性中只包含私有AS号,BGP就会删除这些私有AS号,然后再将路由信息发不出去。
- 以下两种情况,配置命令后,BGP不会删除私有AS号:
- 路由的as_path属性中含有对端的AS号时,这种情况下删除私有AS号可能会造成路由环路
- as_path列表中同时含有公有AS号和私有AS号,该列表表明路由已经经过公网,如果删除私有AS号,可能会造成转发错误
- 以下两种情况,配置命令后,BGP不会删除私有AS号:
路由聚合(汇总)
路由聚合是将多条路由合并的机制,它通过只向对等体发送聚合后的路由而不发送所有的具体路由的方法,减小路由表的规模,并且被聚合的路由如果发生路由震荡,也不会对网络造成影响,从而提高网络的稳定性。
聚合路由属性继承:as-path(as-set)、origin code、团体
分类
- 自动聚合
对BGP引入的子网路由进行自然掩码聚合。配置自动聚合后,生成聚合后的自然网段路由,而原引入的子网路由被抑制,不会被优选和发布给BGP邻居。
仅对**重分布的路由**(import-route)生效(对network的路由无效),组件路由抑制生成,但没有产生指向null0的聚合路由 - 手动聚合
对BGP本地路由进行聚合。通常情况下,手动聚合的优先级高于自动聚合的优先级。
可以对本地的任何路由进行聚合,包活import、network等等
如果聚合路由中所包含的具体路由各Origin属性不相同,那么聚合路由的Origin属性按照优先级IGP>EGP>incomplete为准。聚合路由会携带原来所有具体路由中的团体属性。
默认情况下,组件路由(聚合路由)和明细路由一起发布,即不抑制明细- 不带AS_SET的路由聚合
as_path属性按一定次序记录了某条路由从本地到目的地址所要经过的所有AS编号。
SET和SEQUENCE的不同之处在于,SET选项下的AS列表通常用于路由聚合,将来自不同AS的AS号无序排列在AS列表里;而SEQUENCE选项下的AS列表是有序的,每经过一个AS都会将其AS号排列在列表的前端。
默认情况下,聚合路由会由本设备产生,并且不携带原本的任何AS号码,即AS-Path属性为空 - 带AS_SET的路由聚合
用于预防环路,不加as-set参数,将存在路由传递环路的可能。
as-path这个属性,在BGP中有四种存在格式:- AS_SET: 一个去往特定目的地所经路径上的无序AS号列表,用于聚合路由,在新的聚合路由上,将包含原本的所有组件路由的as号码,
包含在UPDATE消息里 - AS_SEQENCE: 一个有序的AS号列表,
包含在UPDATE消息里 - AS_CONFED_SEQUENCE:一个去往特定目的地所经路径上的有序AS 号列表,其用法与AS_SEQUENCE完全一样,区别在于该列表中的AS号属于本地联邦中的AS,
包含在UPDATE消息中,只能在本地联盟内传递 - AS_CONFED_SET:一个去往特定目的地所经路径上的无序AS号列表,去用方法与AS_SET完全一样,区别在于列表中的AS号属于本地联邦中的AS,
包含在UPDATE消息中,只能在本地联盟内传递
- AS_SET: 一个去往特定目的地所经路径上的无序AS号列表,用于聚合路由,在新的聚合路由上,将包含原本的所有组件路由的as号码,
- 不带AS_SET的路由聚合
过滤策略
关键字suppress-policy能产生聚合路由,但抑制指定路由的通告。可以用route-policy的if-match字句有选择的抑制一些具体路由,其他具体路由仍被通告。
原子聚合和聚合者
- 原子聚合是公认自决属性,用来通知下游的邻居丢失了特定路由的路径信息。当更精确的路由被汇聚为不够精确的路由的时候会引起信息丢失,原子聚合属性只是UPDATE数据包中设置的一个标志位,它提醒下游路由器在聚合的过程中丢失了一些路径信息。当原子聚合属性被设置后,下游路由器不能删除这个属性或是发送到目的网段的更精确路由。
- 聚合者属性是一个可选过渡属性,—般针对某个NLRI与原子聚合属性同时使用。聚合者属性包含了会聚路由的SPEAKER的相关信息,属性中包含了创建聚合路由并且标记原子聚合属性的路由器的BGP ID和自治系统号码。这些信息指明了非精确会聚合路由的来源,可以用来找到更精确路由的源头。
四大类属性
- 公认强制/周知:所有BGP必须能理解,所有前缀必须带
- 公认自决/自选:所有BGP必须能理解,但可以不携带
- 可选可传递:不识别也可以传递属性
- 可选非可传递:不识别则不可以传递属性
BGP反射和联盟
由于BGP的通告原则,导致iBGP对等体都必须建立iBGP邻居,形成iBGP全互连,而iBGP全互连确实可以很好的解决BGP通告原则所引起的问题,但同时也带来另一个问题,BGP Speaker必须维护更多的iBGP会话数量,因此BGP引入反射和联盟。
iBGP路由传递规则:只能传一跳。AS内部的iBGP全互联用于解决路由传递问题,但同时也给iBGP的扩展带来了很大问题(对等体数量众多导致资源消耗;配置量随着大量增长)。BGP路由反射器(RR)以及BGP联邦(联盟)作为这些问题的扩展技术解决方案,重点在于解决路由传递。
BGP是怎样防止环路的?
eBGP:通过AS-Path属性,丢弃从eBGP对等体接收到的在AS-Path属
性里包含自身AS号的任何更新信息iBGP:BGP路由器不会将任何从iBGP对等体接收到的更新信息传给其
它iBGP对等体
路由反射 (RFC2796)
主动式解决方案【放宽了iBGP路由传递规则】
降低对指定路由器iBGP路由通告机制的限制,允许将从iBGP对等体接收到的更新信息传给某些
iBGP对等体
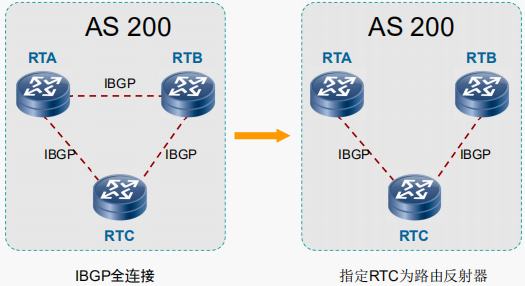
反射传递,路由反射器在反射iBGP路由的情况下,是不能修改属性的(但会增加属性,用于防环)
三种角色和关系
- 路由反射器 (Route Reflector) :被放宽了传递规则的设备,允许将来自iBGP对等体的路由传递给iBGP对等体
- 客户机 (Client):默认情况下,反射器将在反射器客户端之间反射传递路由,因此客户端之间不需要BGP对等体
- 非客户机 (Non-Client) :非客户端需要与RR以及其它非客户端建立全互联的iBGP对等体
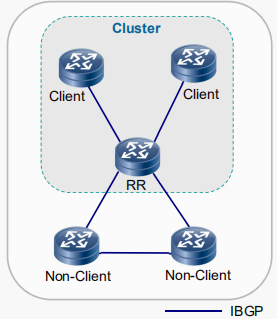
- Client只需维护与RR之间的IBGP会话
- RR与RR之间需要建立IBGP的全互连
- Non-Client与Non-Client之间需要建立IBGP全互连
- RR与Non-Client之间需要建立IBGP全互连
【总结】:RR与RR、RR和非客户机、RR和客户机、非客户机和非客户机全互连,客户机与客户机之间不能互连
路由反射宣告原则
- 当RR收到BGP对等体发来的路由,首先使用BGP选路策略来选择最佳路由,RR在发布学习到的路由信息时,按照RFC2789中的规则发布路由
- 从非客户机iBGP对等体Non-Client学到的路由,发布给此RR的所有客户机Client
- 从客户机client学到的路由,发布给此RR的所有非客户机和客户机(发起此路由的客户机除外)
- 从eBGP对等体学到的路由,发布给所有的非客户机和客户机
【总结】:非客户机-->所有客户机,客户机和eBGP-->所有客户机和非客户机
路由反射簇 (Cluster)
在AS内部,仅仅部署一台RR是不正确的,因为这样的话,RR可能会成为单点故障点
当一个AS内存在多台RR为Client提供冗余时,RR间的路由更新很有可能会形成环路,为
防止该现象,引入了Cluster的概念。
通过4字节的Cluster_ID来标识Cluster,通常会使用Loopback地址作为Cluster_ID,一个Cluster里可以包括一个或多个RR,一个Client可以同时属于多个Cluster。
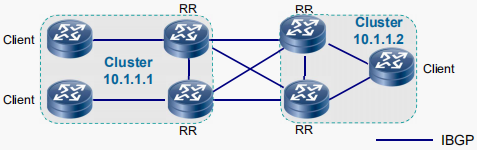
Cluster-id:簇列表成员,用于标识RR,每台RR在反射路由时会将自身的簇ID放入该路由属性的簇列表
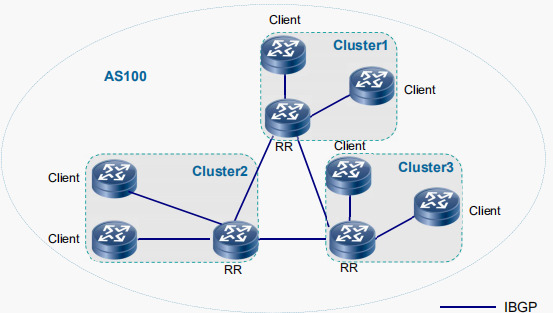
AS内多个簇
层次化路由反射
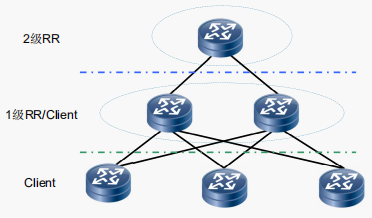
路由反射减少了域中iBGP会话的总数。然而,因为RR相互之间必须全互连,在大型网络中,存在一种可能性,即RR之间仍然需要大量的iBGP会话。为了进一步减少会话数量,引入层次化路由反射。层次化路由反射的层数按照需要逐步加深,但通常现网中两层或者三层就足够了。
路由反射环路防止机制
当一条路由第一次被反射时,反射器会将其router-id收集成Originator-ID,如果该路由由于配置适当或者其它反射簇或其它不明原因被反射到路由的起源者,则该设备将对比Originator-ID和本地router-id,以此拒收【这里说的router-id不一定是始发路由器的】
- Originator_ID【BGP路径属性,可选非可传递属性】
- Originator ID属性用于防止在反射器和客户机/非客户机之间产生环路
- Originator_ID属性长4字节,可选非过渡属性,属性类型为9 ,是由路由反射器(RR)产生的,携带了本地AS内部路由发起者的Router ID
- 当一条路由第一次被RR反射的时候,RR将Originator_ID属性加入到这条路由,标识这条路由的始发路由器。如果一条路由中已经存在了Originator_ID属性,则RR将不会创建新的Originator_ID
- 当其它BGP Speaker接收到这条路由的时候,将比较收到的Originator_ID和本地的Router ID,如果两个ID相同,BGP Speaker会忽略掉这条路由,不做处理
- Cluster_List【BGP路径属性,可选非可传递属性】
- Cluster_List属性用于防止AS内部的环路【RR之间防止环路】
- Cluster_List是可选非过渡属性,属性类型编码为10
- Cluster_List由一系列的Cluster_ID组成,描述了一条路由所经过的反射器路径,这和描述路由经过的As路径的AS_Path属性有相似之处,Cluster_List由路由反射器产生
- 当RR在它的客户机之间或客户机与非客户机之间反射路由时,RR会把本地Cluster_ID添加到Cluster_List的前面。如果Cluster_List为空,RR就创建一个
- 当RR接收到一条更新路由时,RR会检查Cluster_List。如果Cluster_List中已经有本地Cluster_ID,丢弃该路由;如果没有本地Cluster_ID,将其加入Cluster_List,然后反射该更新路由
联邦 (RFC3065)
被动式解决方案【将大的AS分成若干小的AS,而小AS之间建立eBGP对等体关系】
将自治系统划分为多个子自治系统,子自治系统之间使用eBGP,子自治系统内部要求iBGP全互联
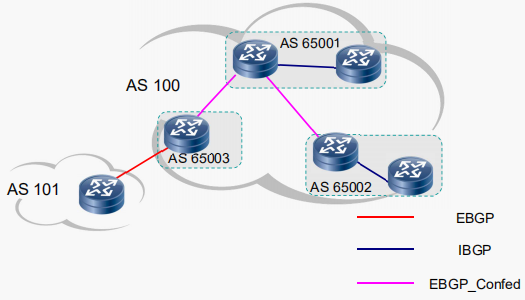
联邦不流行的原因:配置复杂、拓扑不清晰、排错不便、割接风险较大【工程师嫌麻烦】
BGP联邦到底怎么麻烦的呢?
