CSS和iStack的区别:CSS是框式堆叠,iStack是盒式堆叠。两者只是叫法和实现有些差异,但是功能是一样的
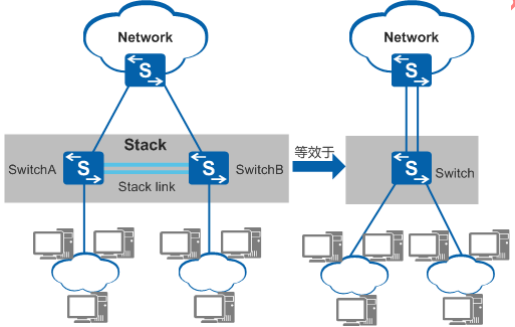
iStack(智能堆叠)
指将多台支持堆叠特性的交换机设备组合在一起,从逻辑上组合成一台交换设备
目的:
- 提高了可靠性:堆叠系统多台成员交换机之间冗余备份,同时利用跨设备的Eth-Trunk实现跨设备的链路冗余备份
- 强大的网络扩展能力:通过组建堆叠,可以在不改变网络拓扑的情况下,轻松地扩展端口数、带宽和处理能力
- 简化配置和管理:
- 用户可以通过任何一台成员交换机登录堆叠系统,对堆叠系统所有成员交换机进行统一配置和管理
- 堆叠形成后,不需要配置复杂的二层破环协议(如MSTP)和三层保护倒换协议(如VRRP),简化了网络配置
iStack中交换机的角色、堆叠ID和优先级
1. 角色
角色:包括一台主交换机(master)、一台备交换机(standby)和从交换机(slave)
- 一台主交换机(master):负责管理整个堆叠;主交换机不抢占,最先完成启动的交换机会成为主交换机
- 一台备交换机(standby):主交换机故障时,接替主交换机的所有业务
- 从交换机(slave):除主交换机和备交换机外,堆叠中其他所有的成员交换机都是从交换机
2. 堆叠ID
堆叠ID:成员交换机的槽位号(Slot ID),用来标识和管理成员交换机,默认为0,堆叠中所有成员交换机的堆叠ID都是唯一的
堆叠前:槽位号/子卡号/端口号(槽位号统一取值为0)如:GigabitEthernet0/0/1
堆叠后:堆叠ID/子卡号/端口号,例如堆叠ID为2,编号变为GigabitEthernet2/0/1
如果设备曾加入过堆叠,在退出堆叠后,仍然会使用组成堆叠时的堆叠ID作为自身的槽位号
3. 优先级
堆叠优先级:默认100
堆叠优先级是成员交换机的一个属性,主要用于角色选举过程中确定成员交换机的角色,优先级值越大表示优先级越高,优先级越高当选为主交换机的可能性越大
堆叠iStack的连接方式
交换机组建堆叠根据堆叠口的不同,可以分为两种方式:堆叠卡堆叠和业务口堆叠
- 堆叠卡堆叠又分为以下两种情况:
- 交换机之间通过专用的堆叠插卡及专用的堆叠线缆连接
- 堆叠卡集成到了交换机后面板上,交换机通过集成的堆叠端口及专用的堆叠线缆连接
- 业务口堆叠指的是交换机之间通过与逻辑堆叠端口绑定的物理成员端口相连,不需要专用的堆叠插卡
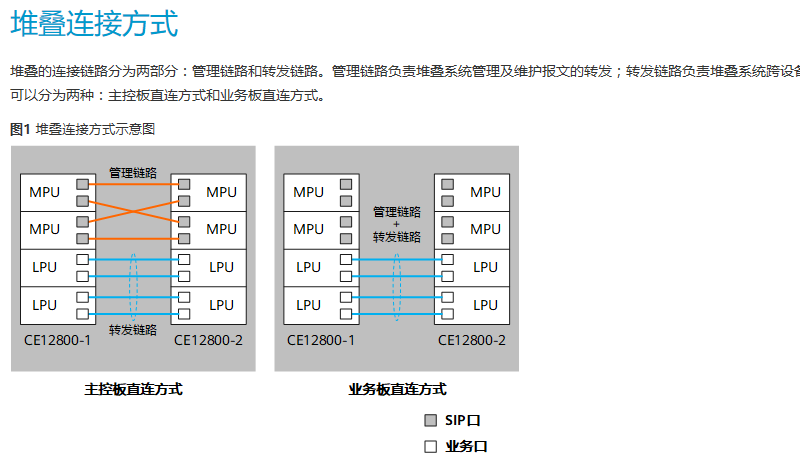
建议用户优先采用主控板直连方式,使管理链路和转发链路分离,以保证堆叠系统的高可靠性
堆叠iStack连接拓扑
- 链形连接:
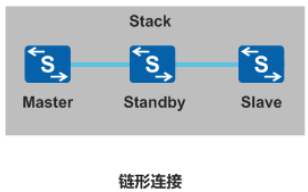
- 优点:首尾不需要连接,适合长距离
- 缺点:可靠性低,容易堆叠分裂,带宽利用率低
- 环形连接:
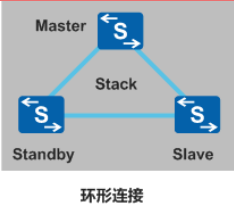
- 优点:可靠性高,环形变链形不影响工作,带宽利用率高
- 缺点:首尾需要连接,不适合长距离
堆叠iStack建立的过程
系统自动完成堆叠分为三步:
