iSCSI
iSCSI与NFS的区别
在产品开发过程中,除了对运维、数据库等的讨论,更多的是在讨论存储的问题,这不仅仅涉及到日志、用户数据等储存和再利用,还设计到系统的稳定性以及产品上线之后的运维等一系列问题。目前,主要将存储分为两大类:
- 直连存储(DAS),即通过主板跟硬盘直接相连的存储,读写速率高,但是扩展性依赖与主板存储接口的数量,后期存储扩展的费用高、工程量大
- 网络存储,即通过网络提供的存储,可扩展性比较好,但网络是瓶颈,但目前通过4口万兆光网卡主板带宽为40G时聚合一般可以解决问题
通过以上的对比,目前在开发过程中主要采用的是网络存储,在网络存储中,又分为两大派系:
- NAS,网络附加存储,通过网络提供额外的存储给前端服务器使用,即文件系统在存储,主要代表为NFS(比较流行)和CIFS(Samba,安全性问题比较多)
- SAN,存储区域网络,是一个提供了存储的网络区域,即文件系统在前端,主要代表为iSCSI(IP SAN,成本低,兼容性强)和FC SAN(硬件包括FC卡、FC HUB、FC交换机、存储系统等)
从成本和后期维护等角度考虑,目前常用的为iSCSI和NFS,下面看一下应用在各种情况下是如何存储数据的:
- Linux存储模型如下:
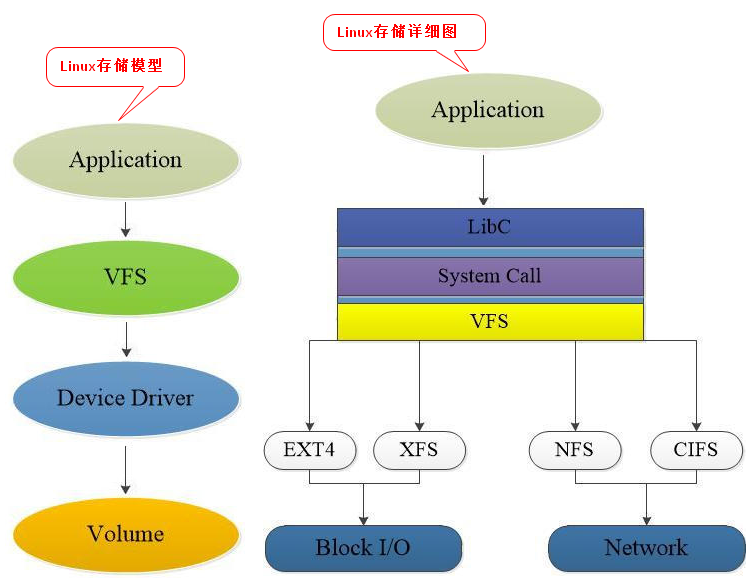
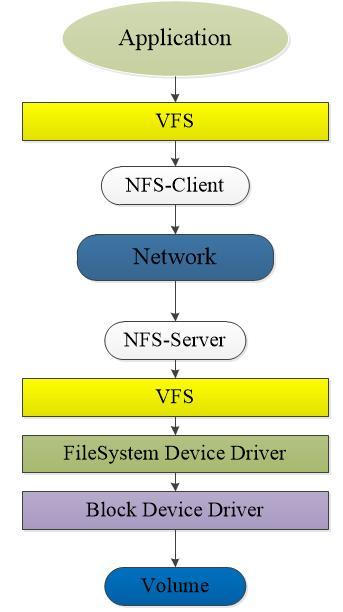
- NAS存储模型如下:
- iSCSI存储模型如下:
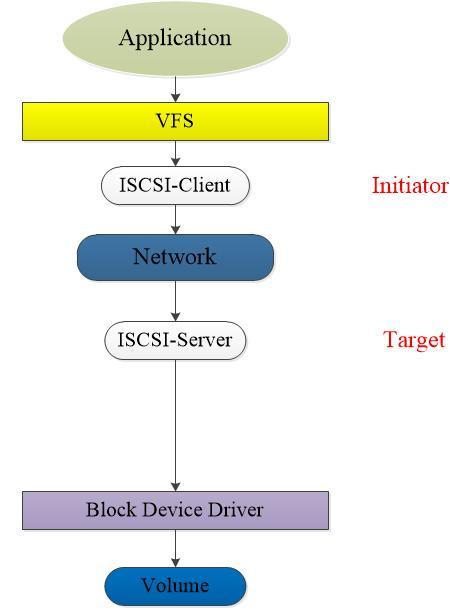
通过以上对比,iSCSI比NFS主要是减少了VFS层的开销以及文件系统的开销,前端服务器可以直接将iSCSI作为本地磁盘进行任何操作,连接上iSCSI存储之后,本地会多出跟直连设备一样的存储设备,供前端设备进行分区和格式化操作,所以其效率比NFS要高。
同时,ISCSI前端服务器可以根据需要连接更多或者更少的iSCSI存储,如同在本地直连更多存储一样,然后进行分区、格式化等操作,之后加入LVM来扩展原有的文件系统,并且没有主板接口的限制,扩展性极强。
NFS作为一种附加存储,只能在服务端进行存储的扩展才能做到前端存储的增加,并且前端挂载之后,无法在其上建立LVM,因此无法直接扩展前端原有的文件系统,扩展性相对较低。
但是NFS并非一无是处,其在存储共享,尤其是文件系统的共享,以及存储设备故障之后,进行数据恢复,这两方面存在巨大的优势。
这两者的本质区别是NFS使用文件级别的实施,服务器或存储阵列托管整个文件系统,客户到文件系统上读写文件,而iSCSI则使用数据块,存储阵列向客户提供数据块集合,赋予原始存储数据一定的格式化,而不去管文件系统究竟如何使用。因此,在数据备份时,NFS备份的是文件系统,而iSCSI备份的数据块。
iSCSI搭建
iSCSI分为服务端(target)与客户端(initiator)。iSCSI服务端,用于存放硬盘存储资源的服务器,提供可用的存储资源。iSCSI客户端,即用于访问远程服务端的存储资源工具
环境介绍
iSCSI服务端,Centos7,192.168.10.10
iSCSI客户端,Centos7,192.168.10.20
1. 关闭selinux
2. 关闭firewalld
如果不关闭防火墙firewalld,则需要放行相应的端口:
firewall-cmd --permanent --add-port=3260/tcp
firewall-cmd --reload
服务端(target)
# 安装服务端和配置工具
yum -y install targetd targetcli
systemctl enable targetd
# 配置
targetcli
ls # 查看目录结构
cd /backstores/block # 进入添加存储资源的目录下
create diska /dev/sdb # 添加磁盘/dev/sdb为存储资源,即将/dev/sdb共享出去,diska可自定义,下面创建target名称之后还要用到
# 或者create dev=/dev/sdb name=sdb
# 创建target名称
# iSCSI target 名称一串用于描述共享资源的唯一字符串
cd /iscsi
create # 由系统默认生成,例如此次生成的结果如下:iqn.2003-01.org.linux-iscsi.source.x8664:sn.cdfa333799987,注意最后一个英文句号不是名称部分