先说自治系统:子自治系统、联邦自治系统
再说对等体关系:子AS iBGP(联邦内部iBGP)、子AS之间的eBGP(联邦内部eBGP),联邦外部eBGP(真实eBGP)
联邦内部的eBGP路由传递过程中,一方面遵循iBGP默认规则,另一方面又遵循eBGP默认规则
联邦内部eBGP传递路由时,NH、MED、Local-preference等被保留,但as-path被修改
联邦AS之间传递的联盟内eBGP路由下一跳不改变,意味着,在整个联邦内部,最好是部署一个IGP,并且保证所有设备的更新源互相可达。
当然,这些对于联邦外部eBGP对等体来说,都是不可见的。即当路由传递出联邦时,子AS的as-path是不携带的。联邦内部子AS内部的iBGP中也可以部署RR。联邦内部可以不使用相同的IGP,但仍然需要保证下一跳可达性。
联邦内AS_Path变化
- 联邦内的eBGP会话:子AS号被添加到as-path中的as-confed-sequence前面
- 联盟内的iBGP会话:不修改as-path
- 真实eBGP会话:子AS号从as-path中清除,联邦as号被添加到as-path前面
联盟与反射的比较
| 参考因素 | 比较 |
|---|---|
| 多层次 | 两种方法都支持多层次来进一步增强扩展性。路由反射器支持多级路由反射结构;联盟允许在成员AS内部使用路由反射 |
| 策略控制 | 两者都提供路由选择策略控制,不过联盟可以提供更大的灵活性 |
| 常规iBGP迁移的复杂性 | 路由反射的迁移复杂性非常低,因为总体网络配置几乎很少发生改变;从iBGP到联盟的迁移需要对配置和网络架构做很大的改变 |
| 能力支持 | 在路由反射的架构中,只需要路由反射器支持路由反射能力即可,但是在新的分簇设计中,客户端必须支持反射器属性;联盟内的所有路由器必须支持联盟配置能力,因为所有路由器需要支持联盟AS-PATH属性 |
| IGP扩展 | 路由反射在AS内需要单一的IGP,而联盟支持单一或者分开的IGP,这是联盟比路由反射所具有的最明显的优势。如果IGP达到了其扩展性限制,或者因为范围太大而难于处理管理任务,可以使用联盟来减小IGP路由表的大小 |
| 部署经验 | 由于更多的服务提供商已经部署了路由反射而非联盟,因此从路由反射中已经获得更多的经验 |
| AS合并 | 实际上AS合并和iBGP扩展性是无关的,但在这里讨论是因为它是联盟的特点之一。一个AS可以和一个已存在的联盟合并,这是通过把新的AS作为联盟的一个子AS对待来完成的 |
BGP路径属性
BGP路由拥有丰富的路径属性,用于对BGP路由进行更加详细的描述(除x.x.x.x/x之外)。因此BGP在执行路由操控和路径选择时,亦将拥有更多的筛选条件。
分类
公认必遵Well-known mondatory(周知强制)
所有BGP路由器都可以识别,且必须存在于Update消息中。如果缺少这种属性,路由信息就会出错。
- Origin:起源
一般的,具体的实现按如下方式决定一条路由的Origin属性- 某条路由是直接而具体的注入到BGP路由表中的,则origin属性为IGP(i)
- 通过network命令注入BGP的路由
- 通过EGP(RFC904)学到的路由,则origin属性为EGP(e)
- 其他情形下,Origin属性都为Incomplete(?)
- 通过import命令注入BGP的路由
- Origin属性值默认情况下不被任何路由器修改
- 某条路由是直接而具体的注入到BGP路由表中的,则origin属性为IGP(i)
- AS_Path:AS路径
描述到达目标网络所要经过的AS号序列。最重要的作用是防环,如果BGP Speaker发现自己的AS号位于接收自外部对等体的路由,则忽略该路由。仅当update消息被发送给其他的AS时,BGP 路由器才会将其AS号追加在AS_PATH中。这句话也隐含了另一个意思,那就是如果要修改AS_PATH属性,则必须在AS边界路由器上执行策略。有四种类型的AS_PATH:AS_SET、AS_SEQENCE、AS_CONFED_SEQUENCE、AS_CONFED_SET
了解eBGP防环规则的修改以及应用场景
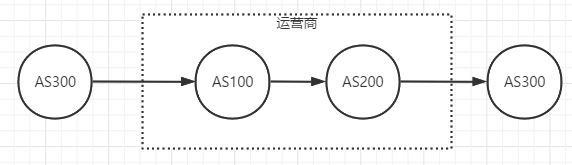
Hub-spoke架构网络
使用DM VPN模块
使用相同的AS,中间点配置成路由反射器
客户路由通过SP(运营商)更新
- overraid,覆写,即左边AS300的路由传到AS200时,其属性as-path修改为200,然后在传递给右边的AS300(应用于MPLS VPN)
- 允许接收相同AS的路由,可以设置次数,即右边的AS300可以接收左边AS300的路由
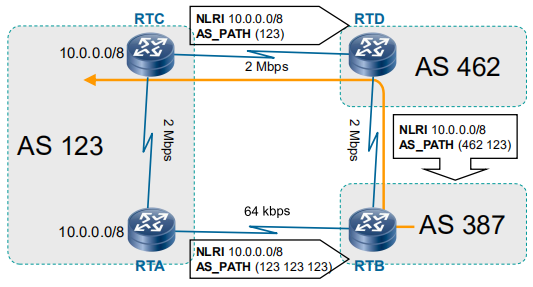
可以通过加长as_path的列表长度,从而影响路径选择。例如:从RTA向RTB更新时增加as-path长度,则使得路由选择2M链路,而不是64K的
3. Next_Hop:下一跳
- BGP Speaker在向eBGP对等体发布某条路由时,会把该路由信息的下一跳属性设置为本地与对端建立BGP邻居关系的接口地址。
- BGP Speaker将本地始发路由发布给iBGP对等体时,会把该路由信息的下一跳属性设置为本地与对端建立BGP邻居关系的接口地址。
- BGP Speaker在向iBGP对等体发布从eBGP对等体学来的路由时,并不改变该路由信息的下一跳属性
【总结】:传给iBGP对等体时默认不修改,传给eBGP对等体时默认修改,但这两个默认行为都是可以修改的。一般会在ASBR对内部对等体设置下一跳自我,eBGP对等体之间的下一条不改变一般用于域间MPLS VPN
公认任意Well-known discretionary(周知可选)
所有BGP路由器都可以识别,但不要求必须存在于Update消息中,可以根据具体情况来决定是否添加到Update消息中
- Local_Pref:本地优先级
告诉AS中的路由器,哪条路径是离开AS的首选路径。优先级属性用来影响iBGP邻居,告诉自己的iBGP邻居如何离开本AS,只能在本AS内传递(iBGP对等体或者联邦内部),不能传给EBGP邻居。默认值为100,越大越好。
MED控制流量怎样进入AS,而本地优先级则控制流量怎样流出AS;路由器优选Local-preference值大的路由控制出流量,优选MED值小的路由控制入流量。 - Atomic_Aggregate:原子聚合
有时BGP发布者会收到两条重叠的路由,其中一条路由包含的地址是另一条路由的子集。一般情况下BGP发布者会优选更精细的路由(前者),但是在对外发布时,如果它选择发布更粗略的那条路由(后者),这时需要附加上ATOMIC-AGGREGATE属性,以知会对等体。它实际上是一种警告,因为发布更粗略的路由意味着更精细的路由信息在发布过程中丢失了。在进行路由聚合时,对于聚合的路由信息会添加ATOMIC-AGGREGATE属性。
可选可传递Optional transitive(过渡)
BGP路由器可以选择是否在Update消息中携带这种属性。接收的路由器如果不识别这种属性,可以转发给邻居路由器,邻居路由器可能会识别并使用到这种属性。
- Aggregator:聚合者
聚合时也会自动出现该属性。它包括发动聚合路由器的AS号码还有它的router-id,从而提供了执行聚合的地点信息。Atomic-aggregate属性指示出现了路径信息的丢失而aggregator属性指示聚合路由出现在哪里。 - Community:团体
团体是一组有相同性质的目的地址路由。目的就是将路由信息编组,通过组的标识决定路由传递
的策略。它被一组共享相同特性的前缀所定义,多个社团可以应用到一条前缀上。
团体属性是BGP的私有属性,在BGP对等体之间传播,且不受AS限制。利用团体属性可以使AS中的一组BGP设备共享相同的策略,从而简化路由策略的应用和降低维护管理难度。
BGP设备可以在发布路由时(或者针对邻居更新以及收取时、或者引入路由时),新增或者改变路由的团体属性。
团体属性是在BGP中一种给路由条目打上标记,用于确保路由过滤和选择的连续性,BGP路由器可以过滤进出路由更新或者优选某些路由。
默认不传递给对等体,要针对邻居做传递,即传递团体属性需要配置命令peer 22.1.1.1 advertise-community
Community属性有4个字节(0x00000000—0xFFFFFFFF),RFC1997规定前两个字节代表AS号码,后两个字节是管理上定义的标识符。格式为AA:NN。- 团体属性有以下3种类型:保留的团体属性、公认的团体属性、私有团体属性
- 保留团体属性:
0x00000000—0x0000FFFF、0xFFFF0000—0xFFFFFFFF - 公认团体属性:
NO_EXPORT (0xFFFFFF01)、NO_ADVERTISE (0xFFFFFF02) 、NO_EXPORT_SUBCONFED (0xFFFFFF03)
当收到这些带有团体属性的前缀时,对等体会自动根据预定义(操作已经定义好了)的社团属性意义来采取操作,不需要额外的配置。公共团体属性的保留范围是(0xFFFF0000-0xFFFFFFFF)。下面是4种公共社团属性- Internet
所有属于这个团体属性的路由都有一个缺省值,可以自由地公布属于这个团体的路由。换句话说这个团体的前缀通告没有任何限制。 - No-export
有这个属性的前缀不会被通告给eBGP对等体,但是可以发送给联邦的eBGP对等体,也就是不能在联邦范围以外公布。这个团体的值为0xFFFFFF01。 - No-advertise
接收到带有此值的路由不能公布给任何对等体,包括iBGP对等体和eBGP对等体。它的值为0xFFFFFF02。 - Local-AS(华为no-export-subconfed)
有这个属性的路由条目不会被通告到本地AS之外。在联邦情况下,只有在同一个子AS中的对等体才会允许接受这些前缀。它的值为0xFFFFFF03在RFC1997中这个团体也叫做no-export-subconfed。
- Internet
- 私有社团属性(自定义团体属性):
AS(2B):Number(2B)
有网络管理员自己定义的社团属性,它的主要目的是为前缀附加管理标记,以便制定合适的策略。
通过干预携带的团体属性的路由,影响数据报文的转发,也用于路由清洗。
- 保留团体属性:
- 团体属性有以下3种类型:保留的团体属性、公认的团体属性、私有团体属性
可选非可传递Optional non-transitive(非过渡)