1. 主交换机选举
- 运行状态比较,已经运行的交换机比处于启动状态的交换机优先竞争为主交换机
- 堆叠优先级高的交换机优先竞争为主交换机
- 堆叠优先级相同时,MAC地址小的交换机优先竞争为主交换机
2. 拓扑收集和备交换机选举
主交换机选举完成后,主交换机会收集所有成员交换机的拓扑信息,根据拓扑信息计算出堆叠转发表项和破环点信息下发给堆叠中的所有成员交换机,并向所有成员交换机分配堆叠ID。之后进行备交换机的选举,作为主交换机的备份交换机
- 堆叠优先级最高的设备成为备交换机
- 堆叠优先级相同时,MAC地址最小的成为备交换机
3. 稳定运行
其他成员交换机作为从交换机加入堆叠,所有成员交换机会自动同步主交换机的系统软件和配置文件:
- 备交换机或从交换机与主交换机的软件版本不一致时,备交换机或从交换机会自动从主交换机下载系统软件,然后使用新系统软件重启,并重新加入堆叠
- 备交换机或从交换机会将主交换机的配置文件同步到本设备并执行,以保证堆叠中的多台设备能够像一台设备一样在网络中工作,并且在主交换机出现故障之后,其余交换机仍能够正常执行各项功能。
堆叠成员加入和退出过程
成员加入
即向已经稳定运行的堆叠系统添加一台新的交换机
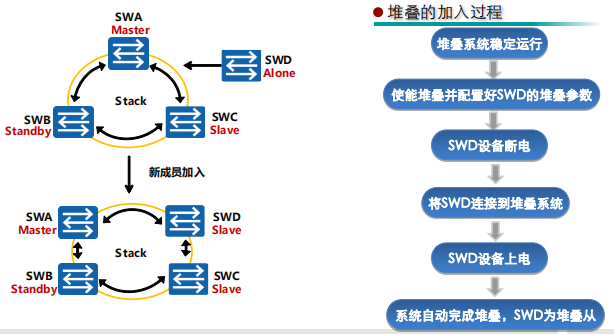
- 使能堆叠并配置好SWD的堆叠参数
- 如果是业务口堆叠,新加入的交换机需要配置物理成员端口加入逻辑堆叠端口
- 如果是堆叠卡堆叠,新加入的成员交换机需要使能堆叠功能
为了便于管理,建议新加入的交换机配置堆叠ID,如果不配置,堆叠系统会为其分配一个堆叠ID
- 将SWD连接到堆叠系统
- 如果是链型连接,新加入的交换机建议添加到链型的两端,这样对现有的业务影响最小
- 如果是环型连接,需要把当前环型拆成链型,然后在链型的两端添加设备
- 系统完成堆叠
- 新加入的交换机连线上电启动后,进行角色选举,新加入的交换机会选举为从交换机,堆叠系统中原有的主备从角色不变
- 角色选举结束后,主交换机更新堆叠拓扑信息,同步到其他成员交换机上,并向新加入的交换机分配堆叠ID(在新成员未配置或配置冲突时)
- 新加入的交换机更新堆叠ID,并同步主交换机的配置文件和系统软件,之后进入稳定运行状态
成员退出
- 当主交换机退出:
- 备升为主,重新计算拓扑并进行同步到其他成员交换机
- 指定新的备交换机,之后进入稳定运行状态
- 当备交换机退出:
主交换机重新指定备交换机,重新计算拓扑并同步,之后进入稳定运行状态 - 当从交换机退出:
主交换机重新计算堆叠拓扑并同步,之后进入稳定运行状态
堆叠成员交换机退出的过程,主要就是拆除堆叠线缆和移除交换机的过程:
- 对于环形堆叠:成员交换机退出后,为保证网络的可靠性还需要把退出交换机连接的两个端口通过堆叠线缆进行连接
- 对于链形堆叠:拆除中间交换机会造成堆叠分裂。这时需要在拆除前进行业务分析,尽量减少对业务的影响。
堆叠分裂
指稳定运行的堆叠系统中带电移出部分成员交换机,或堆叠线缆多点故障导致一个堆叠系统变成多个堆叠系统,堆叠分裂分为以下两类:
- 原主备交换机被分裂到同一个堆叠系统中
原主交换机会重新计算堆叠拓扑,将移出的成员交换机的拓扑信息删除,并将新的拓扑信息同步给其他成员交换机