# 或者自定义:create iqn.2021-08.node1.iscsi:server
cd iqn.2003-01.org.linux-iscsi.source.x8664:sn.cdfa333799987/tpg1/luns
create /backstores/block/diska # 在添加存储资源时,diska是自定义的,需要保持一致
# 设置访问控制列表
# iSCSI 协议是通过客户端名称进行验证的,用户在访问存储共享资源时不需要输入密码,只要 iSCSI 客户端的名称与服务端中设置的访问控制列表中某一名称条目一致即可
# 认证字符串一般设置的时候遵循的规则是:在名称后面加:client
cd ../acls
create iqn.2003-01.org.linux-iscsi.source.x8664:sn.cdfa333799987:client
# 这个字符串需要记录下来,客户端需要使用
# 设置 iSCSI 服务端的监听 IP 地址和端口号
# 默认监听的是0.0.0.0:3260
cd ../portals
create 192.168.10.10
# 检查配置信息
cd /
ls
# 退出并重启服务
exit
systemctl start targetd && systemctl status targetd
客户端(initiator)
# 安装客户端
yum -y install iscsi-initiator-utils
systemctl enable iscsid
# 编辑客户端验证文件
# iSCSI协议是通过客户端的名称来进行验证,而该名称也是iSCSI客户端的唯一标识
# 而且必须与服务端配置文件中访问控制列表中的信息一致
# 否则客户端在尝试访问存储共享设备时,系统会弹出验证失败信息
vim /etc/iscsi/initiatorname.iscsi
InitiatorName=iqn.2003-01.org.linux-iscsi.source.x8664:sn.cdfa333799987:client
systemctl start iscsid && systemctl status iscsid
# iSCSI客户端访问并使用共享存储资源的步骤
# 先发现,再登录,最后挂载并使用
iscsiadm -m discovery -t st -p 192.168.10.10
iscsiadm -m node -T iqn.2003-01.org.linux-iscsi.source.x8664:sn.cdfa333799987 --login
# 登录之后就可以发现本地已经多了一个存储,例如新增的是/dev/sdb
lsblk
file /dev/sdb
mkfs.xfs /dev/sdb
blkid | grep /dev/sdb # 查看该存储资源UUID,用于挂载网络存储
mkdir /iscsi # 挂载路径
echo "UUID=xxxxxxxx /iscsi xfs defaults,_netdev 0 0" /etc/fstab # 添加上_netdev参数,表示当系统联网后再进行挂载操作
mount -a
# 不再使用iSCSI共享设备资源时,使用-u 参数将其设备卸载
iscsiadm -m node -T iqn.2003-01.org.linux-iscsi.source.x8664:sn.cdfa333799987 -u
iSCSI认证
上面只是通过字符串进行认证,这种方式简便,但是也存在安全问题,iSCSI提供不同的认证方式来解决其安全问题
iSCSI认证分为发现认证和登录认证,其中每种认证又分为单向认证和双向认证。发现认证和登录认证的意思就和名字一样。
单向认证是指initiator端在发现target端的时候,要提供正确的认证才能发现在target端的iSCSI服务;双向认证是指在单向认证的基础上,target端需要正确设置initiator端设置的认证才能被initiator端发现
发现认证
- 设置单向认证
# .......................服务端..................................
targetcli
cd /iscsi
# 查看发现认证的默认属性,这是一个全局的设置
get discovery_auth enable userid password mutual_userid mutual_password
# 设置单向认证
set discovery_auth enable=1 userid=target10 password=123456