BGP路由器可以选择是否在Update消息中携带这种属性。在整个路由发布的路径上,如果部分路由器不能识别这种属性,可能会导致该属性无法发挥效用。因此接收的路由器如果不识别这种属性,将丢弃这种属性,不必再转发给邻居路由器
- Multi_Exit_Disc(MED):多出口分离器
区别到达同一邻居AS的多条入口链路(MED的默认值为0,越小越优先),通过eBGP发送MED值给对等体。
通告规则:1. MED属性起源于iBGP对等体,在传递给eBGP对等体时会清除MED属性;2. MED起源于eBGP对等体,在传递给iBGP对等体时携带;3. MED起源于本地,可以通告给所有对等体
例如:起源于RT1,RT1传递给RT2时携带MED值;起源于RT1,RT2在向RT3传递时不携带;起源于RT2,RT2在向RT3传递时携带。
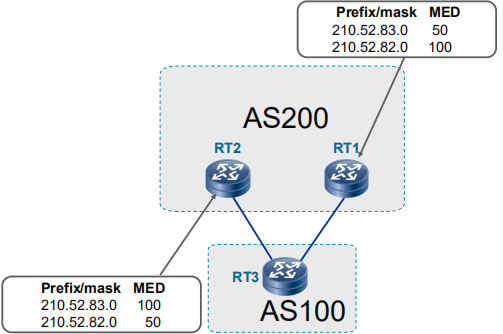
对比规则:缺省情况下,不允许比较来自不同AS邻居的路由信息的MED值。但是,可以调整这个规则。 - Originator_ID:起源ID
是本地AS中路由发起者的路由器ID。如果路由发起者在接收到路由的originator-id中发现了自己的RID,就知道产生了环路,于是忽略该路由条目,它提供在AS内的防环作用,它由第一个RR创建,并且不被后续的RR修改。
它只应在iBGP对等体那里接收到,在RR上originator-id用来替代路由选择过程中的router-ID。它应该是这些路由器的router-id;在本地AS始发路由的BGP宣告者的router-id;如果是从eBGP学到的就是最初学到那个条目的路由器(本AS内边界路由器)的router-id(它一定是本AS内路由器的router-id) - Cluster_List
是路由经过的路由反射器的簇ID(默认RR的router-ID)的一个列表,如果路由反射器接收到的路由的cluster-List中发现了自己的本地簇ID,就知道产生了环路,于是忽略该路由条目,RR从而能够分别出路由选择信息是否又环回到同一个簇。可以配置bgp cluster-id。cluter-id默认为RR自己的router-id所以默认情况下所有的RR都不在同一个簇。
BGP选路原则
前提:如果此路由的下一跳不可达,忽略此路由
华为
- Preferred-Value越大越优先
- Local-Preference越大越优先
- 本地起源评估:手动聚合>自动聚合>network>import-route
- as-path长度越短越优先【跳过本条使用命令
bestroute as-path-ignore】 - 起源代码:i>e>?
- MED值越小越优先
- eBGP>iBGP
- BGP下一跳的IGP度量越小越优先
当以上全部相同,则为等价路由,可以负载分担【AS_Path必须一致】。当负载分担时,以下原则无效: - 比较Cluster-List长度越短越优先
- Originator_ID/RouterID越小越优先(没有起源者ID的情况下才使用RouterID进行比较)
- 对等体的IP地址越小越优先
思科
- Weight权重值越大越优先
- Local-Preference越大越优先
- 本地起源评估:邻居默认>地址族默认>network>redistribute>手动聚合>自动聚合
- as-path长度越短越优先【跳过本条使用命令
bgp bestpath as-path ignore】 - Origin起源代码:i>e>?
- MED值越小越优先(是否来自同一AS)
- eBGP>iBGP
- 到达更新源的IGP metric越小越优先【跳过本条使用命令
bgp bestpath igp-metric ignore】 - load-balance i/eBGP负载均衡(默认关闭)【注意:最后一个AS号码必须一致】
- 建立时间更久的eBGP邻居【跳过本条使用命令
bgp bestpath compare-routerid】 - Originator_ID/Router_ID越小越优先
- Cluste-list越小越优先
- 对等体的IP地址越小越优先
记忆口诀:世界(world-1)恋爱(love-2)组织(origanization-3)亚洲(asia-4)办公室(office-5),纪念碑(meml-6-7-8-9)下半兽人(orc-10-11-12)
自定义路径选择过程cost-community
扩展团体属性,只能用于iBGP或者联邦内部,不能传递给eBGP
为防止环路,要求所有设备能够识别,并且保证所有设备都传递扩展团体
多宿主环境控制出站流量
可以插入在第8条选路原则之后
可以为路由附加多个cost-community,但ID不能相同
先比同一组ID的cost,如果相等则比下一组ID,越小越优先
如果设置了ID,没有设置cost,则cost=2147483647
使用bgp bestpath cost-community ignore忽略这条选路原则
使用pre-bestpath Compare before all other steps in bestpath calculation预置在所有选路原则之前
多宿主网络
BGP产生默认路由的方案
- 将来自IGP的默认路由,使用
network命令注入BGP:思科:network 0.0.0.0 mask 0.0.0.0;华为:network 0.0.0.0 0 - 允许将默认路由引入BGP。在一些场景下,已经应用了重发布命令,如果此时有需要将默认路由注入BGP,即重分布时开启默认路由的允许开关,使用如下命令:
思科:default-information origination;华为:default-route imported【需要结合重发布一起使用】 - 针对特定邻居下发默认路由:
思科:neighbor 33.1.1.1 default-originate;华为:peer 33.1.1.1 default-route-advertise
类型
- 单宿主单链路
- 单宿主多链路
- 多宿主
- 单节点多宿主
- 多节点多宿主
- 标准多宿主(需要注册公有ASN)
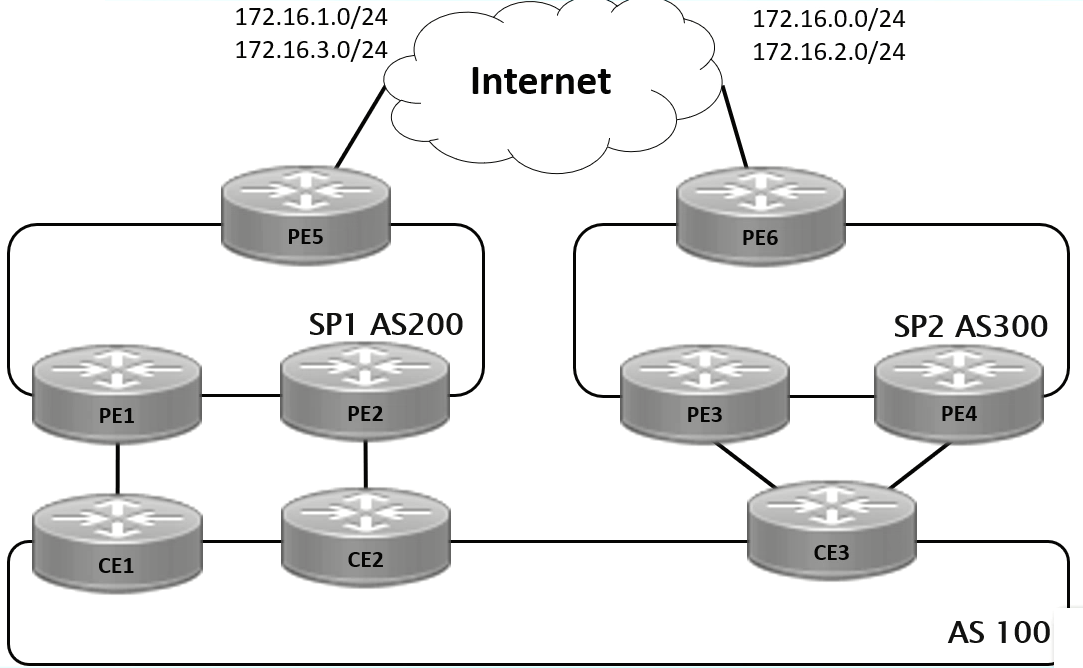
- 单节点多宿主
在SP上使用入境路由过滤:
- 私有网络信息
- 127.0.0.0/8
- 169.254.0.0/16
- 0.0.0.0/8(注意:不是0.0.0.0/0)
- 192.0.2.0/24(网络测试网络)
- D类、E类
- 本AS内部的网络信息
以上网络信息需要过滤掉,不能让其进入内部网络
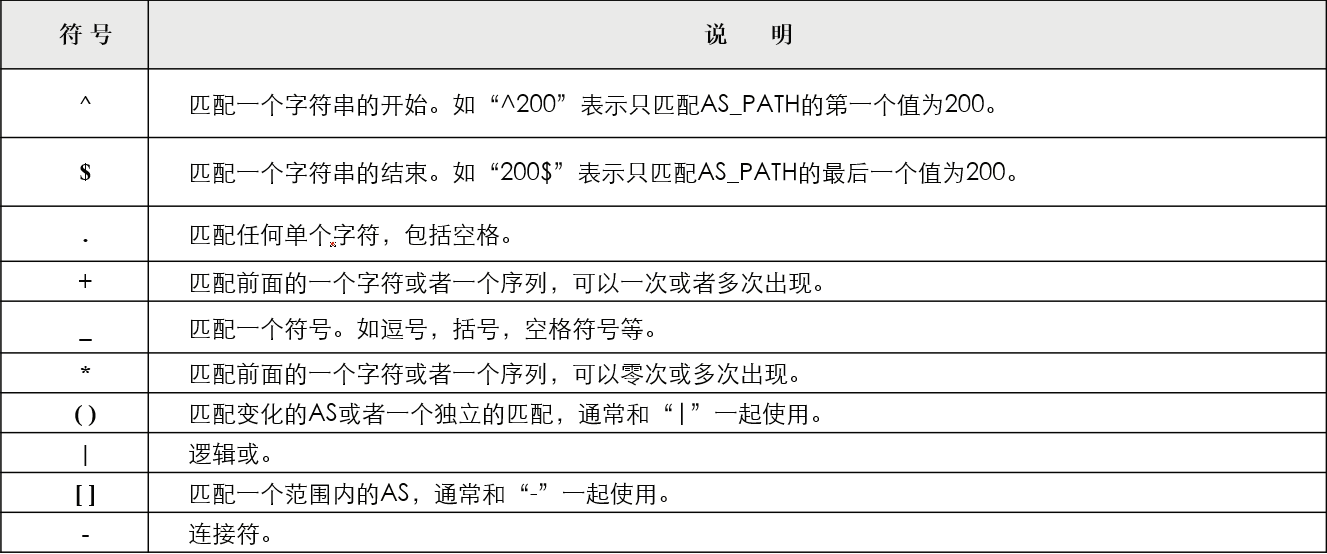
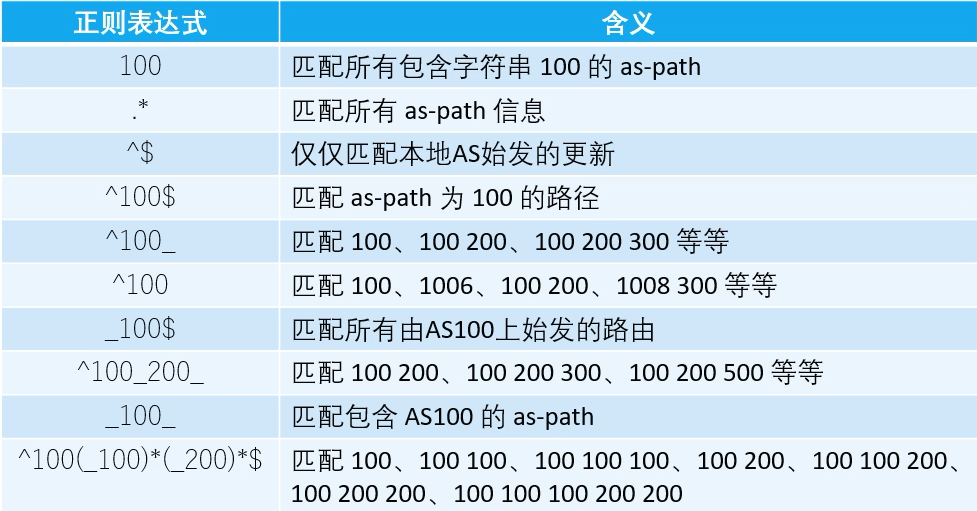
策略工具as-path access-list
用来匹配BGP前缀携带的as-path属性(隐式拒绝一切)。
由正则表达式字符串定义,每个列表的行为可以是允许或者拒绝。
as-path access-list一般由常规字符和原子字符组成。
元字符的作用是告诉正则表达式如何处理。

优化前缀更新
路由阻尼dampening(RFC2439)
减少由于不稳定路由引起的路由处理负载,防止持续的路由抖动,增强路由稳定性。
涉及术语:历史状态、惩罚、抑制门限、惩罚状态、半衰期、再使用门限、最大抑制门限等
路由翻动(route flaps)是internet不稳定的首要因素,当有效路由被重复宣告为无效、有效时就会产生路由翻动现象。
【注意:路由震荡route oscillation≠路由翻动,路由震荡属于周期性行为,而route flaps则不是】
路由阻尼是一种阻止不稳定路由传播到整个互联网络的方法,开启路由阻尼机制的路由器会为每条路由分配一个动态的特征值,用以反映该路由的稳定程度,当某条路由出现翻动时,将会给该路由分配一个惩罚值,翻动次数越多,累加的惩罚值就越大。
路由阻尼中引入了半衰期(half-life)的时间周期概念,惩罚值以一定的速率衰减到每个半衰期初值的一半,当惩罚值超出了预设的阀值(suppress limit)之后,该路由就被抑制,不再对外宣告该路由。直到该路由的惩罚值降低至另一个阀值(reuse limit)之后,才会再次对外宣告该路由。
【注意:可手工清除路由的惩罚值,这种方式对于矫正了网络中的不稳定性之后需要快速重用该路由时非常有用】
如果路由翻动的次数足够多,以至于其惩罚值的增加速度大于半衰期的减小速度,那么将会超出抑制门限。尽管路由在被抑制期间,其惩罚值仍会继续累加,但是在该路由超出了最大抑制门限(maximum suppress limit)周期之后将无法被抑制,这样就可以确保某路由在非常短的时间内翻动十几次之后,不会将惩罚值累加到一个很高的,使路由始终保持被抑制状态的值。
BGP温和重配置(keep all routes)
- 出站温和重配置不需要额外资源。通过针对特定对等体的出站更新策略来处理Adj-RIB-Loc,并创建一个新的Adj-RIB-Out
- 入站温和重配置则需要更多的内存资源,将维护所有学自远端对等体的前缀信息,即使被入站策略过滤影响
- 配置了温和重配置之后,被入站策略拒绝的前缀信息将会保存在BGP表中,被标记为recevied-only,这些前缀不参与BGP路径选择过程
路由刷新(route refresh)
在会话初始阶段协商的一种BGP能力,该特性允许BGP路由器请求远端对等体重新发送它的BGP Adj-RIB-Out,使得本地可以重新应用入站策略。
如果不支持,如果入站策略变化,将重置对等体。
出站路由过滤ORF
专门针对于前缀列表的一种优化能力。
分为发送能力、接收能力,表明具有发送或者接收前缀列表的能力。
通过向对等体通告ORF能力可以激活这一特征。表示接受从对等体来的前缀列表,并把这个前缀列表应用到针对对等体的出站方向。
通俗的讲,在本地针对邻居部署入站的前缀列表,但通过ORF能力,将该列表发送到对等体上,由对等体在路由出站时进行过滤。
BGP附加路径
提供了一种方法可以通告同一前缀的多个路径,实现了路径的多样性。即不仅仅通告best的路由,同时也通告其他路由。
在现有前缀的基础上,增加一个NLRI的path ID (路径标识符)
实现的要素:优选多个;发送能力;接受能力
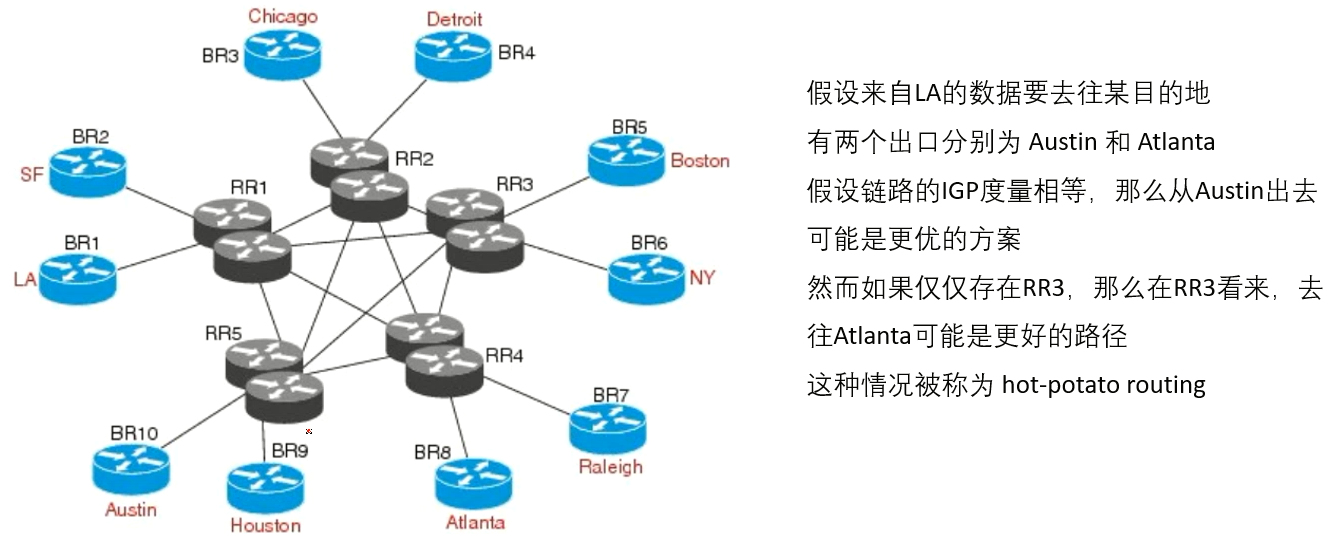
hot-potato roouting
BGP Additional Path的功能
- 通过将路径标识符添加到NLRI中的每个路径来实现的