而移出的成员交换机检测到堆叠协议报文超时,将自行复位,重新进行选举 - 原主备交换机被分裂到不同的堆叠系统中
原主交换机所在堆叠系统重新指定备交换机,重新计算拓扑信息并同步给其他成员交换机
原备交换机所在堆叠系统将发生备升主,原备交换机升级为主交换机,重新计算堆叠拓扑并同步到其他成员
交换机,并指定新的备交换机
堆叠分裂会有什么问题?如何解决?(MAD多主检测,DAD双主检测)
由于堆叠系统中所有成员交换机都使用同一个IP地址和MAC地址(堆叠系统 MAC),一个堆叠分裂后,可能产生多个具有相同IP地址和MAC地址的堆叠系统,引起网络故障,因此必须进行IP地址和MAC地址的冲突检查。
多主检测MAD是一种检测和处理堆叠分裂的协议。链路故障导致堆叠系统分裂后,MAD可以实现堆叠分裂的检测、冲突处理和故障恢复,降低堆叠分裂对业务的影响。
MAD检测方式有两种:直连检测方式和代理检测方式两种检测方式互斥,不可以同时配置
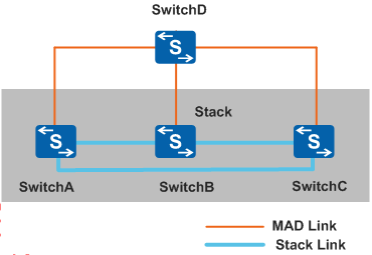
1. 直连检测
直连检测方式又分为通过中间设备直连和Full-mesh方式直连
- 通过中间设备直连
堆叠系统的所有成员交换机之间至少有一条检测链路与中间设备相连
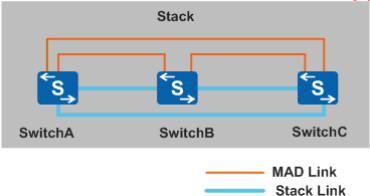
- Full-mesh方式直连
堆叠系统的各成员交换机之间通过检测链路建立Full-mesh全连接,即每两台成员交换机之间至少有一条检测链路
通过中间设备直连可以实现通过中间设备缩短堆叠成员交换机之间的检测链路长度,适用于成员交换机相距较远的场景;
Full-mesh方式直连可以避免由中间设备故障导致的MAD检测失败,但是每两台成员交换机之间都建立全连接会占用较多的接口,所以该方式适用于成员交换机数目较少的场景
2. 代理检测
代理检测方式是在堆叠系统Eth-Trunk上启用代理检测,在代理设备上启用MAD检测功能。
此种检测方式要求堆叠系统中的所有成员交换机都与代理设备连接,并将这些链路加入同一个Eth-Trunk内。
与直连检测方式相比,代理检测方式无需占用额外的接口,Eth-Trunk接口可同时运行MAD代理检测和其他业务。在代理检测方式中,堆叠系统正常运行时,堆叠成员交换机以30s为周期通过检测链路发送MAD报文。
堆叠成员交换机对在正常工作状态下收到的MAD文不做任何处理;堆叠分裂后,分裂后的两台交换机以1s为周期通过检测链路发送MAD报文以进行多主冲突处理
MAD冲突及故障恢复后如何处理
- MAD冲突处理
堆叠分裂后,MAD冲突处理机制会使分裂后的堆叠系统处于Detect状态或Recovery状态Detect状态表示堆叠正常工作状态,Recovery状态表示堆叠禁用状态- MAD分裂检测机制会检测到网络中存在多个处于Detect状态的堆叠系统
- 这些堆叠系统之间相互竞争,竞争成功的堆叠系统保持Detect状态,竞争失败的堆叠系统会转入Recovery状态
- 在 Recovery状态堆叠系统的所有成员交换机上,关闭除保留端口以外的其它所有物理端口,以保证该堆叠系统不再转发业务报文
- MAD故障恢复