- 路径标识符(ID)可以被视为类似于VPN中的路由标识符(RD)的东西,只是路径ID可以应用于任何地址族
- 路径ID对于对等会话是唯一的,并且是为每个网络生成的
- 除了最佳路径,Additional Path功能还允许发布更多的路径
- 附加路径功能允许发布具有相同前缀的多个路径

部署Additional Path
- 指定设备是否可以发送/接收Additional Paths,地址族下或对邻居应用【注意:这是能力】
- 指定选择标准,使用
bgp Additional-paths select命令来选择一组或者多组候选路径 - 从标记的候选路径中向邻居通告一组或多组路径,使用
neighbor advertise Additional-paths - 全部部署完,需要重新建立会话,目的在于协商能力
面试与总结
参考https://blog.csdn.net/qq_45124553/java/article/details/99694087
首先,因为BGP管理的路由信息非常庞大,而且每个as情况不一致,其必然需要丰富的属性来灵活的进行选路,从而他创造出了11条属性(一条思科私有),来完成自己的使命。
根据其主要作用,将其可大致分为5个方向:3个选路、3个防环、2个反射、2个汇总、1个团体。
3个选路(weight、local、med)
首先为什么要有三个选路属性?因为三个属性各司其职,作用均不相同。
- weight思科,华为preferred-value:
只作用于自己,不可传递给其他人;适用于一个路由器在多条路径下的选路,无视邻居属性。
思科的IOS系统默认在本地注入BGP的路由的weight=32768,即本设备产生的在本设备上是最优的;华为的默认情况下preferred-value=0。 - local:
与weight相比,最大的优点为公有且可作用于AS内其他路由器,用于本AS选择离开AS的出口路由器 - med:
与weight和local相比,最大的区别在于,可以作用于出口、影响其他AS,如果在本AS使用,和local差别不大;值得注意的是,med属性只能在两个as之间传递,不能传递给第三个as。
3个防环(origin、as_path、next_hop)
作为一个路由协议,能广泛使用的前提必然是自身不会出环,如果路由协议本身都会出环,那么该协议也就没有存在的必要。所以BGP协议利用3个公认必遵属性,牢牢守护住这一命脉。
- origin:
起源属性,标识该路由的来源方式,i表示自己产生的、E表示EGP学到的、?表示其他手段得到的(重发布);优先顺序为i>E>?。
这一属性,实为路由协议之间的较量,在自己内部传递是不会改变属性的;通过这一属性,来保证从自己发出的路由,经过其他协议处理之后,不会再流传给自己,从而防环。 - as_path:
将经过的AS统统记下来,写进货日记,最近进货的排前面,而拒绝再购买自己进货日记里已经记载的货物(一个AS的路由器拒绝接受携带自己AS号的路由);当然该属性也可以用来选路,as_path短的优先。 - next_hop:
iBGP之间传递路由不会更新next_hop(只有next_hop为0.0.0.0的情况才会更新);eBGP之间传递路由会更新next_hop为自己的更新源地址。自己为0,保证从自己发出去的不再回来
2个反射防环(originator-id、cluster-list)
因为BGP自己的原因,在ibgp之内传递路由时,不能中转;所以若想全网互通,则必须做全互联,而全互联工程量太大且复杂,所以有了反射器,使得路由可以中转。应注意,非客户端之间不能相互反射。但在反射之后,就违背了BGP设计之初防环的作用,所以又诞生了两个反射防环属性。
- originator-id:
反射路由器收到路由后,将起源者的rid标记,后面的路由器看到自己的rid,不收,从而起到防环的作用。
originator-id只能标记一个路由器,若途经多个反射器,则无能为力,可能导致反射器之间出环。所以出现了cluster-list。 - cluster-list:
反射路由器反射出去的路由,会生成列表,加入自己的rid,沿途反射的均加入自己的rid,等收到后,若列表中有自己的rid,则忽略,达到防环的目的。
2个汇总(Atomic-aggregate、aggregator)
由于路由协议庞大且复杂,那么避免不了需要对一些路由进行汇总,汇总本身就是消灭一些路由、产生一些路由,而在这个过程中必然会丢失很多属性。那么BGP就产生了2个汇总属性。
- Atomic-aggregate:
通过添加某些选项,来达到弥补丢失一些属性的作用。
加As-set,继承明细as属性,防环;加summary only只显示汇总;加advertise-map显示某些属性;加attribute-map为聚合后的添加某些属性。而在其他路由器得到汇总路由之后,有可能需要知道是谁产生的汇总,产生了寻找的需求,那么就产生了aggregator属性。 - aggregator:
通告汇总路由的汇聚路由器BGP-ID ,寻找汇总者方便
1个团体(community)
团体属性主要有两大作用:1. 为了可读性好; 2. 规定和谁玩
- 可读性好:
利用正则表达式X:Y形式来标识,使得可读性大大提高。 - 规定和谁玩:
利用四条子属性来规定和谁玩的问题。- Internet:默认属性,可以给任何bgp发送,不对携带团体值的路由做任何限制
- no-export:只能在一个as之内传递,可以在联盟内传递,该属性就是限制携带团体值的路由传递给ebgp邻居,联盟ebgp除外
- no-advertise:不在ibgp,ebgp邻居间传递,禁止传递给其他邻居
- local-as(no-export-subconfed):不向任何ebgp邻居发送,包括联盟的ebgp邻居
实验
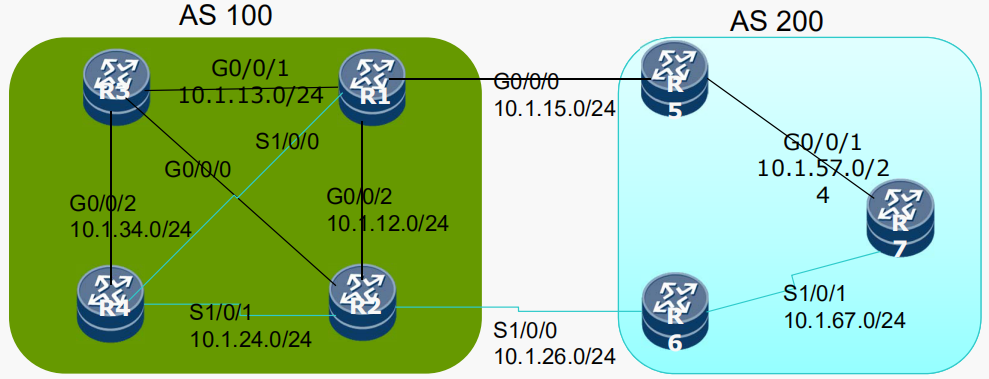
本课程使用拓扑约定:
- 如有必要,每个设备的环回接口xx.1.1.1/32作为路由协议的源地址
- 如有必要,业务网段采用x.x.x.x/32,比如2.2.2.2
- 直连网络采用10.1.xy.x/24,比如10.1.13.3
- 初始化配置:
# 配置IP
# R1
sys
sys R1
int lo 0
ip addr 11.1.1.1 32
int lo 1
ip addr 1.1.1.1 32
int g0/0/0
ip addr 10.1.15.1 24
int g0/0/1
ip addr 10.1.13.1 24
int g0/0/2
ip addr 10.1.12.1 24
int s1/0/0
ip addr 10.1.14.1 24
return
sa
# R2
sys
sys R2
int lo 0
ip addr 22.1.1.1 32
int lo 1
ip addr 2.2.2.2 32
int g0/0/0
ip addr 10.1.23.2 24
int g0/0/2
ip addr 10.1.12.2 24
int s1/0/1
ip addr 10.1.24.2 24
int s1/0/0
ip addr 10.1.26.2 24
return
sa
# R3
sys
sys R3
int lo 0
ip addr 33.1.1.1 32
int lo 1
ip addr 3.3.3.3 32
int g0/0/0
ip addr 10.1.23.3 24
int g0/0/1
ip addr 10.1.13.3 24
int g0/0/2
ip addr 10.1.34.3 24
return
sa
# R4
sys
sys R4
int lo 0
ip addr 44.1.1.1 32
int lo 1
ip addr 4.4.4.4 32
int s1/0/0
ip addr 10.1.14.4 24
int s1/0/1
ip addr 10.1.24.4 24
int g0/0/2
ip addr 10.1.34.4 24
return
sa
# R5
sys
sys R5
int lo 0
ip addr 55.1.1.1 32
int lo 1
ip addr 5.5.5.5 32
int g0/0/0
ip addr 10.1.15.5 24
int g0/0/1
ip addr 10.1.57.5 24
return
sa
# R6
sys
sys R6
int lo 0
ip addr 66.1.1.1 32
int lo 1
ip addr 6.6.6.6 32
int s1/0/0
ip addr 10.1.26.6 24
int s1/0/1
ip addr 10.1.67.6 24
return
sa
# R7
sys
sys R7
int lo 0
ip addr 77.1.1.1 32
int lo 1
ip addr 7.7.7.7 32
int g0/0/1
ip addr 10.1.57.7 24
int s1/0/1
ip addr 10.1.67.7 24
return
sa
# 通过ping来测试网络的连通性
# ---------------------------------------------
# 配置OSPF
# R1
ospf 1
area 0
int lo 0
ospf enable 1 area 0
int g0/0/1
ospf enable 1 area 0
ospf network-type p2p
int g0/0/2
ospf enable 1 area 0
ospf network-type p2p
int s1/0/0
ospf enable 1 area 0
ospf network-type p2p
return
sa
# R2
ospf 1
area 0
int lo 0
ospf enable 1 area 0
int g0/0/0
ospf enable 1 area 0
ospf network-type p2p
int g0/0/2
ospf enable 1 area 0
ospf network-type p2p
int s1/0/1
ospf enable 1 area 0
ospf network-type p2p
return
sa
# R3
ospf 1
area 0
int lo 0
ospf enable 1 area 0
int g0/0/0
ospf enable 1 area 0
ospf network-type p2p
int g0/0/1
ospf enable 1 area 0
ospf network-type p2p
int g0/0/2
ospf enable 1 area 0
ospf network-type p2p
return
sa
# R4
ospf 1
area 0
int lo 0
ospf enable 1 area 0
int g0/0/2
ospf enable 1 area 0
ospf network-type p2p
int s1/0/0
ospf enable 1 area 0
ospf network-type p2p
int s1/0/1
ospf enable 1 area 0
ospf network-type p2p
return
sa
# R5
ospf 1
area 0
int lo 0
ospf enable 1 area 0
int g0/0/1
ospf enable 1 area 0
ospf network-type p2p
return
sa
# R6
ospf 1
area 0
int lo 0
ospf enable 1 area 0
int s1/0/1
ospf enable 1 area 0
ospf network-type p2p
return
sa
# R7
ospf 1
area 0
int lo 0
ospf enable 1 area 0
int g0/0/1
ospf enable 1 area 0
ospf network-type p2p
int s1/0/1
ospf enable 1 area 0
ospf network-type p2p
return
sa
实验一:通过直连路由方式建立eBGP对等体
# R1
bgp 100
peer 10.1.15.5 as-number 200
network 1.1.1.1 32
# R5
bgp 200
peer 10.1.15.1 as-number 100
network 5.5.5.5 32
# 检查R1/5
# 查看对等体
dis bgp peer
# 查看路由表
dis bgp routing-table
# R1上测试连通性
ping -a 1.1.1.1 5.5.5.5
# 查看被选入路由表的bgp路由
dis ip rou pro bgp
实验二:通过环回口方式建立eBGP对等体
此实验更能说明:BGP peer是基于TCP连接之上建立的,BGP协议允许跨越多个节点建立BGP对等体,也就是说,即使不相邻的两台设备也可以建立BGP对等体。
应用环回口建立BGP对等体,是比较常见的一种可靠性的做法。环回口建立BGP对等体适用于不仅仅存在一条通信链路的两台BGP设备之间,提供了对等体的稳定(链路冗余)和高可用性。
# 保证环回口之间的IP连通性
# R1
ip route-static 55.1.1.1 32 10.1.15.5
# R5
ip route-static 11.1.1.1 32 10.1.15.1
# 使用ping进行检测
# 配置eBGP对等体
# R1
bgp 100
peer 55.1.1.1 as-number 200
# R5
bgp 200
peer 11.1.1.1 as-number 100
# 配置eBGP多跳或者关闭直连检测功能
# 【关闭直连检测,这个方案,仅仅适用于直连设备使用环回口建立eBGP对等体;设置eBGP多跳,这个方案同时也适用于域间MPLS VVV等需要跨越多个节点的两台eBGP设备建立对等体】
# 【华为设备只支持配置eBGP多跳】
# 否则停留在Idle状态,即TCP报文无法到达对等体
# 默认的情况下,绝大多数的BGP实现,应当保证eBGP对等体之间发送的报文 TTL = 1(直连)
# R1
bgp 100
peer 55.1.1.1 ebgp-max-hop 2 # 修改最大的跳数,即修改TTL的值
# R5
bgp 200
peer 11.1.1.1 ebgp-max-hop 2
# 指定更新源地址
# 否则停留在Active状态,即对等体之间找到了物理接口以及其上的IP,但是未找到环回口
# 指定了建立BGP对等体关系时使用的IP源地址,通常还会把这个地址做为下一跳地址附加在路径属性中,更新给邻居(简而言之,对等体之间默认物理接口和其上的IP作为peer的连接方式)
# R1
bgp 100
peer 55.1.1.1 connect-interface LoopBack 0
# R5
bgp 200
peer 11.1.1.1 connect-interface LoopBack 0
# 此时查看路由表
[R1] dis bgp rou
# 去往5.5.5.5/32的有两个下一跳,默认10.1.15.5为优选
# 如果想要让55.1.1.1成为下一跳,则需要在R1上执行以下命令:
bgp 100
peer 55.1.1.1 preferred-value 1 # 修改优先级
实验三:iBGP邻居配置实验(同时查看路由黑洞)
- 构建R1和R4、R5和R7的iBGP邻居
- 内部IGP使得更新源地址可达
- 非常重要的几个点:
- IGP保证更新源(对等体IP地址)可达
- 配置更新源
# 思科 neighbor 44.1.1.1 remote-as 100 neighbor 44.1.1.1 update-source Loopback0
# R1
bgp 100
peer 44.1.1.1 as 100
peer 44.1.1.1 connect-interface lo 0
return
sa
# R4
bgp 100
peer 11.1.1.1 as 100
peer 11.1.1.1 connect-interface lo 0
network 4.4.4.4 32
return
sa
# R5
bgp 200
peer 77.1.1.1 as 200
peer 77.1.1.1 connect-interface lo 0
return
sa
# R7
bgp 200
peer 55.1.1.1 as 200
peer 55.1.1.1 connect-interface lo 0
return
sa
实验四:使用全互联的方式解决路由黑洞
- 在R3上分别建立R1和R4的iBGP邻居
# R3
bgp 100
peer 11.1.1.1 as 100
peer 11.1.1.1 connect-interface lo 0
peer 44.1.1.1 as 100
peer 44.1.1.1 connect-interface lo 0
return
sa
# R1和R4
bgp 100
peer 33.1.1.1 as 100
peer 33.1.1.1 connect-interface lo 0
return
sa
# 测试
# R4
ping -a 4.4.4.4 1.1.1.1
tracert -a 4.4.4.4 1.1.1.1
实验五:修改下一跳属性
# R1
bgp 100
peer 33.1.1.1 next-hop-local
ret
sa
# R5
bgp 200
peer 77.1.1.1 next-hop-local
ret
sa
# 测试
# R7
refresh bgp all import # 刷新bgp路由列表
dis bgp rou
# R5
ping -a 5.5.5.5 4.4.4.4
实验六:BGP的下一跳不改变场景
在R1向R5传递路由时,尝试做下一跳不改变并观察现象【从R3\R4传递给R1(iBGP对等体)的BGP路由,再传递给R5(eBGP对等体)】
应用于域间MPLS VPN环境
# R1
bgp 100
peer 55.1.1.1 next-hop-invariable
return
reset bgp all
# R5
return
refresh bgp all import
dis bgp rou # 查看路由情况
# 此实验最后无现象,与ENSP模拟器有关系
实验七:BGP ASBR下一跳方案对比
取消R5对R7的下一跳自我,尝试将直连路由引入IGP并观察现象
对比下一跳自我和重发布直连,从路由收敛的角度分析不同之处
# R5
bgp 200
undo peer 77.1.1.1 next-hop-local
# R7
return
refresh bgp all import
dis bgp rou # 此时来自as100的路由无法优先,原因是下一跳不可达
# R5:重发布静态路由
ospf 1
import-route static
q
dis bgp rou # 此时来自as100的路由可以进行优选了
实验八:多点接入的下一跳
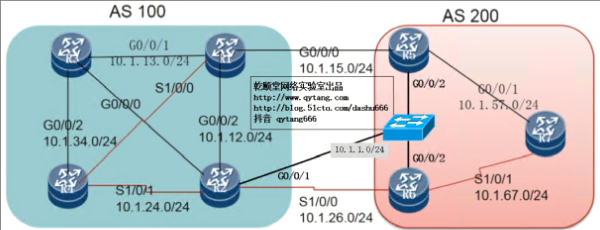
多点接入的下一跳(第三方下一跳)
R5、R6通过以太网建立iBGP对等体
R2、R6通过以太网建立eBGP对等体
观察R2和R5上的路由下一跳地址dis bgp rou 5.5.5.5
这种情况下,似乎R6向R2传递路由时,NH并未改为自己
此时尝试针对R2做下一跳自我并观察效果
# R2
int g0/0/1
ip addr 10.1.1.2 24
# R5
int g0/0/2
ip addr 10.1.1.5 24
# R6
int g0/0/2
ip addr 10.1.1.6 24
# R6
bgp 200
peer 10.1.1.5 as 200
peer 10.1.1.2 as 100
# R5
bgp 200
peer 10.1.1.6 as 200
# R2
bgp 100
peer 10.1.1.6 as 200
# 此时R2访问5.5.5.5的下一跳为10.1.1.5
# R6
bgp 200
peer 10.1.1.2 next-hop-local
# 此时R2访问5.5.5.5的下一跳为10.1.1.6(第三方下一跳)
实验九:部署BGP对等体组
通过对等体组模板简化配置
适用于针对多个对等体需要部署相同策略的环境
# R1
bgp 100
group PEER_GROUP internal # 创建一个针对IBGP的对等体组
peer PEER_GROUP connect-interface LoopBack0
peer PEER_GROUP next-hop-local
peer 44.1.1.1 group PEER_GROUP # 针对邻居来使用
peer 22.1.1.1 group PEER_GROUP
peer 33.1.1.1 group PEER_GROUP
# R2
bgp 100
group PEER_GROUP internal