通过修复故障链路,分裂后的堆叠系统重新合并为一个堆叠系统。重新合并的方式有以下两种:- 堆叠链路修复后,处于Recovery状态的堆叠系统重新启动,与Detect状态的堆叠系统合并,同时将被关闭的业务端口恢复Up,整个堆叠系统恢复
- 如果故障链路修复前,承载业务的Detect状态的堆叠系统也出现了故障。此时,可以先将Detect状态的堆叠系统从网络中移除,再通过命令行启用Recovery状态的堆叠系统,接替原来的业务,然后再修复原Detect状态堆叠系统的故障及链路故障。故障修复后,重新合并堆叠系统
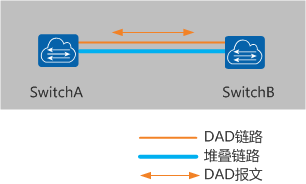
DAD双主检测
检测方式如下:
1. 业务口直连检测方式
堆叠成员交换机间通过业务口连接的专用链路进行双主检测
2. Eth-trunk代理检测方式
通过堆叠与代理设备相连的跨设备Eth-Trunk链路进行双主检测,代理设备需要启动DAD代理功能
与业务口直连检测方式相比,Eth-Trunk口代理检测方式无需占用额外的接口,Eth-Trunk接口可以同时运行DAD代理检测和其他业务
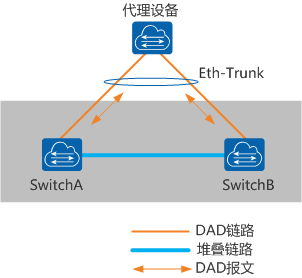
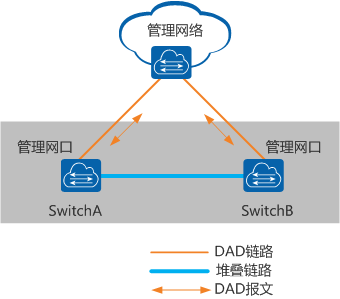
3. 管理口检测方式
通过堆叠成员交换机的管理网口链路进行双主检测。当所有堆叠成员交换机的管理网口都连接至管理网络时,可以使用该方式进行双主检测,不需要占用额外的接口,也不需要使用代理设备。
在管理网口检测方式中,要求堆叠系统的管理网口必须配置IP地址
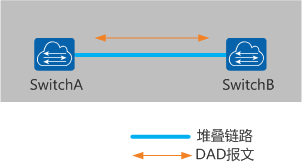
4. 堆叠端口检测方式(仅CE12800&12800E支持)
通过堆叠物理成员端口之间的链路进行双主检测,该方式直接使用堆叠连接链路进行检测,不需要占用额外的接口
只有当堆叠连接方式为主控板直连时,才可以使用堆叠端口检测方式
CSS(集群)
CSS集群连接方式
- 集群卡集群方式
集群成员交换机之间通过主控板上专用的集群卡及专用的集群线缆连接 - 业务口集群方式
集群成员交换机之间通过业务板上的普通业务口连接,不需要专用的集群卡
同iStack,业务口集群一样涉及两种端口的概念:物理成员端口和逻辑集群端口
集群成员加入与合并、集群分裂
使能了集群功能的单台交换机即为单框集群
成员加入
集群成员加入是指向稳定运行的单框集群系统中添加一台新的交换机,原单框集群的交换机成为主交换机,新加入的交换机成为备交换机
成员合并
集群合并是指稳定运行的两个单框集群系统合并成一个新的集群系统。
两个单框集群系统将自动选出一个更优的作为合并后集群系统的主交换机。被选为主交换机的配置不变,业务也不会受到影响,框内的备用主控板将重启。而备交换机将整框重启,以集群备的角色加入新的集群系统,并将同步主交换机的配置,该交换机原有的业务也将中断
集群分裂
系统主用主控板和系统备用主控板定时发送心跳报文来维护集群系统的状态。
当两台交换机之间的心跳报文超时(超时时间为8秒)时,集群系统将分裂为两个单框集群系统。
集群分裂后,由于成员交换机运行着相同的配置文件,就会产生两个具有相同IP和MAC的集群系统,为防止由此引起网络故障,必须进行IP地址和MAC地址的冲突检查
集群的多主检测MAD和堆叠相同