peer PEER_GROUP connect-interface LoopBack0
peer PEER_GROUP next-hop-local
peer 11.1.1.1 group PEER_GROUP
peer 44.1.1.1 group PEER_GROUP
peer 33.1.1.1 group PEER_GROUP
# R3
bgp 100
group PEER_GROUP internal
peer PEER_GROUP connect-interface LoopBack0
peer PEER_GROUP next-hop-local
peer 11.1.1.1 group PEER_GROUP
peer 22.1.1.1 group PEER_GROUP
peer 44.1.1.1 group PEER_GROUP
# R4
bgp 100
group PEER_GROUP internal
peer PEER_GROUP connect-interface LoopBack0
peer PEER_GROUP next-hop-local
peer 11.1.1.1 group PEER_GROUP
peer 22.1.1.1 group PEER_GROUP
peer 33.1.1.1 group PEER_GROUP
实验十:部署基于对等体组的动态邻居(思科)
R3 做为动态邻居的侦听者,R1、R2、R4 主动找R3建立动态邻居
- 配置一个对等体组,用于部署侦听策略
neighbor Dynamic peer-group
neighbor Dynamic remote-as 100
neighbor Dynamic update-source Loopback2
- 规划一个子网范围用于动态邻居
172.16.1.0/24 - 每个设备配置一个子网范围内的 32 位的环回口,并使得其IP可达(宣高进IGP即可)
- 配置侦听
R3(config-router)#bgp listen range 172.16.1.0/24 peer-group Dynamic
实验十一:AS欺骗
在R1上欺骗R5
# R5
bgp 200
undo peer 11.1.1.1
peer 11.1.1.1 as 6535
peer 11.1.1.1 connect-interface lo 0
# R1
bgp 100
peer 55.1.1.1 fake-as 65535
实验十二:移除私有AS号码
思科:neighbor 10.1.1.10 remove-private-as all [replace-as]
# 暂时关闭在R2上的邻居
# R2
int g0/0/1
shutdown
# 配置邻居
# R5
bgp 200
peer 10.1.1.10 as 300
# SW
sys
sys SW
int vlanif 1
ip addr 10.1.1.10 24
q
bgp 300
peer 10.1.1.5 as 200
dis bgp rou
# 移除私有AS
# R5
bgp 200
peer 10.1.1.10 public-as-only
# 查看
# SW
refresh bgp all import
dis bgp rou
实验十三:路由自动聚合
R1创建额外环回口并通告,开启自动聚合
# 仅仅对重分布的路由(import-route)生效,组件路由抑制生成,但没有产生指向 null0的聚合路由
# R1
int l2
ip addr 1.1.1.2 32
int l3
ip addr 1.1.1.3 32
q
acl 2000
rule permit source 1.1.1.0 0.0.0.255
q
route-policy 1 permit node 10
if-match acl 2000
q
bgp 100
import-route direct route-policy 1
summary automatic
q
dis bgp rou
# 查看
# R5
dis bgp rou
dis bgp rou 1.0.0.0
补充:思科设备一般不做自动聚合,而使用流量清洗
# 思科
R1(config-router)#auto-summary
R1(config-router)#bgp aggregate-timer 0 // 默认 30秒
其实不是聚合的一种办法(通告指向空接口的静态)。不做重分布,将手工书写的聚合范围的静态路由network到BGP中。
R1(config)#ip route 1.1.1.0 255.255.255.0 null 0
R1(config-router)#network 1.1.1.0 mask 255.255.255.0
实验十四:手动聚合,验证起源代码的继承
# R1
bgp 100
undo summary automatic
aggregate 1.1.1.0 24
# aggregate 1.1.1.0 24 detail-suppressed # 抑制明细路由,抑制明细后生成的聚合携带原子聚合Atomic-aggregate属性,且不携带原明细路由的团体属性
q
dis bgp rou
dis bgp rou 1.1.1.0
# 查看
# R5
dis bgp rou
dis bgp rou 1.1.1.0
实验十五:为聚合路由设置属性
# R1
route-policy 2 permit node 10
apply origin igp
apply cost 666
bgp 100
aggregate 1.1.1.0 24 as-set detail-suppressed attribute-policy 2
# R5
dis bgp rou
dis bgp rou 1.1.1.0
实验十六:验证RR环境下的iBGP路由传递
R1部署为RR指定R3、R4为客户端(AS100内,所有设备只跟R1建立对等体)
客户端之间反射
客户端和非客户端之间反射
# R1
bgp 100
undo peer 22.1.1.1 group PEER_GROUP
peer 22.1.1.1 as 100
peer 22.1.1.1 con lo 0
peer 22.1.1.1 next-hop-local
peer 33.1.1.1 reflect-client
peer 44.1.1.1 reflect-client
# undo reflect between-clients # 关闭客户端之间的反射
# R2
bgp 100
peer 33.1.1.1 ignore
peer 44.1.1.1 ignore
network 2.2.2.2 32
# R3
bgp 100
peer 22.1.1.1 ignore
peer 44.1.1.1 ignore
# R4
bgp 100
peer 22.1.1.1 ignore
peer 33.1.1.1 ignore
# 查看路由
# R2\3
dis bgp rou
dis bgp rou 4.4.4.4
# R4
dis bgp rou
dis bgp rou 2.2.2.2
实验十七:理解起源者ID和Cluster-id的作用
R1、R2部署为RR,R3、R4部署为RR客户端
# R1
bgp 100
peer 22.1.1.1 reflect-client
# R2
bgp 100
peer PEER_GROUP route-client
undo peer 33.1.1.1 ignore
undo peer 44.1.1.1 ignore
# R3
bgp 100
undo peer 22.1.1.1 ignore
# R4
bgp 100
undo peer 22.1.1.1 ignore
# 查看
# R2
dis bgp rou
dis bgp rou 4.4.4.4
# 起源者ID防环
# R3
bgp 100
router-id 10.1.34.4 # 将起源者ID改成和R4相同
# Cluster-id防环
# R3
bgp 100
router-id 33.1.1.1 # 恢复起源者ID防环实验环境
# R1
bgp 100
reflector cluster-id 10.1.23.2 # 改成和R2相同的
实验十八:BGP联邦
- 实验内容:R5为AS2005,R6和R7为AS2067,同属于AS200
- 部署要点:
- 联邦边界对联邦内部的对等体做下一跳自我
- 所有的子AS都应该写到列表上
- 如果使用环回口建立,联邦内部的eBGP对等体应当配置eBGP多跳
配置国家AS:confederation id 200
配置国家内部城邦eBGP的AS列表(将所有的AS成员都写入):confederation peer-as 2067
# R5
undo bgp
bgp 2005
confederation id 200
confederation peer-as 2067
peer 11.1.1.1 as 100
peer 11.1.1.1 ebgp-max-hop 2
peer 11.1.1.1 connect-interface lo 0
peer 77.1.1.1 as 2067
peer 77.1.1.1 ebgp-max-hop 2
peer 77.1.1.1 connect-interface lo 0
network 5.5.5.5 32
# R6
undo bgp
bgp 2067
confederation id 200
confederation peer-as 2005
peer 77.1.1.1 as 2067
peer 77.1.1.1 connect-interface lo 0
network 6.6.6.6 32
# R7
undo bgp
bgp 2067
confederation id 200
confederation peer-as 2005
peer 66.1.1.1 as 2067
peer 66.1.1.1 connect-interface lo 0
peer 55.1.1.1 as 2005
peer 55.1.1.1 ebgp-max-hop 2
peer 55.1.1.1 connect-interface lo 0
# 删除之前配置环境
# R1
bgp 100
undo peer 55.1.1.1 next-hop-invariable
undo peer 55.1.1.1 fake-as 65535
# R5
ospf
undo import-route static # 此时R7收到的来自AS100的路由无法优选,因为下一跳不可达因此在这里需要设置下一跳自我
q
bgp 2005
peer 77.1.1.1 next-hop-local
实验十九:团体属性no-export
在R3上产生路由,应用策略,使其携带no-export属性
- 针对对等体应用通告团体的命令
- 设置团体策略
- 产生路由时应用团体策略
# R1
bgp 100
peer PEER_GROUP advertise-community
peer 22.1.1.1 advertise-community
# R2
bgp 100
peer PEER_GROUP advertise-community
# R4
bgp 100
peer PEER_GROUP advertise-community
# R3
route-policy COMM permit node 10
apply community no-export 100:333
q
bgp 100
network 3.3.3.3 32 route-policy COMM
peer PEER_GROUP advertise-community
# 查看
# R1/2/4/5
dis bgp rou 3.3.3.3
实验二十:团体属性no-export-subconfed(local-as)
在R7上产生路由,使其携带no-export-subconfed属性
实验2.1:在联邦内部应用 no-export 属性
no-export 在联邦环境下,不影响子AS之间的传递,但路由不能传出联邦
# R1
bgp 100
peer 55.1.1.1 advertise-community
# R5
bgp 2005
peer 77.1.1.1 advertise-community
peer 11.1.1.1 advertise-community
# R6
bgp 2067
peer 77.1.1.1 advertise-community
peer 10.1.26.2 as 100
peer 10.1.26.2 advertise-community
# R2
bgp 100
peer 10.1.26.6 as-number 200
peer 10.1.26.6 advertise-community
# R7
bgp 2067
peer 55.1.1.1 advertise-community
peer 66.1.1.1 advertise-community
q
route-policy COMM permit node 10
apply community no-export-subconfed 200:2067
q
bgp 2067
network 7.7.7.7 32 route-policy COMM
# 查看
# R7/6/5/2
dis bgp rou 7.7.7.7 # 此时只有在R6上有相应的路由且带有属性
# ---------------------------------
# 对比在通告时加入属性和传递给邻居时加入属性的区别
# 即直接在出方向上设置属性,不在通告上设置属性了
# R7
bgp 2067
undo network 7.7.7.7 32
network 7.7.7.7 32
peer 55.1.1.1 route-policy COMM export
peer 66.1.1.1 route-policy COMM export
# R7/6/5
dis bgp rou 7.7.7.7 # 此时R7本身不带团体属性,只有在R6和R5上有相应的路由且带有属性
# ---------------------------------
# 在联邦内部使用no-export属性
# R7
bgp 2067
undo peer 66.1.1.1 route-policy COMM export
undo peer 55.1.1.1 route-policy COMM export
network 7.7.7.7 32 route-policy COMM
q
route-policy COMM permit node 10
apply community no-export 200:2067
# R5/6/1
dis bgp rou 7.7.7.7 # 在R6和R5上有相应的路由且带有属性,但R1没有相应的路由
实验二十一:团体属性no-advertise
对比在通告时加入属性和传递给邻居时加入属性的区别
- 通告时携带,将不能传递出去
- 传递给邻居时携带,邻居将不能通告出去
# 通告时携带
# R7
int lo 2
ip addr 77.77.77.77 32
q
ip ip-prefix 7 permit 7.7.7.7 32
route-policy COMM permit node 10
undo apply community
if-match ip-prefix 7
apply community no-advertise # 7.7.7.7通告时携带属性,所有其无法通告给对等体
q
route-policy COMM1 permit node 10
apply community no-advertise # 77.77.77.77传递给邻居时携带属性,本路由可以通告给邻居,但是邻居收到后无法再向邻居的对等体进行通告
q
bgp 2067
network 77.77.77.77 32
peer 55.1.1.1 route-policy COMM1 export
peer 66.1.1.1 route-policy COMM1 export
实验二十二:设置自定义团体属性和MED
需求效果:
- R3产生的路由携带团体 100:333,并且数据转发路径为 7513
- R4产生的路由携带团体 100:444,并且数据转发路径为 7624 (调整AS100 IGP)
方案:
方案A
在R1和R2上根据团体对eBGP应用MED(MED越小越优)
# R3
route-policy COMM permit node 10
undo apply community
apply community 100:333
# R4
route-policy COMM permit node 10
apply community 100:444
bgp 100
network 4.4.4.4 32 route-policy COMM
# R1
ip community-filter 13 permit 100:333
ip community-filter 14 permit 100:444
route-policy MED permit node 10
if-match community-filter 13
apply cost 100
route-policy MED permit node 20
if-match community-filter 14
apply cost 200
route-policy MED permit node 30 # 放行其他所有的路由
bgp 100
peer 55.1.1.1 route-policy MED export
# R2
ip community-filter 13 permit 100:333
ip community-filter 14 permit 100:444
route-policy MED permit node 10
if-match community-filter 13
apply cost 200
route-policy MED permit node 20
if-match community-filter 14
apply cost 100
route-policy MED permit node 30
bgp 100
peer 10.1.26.6 route-policy MED export
# R6
bgp 2067
peer 77.1.1.1 next-hop-local
# 查看
# R7
bgp 2067
undo netowork 7.7.7.7 32
netowork 7.7.7.7 32
undo peer 55.1.1.1 route-policy COMM1 export
undo peer 66.1.1.1 route-policy COMM1 export
q
dis bgp rou
ping -a 7.7.7.7 3.3.3.3
tracert -a 7.7.7.7 3.3.3.3 # 10.1.57.5--10.1.15.1--10.1.13.3
ping -a 7.7.7.7 4.4.4.4
tracert -a 7.7.7.7 4.4.4.4 # 10.1.67.6--10.1.26.2--10.1.23.3--10.1.34.4:R2转发给R3再转发给R4,而不是直接转发给R4的原因是IGP(R2直连R4的接口带宽低,OSPF不选择此)
# 在此处不建议调整,因为修改IGP会导致AS100内部路由调整,所有最终的走向为 76234
方案B
在R5和R6上根据团体对eBGP进来的路由应用本地优先级(Local_Pref越大越优)
# 删除之前配置的MED
# R1
bgp 100
undo peer 55.1.1.1 route-policy MED export
# R2
bgp 100
undo peer 10.1.26.2 route-policy MED export
# 配置本地优先级
# R5
ip community-filter 23 permit 100:333
ip community-filter 24 permit 100:444
route-policy LP permit node 10
if-match community-filter 23
apply local-preference 200
route-policy LP permit node 20
if-match community-filter 24
apply local-preference 150
route-policy MED permit node 30
bgp 2005
peer 11.1.1.1 route-policy LP import
# R6
ip community-filter 23 permit 100:333
ip community-filter 24 permit 100:444
route-policy LP permit node 10
if-match community-filter 23
apply local-preference 150
route-policy LP permit node 20
if-match community-filter 24
apply local-preference 200
route-policy MED permit node 30
bgp 2067
peer 10.1.26.2 route-policy LP import
# 查看
# R7/5/6
refresh bgp all import
dis bgp rou
实验二十三:路由选择-比较权重值
仅仅本设备有意义,越大越优先
实验内容:
- R3针对R2入站的路由全部指定权重值为100
- R3针对R1进来的6.6.6.6路由指定权重值为200
# R3
ip ip-prefix 6 permit 6.6.6.6 32
route-policy WEIGHT permit node 10
if-match ip-prefix 6
apply preferred-value 200
route-policy WEIGHT permit node 20 # 放行其他所有的路由
q
bgp 100
peer 22.1.1.1 preferred-value 100
peer 11.1.1.1 route-policy WEIGHT import
# 查看
# R3
dis bgp rou
实验二十四:路由选择-比较本地优先级
本地优先级属性仅在iBGP对等体和联邦内部传递,不传递给eBGP对等体
该数值越大则优先级越高
缺省情况下,BGP本地优先级值为100设置本地优先级:default local-preferrence 250
实验内容:
- R6入站策略设置2.2.2.2的本地优先级为222
- R5设置默认本地优先级200
# R6
ip ip-prefix 2 permit 2.2.2.2 32
undo route-policy LP
route-policy LP permit node 10
if-match ip-prefix 2
apply local-preference 222
route-policy LP permit node 20
# R5
bgp 2005
undo peer 11.1.1.1 route-policy LP import
default local-preference 200
# 查看
# R7
dis bgp rou
实验二十五:路由选择-起源
使用route-policy修改起源代码
实验内容:
- 将R4优选的来自RR1的路由通过入站策略修改起源代码为“?”
# R4
route-policy ORIGIN permit node 10
apply origin incomplete
bgp 100
peer 11.1.1.1 route-policy ORIGIN import
# 查看
# R4
dis bgp rou
实验二十六:路由选择-as-path
跳过as-path选路规则命令bestroute as-path-ignore
实验内容:
- R1出站策略:为3.3.3.3设置前置AS号码100 100 100
- R2出站策略:为4.4.4.4设置前置AS号码100 100 100
# 下面设置是为了防止之前实验设置的本地优先级对本实验的影响
# R7
# route-policy NONE permit node 10
# apply local-preference 300
# R6
bgp 2067
undo peer 10.1.26.2 route-policy LP import
# R5
bgp 2005
undo defaut local-preference
# 配置
#R1
ip ip-prefix 3 permit 3.3.3.3 32
route-policy AS permit node 10
if-match ip-prefix 3
apply as-path 100 100 100 additive
route-policy AS permit node 20
bgp 100
peer 55.1.1.1 route-policy AS export
#R2
ip ip-prefix 4 permit 4.4.4.4 32
route-policy AS permit node 10
if-match ip-prefix 4
apply as-path 100 100 100 additive
route-policy AS permit node 20
bgp 100
peer 10.1.26.6 route-policy AS export
# 查看
# R5/6
dis bgp rou
实验二十七:路由选择-到BGP更新源IGP开销小的被优选
实验内容:
- 修改OSPF(IGP)的cost
- 将R4到R2的路径修改为经过R2比较小(即目前是R4-R3-R2,修改后为R4-R2)
# R4
bgp 100
undo peer 11.1.1.1 route-policy ORIGIN import
# R3
int g0/0/1
ospf cost 3
# 查看
# R4
dis bgp rou 7.7.7.7
实验二十八:路由选择-开启负载均衡
# R3
int g0/0/1
undo ospf cost
# R4
bgp 100
maximum load-balancing ibgp 2 # 可以开启iBGP或者eBGP的负载均衡,默认情况下只开启eBGP的负载均衡,如果eBGP有备份路径的话,可以开启iBGP的负载均衡。2代表负载均衡时使用两条链路。
# 负载均衡之后,路由前面(Status codes状态码那一列)会显示一个“m”,代表多路径multipath。
# 负载均衡虽然会有两条路径被优选,但是也只能向外更新一个,即best那条路由
实验二十九:产生默认路由的三种方式
# 方案一:使用network命令引入IGP路由
# R1
ip route-static 0.0.0.0 0 10.1.15.1
bgp 100
network 0.0.0.0
dis bgp rou # 起源代码为i
undo network 0.0.0.0 # 查看完毕之后直接删除
# 方案二:重发布
# R1
bgp 100
import-route static
default-route imported
dis bgp rou # 起源代码为?
undo import-route static
undo default-route imported
# 方案三:针对特定邻居下发默认路由
# R5
bgp 2005
peer 77.1.1.1 default-route-advertise
dis bgp rou # 在R5上看不见,需要在R7上查看,所以此命令需要在R7和R5上执行
undo peer 77.1.1.1 default-route-advertise
实验三十一:as-path控制列表
实验内容:
- 假设 R7 是我们的企业网
- R5、R6是两个SP,背后的AS100是大型SP
- 应用列表,阻止R7成为SP的流量载体
# 删除之前的环境
# R5
undo bgp 2005
# R6/7
undo bgp 2067
# R7
undo bgp 2067
# R1
bgp 100
undo peer 55.1.1.1
peer 10.1.15.5 as-number 500
# R2
bgp 100
undo peer 10.1.26.6
peer 10.1.26.6 as-number 600
# 重新配置环境
# R5
bgp 500
peer 10.1.15.1 as-number 100
peer 10.1.57.7 as-number 700
network 5.5.5.5 32
# R7
bgp 700
peer 10.1.67.6 as-number 600
peer 10.1.57.5 as-number 500
network 7.7.7.7 32
# R6
bgp 600
peer 10.1.67.7 as-number 700
peer 10.1.26.2 as-number 100
network 6.6.6.6 32
# 配置as-path访问控制列表
# R7
ip as-path-filter 1 permit ^$ # 匹配本地AS始发的更新路由
bgp 700
peer 10.1.57.5 as-path-filter 1 export
peer 10.1.67.6 as-path-filter 1 export #即仅仅通告本地始发的路由给对等体
# 此时,R6上去往R5(5.5.5.5)的路由的下一跳为10.1.26.2;R5上去往R6(6.6.6.6)的路由的下一跳为10.1.15.1。此时R5和R6上只有7.7.7.7的路由的下一跳为R7,即阻止了非R7流量经过R7的情况。
# 查看R7上通告路由情况
# R7
dis bgp peer 10.1.67.6 verbose
dis bgp peer 10.1.57.5 verbose
# 可以看到仅有一条路由更新出去,即本地AS始发的路由7.7.7.7
实验三十二:应用温和重配置
实验内容:
- 在R5上针对R1应用入站方向的前缀列表,过滤路由
- 应用入站方向的温和重配置
[R5-bgp]
# R5
ip ip-prefix 1234 permit 2.2.2.2 32
bgp 500
peer 10.1.15.1 ip-prefix 1234 import
dis bgp rou
peer 10.1.15.1 keep-all-routes
dis bgp rou
实验三十三:出站路由过滤ORF
在R5上设置入站策略,然后将策略通过ORF传至R1,编程R1的出站策略,对路由进行过滤
# R5
bgp 500
peer 10.1.15.1 capability-advertise orf ip-prefix send # 前缀列表是上一个实验写的:ip ip-prefix 1234 permit 2.2.2.2 32
# R1
bgp 100
peer 10.1.15.5 capability-advertise orf ip-prefix receive
# 查看
# R5
dis bgp rou
# R1
dis bgp peer 10.1.15.5 orf ip-prefix