exit
systemctl restart targetd
# .........................客户端......................................
# 修改iscsi配置文件
vim /etc/iscsi/iscsid.conf
discovery.sendtargets.auth.authmethod = CHAP # 默认认证方式为挑战握手协议
discovery.sendtargets.auth.username = target10
discovery.sendtargets.auth.password = 123456
systemctl restart iscsid
# 重新发现(登陆步骤省略)
iscsiadm -m discovery -t st -p 192.168.10.10
- 设置双向认证
# .........................客户端......................................
# 首先在initiator端设置认证
vim /etc/iscsi/iscsid.conf # 追加如下内容
discovery.sendtargets.auth.username_in = initiator20
discovery.sendtargets.auth.password_in = 654321
systemctl restart iscsid
# .......................服务端..................................
targetcli
cd /iscsi
set discovery_auth mutual_userid=initiator20 mutual_password=654321
exit
systemctl restart targetd
登录认证
登录认证和发现认证类似,也是分为单向认证和双向认证,设置的方法和发现认证几乎一样
# .......................服务端..................................
# generate_node_acls属性表示是否开启ACL,当为no-gen-acls的是否,initiator端的iqn号(/etc/iscsi/initiatorname.iscsi下)必须加入acl才能登陆
targetcli
cd iscsiiqn.2003-01.org.linux-iscsi.source.x8664:sn.cdfa333799987/tpg1
ls
# 在tpg1目录下打开认证set attribute authentication=1,作用类似发现认证的enable
# 在acls的iqn....目录下设置用户和密码,操作类似发现认证
set auth # 参数包含单向认证的userid和password,以及双向认证的mutual_userid和mutual_password,此处不再演示
# .........................客户端......................................
vim /etc/iscsi/iscsid.conf # 追加如下内容
# 即将发现中的discovery.sendtargets改成node.session
# 单向
node.session.auth.authmethod = CHAP # 默认认证方式为挑战握手协议
node.sessions.auth.username = target10
node.session.auth.password = 123456
# 双向
node.session.auth.username_in = initiator20
node.session.auth.password_in = 654321
NFS
环境
NFS服务器,Centos7,192.168.10.10
NFS客户端,Centos7,192.168.10.20
实施
# ..................服务端
# 安装
yum -y install nfs-utils
systemctl enable rpcbind && systemctl enable nfs-server
# 编辑配置文件
# 格式:共享目录的路径 允许访问的NFS客户端(共享权限参数)
# 共享权限参数介绍:
# ro\rw:只读\读写
# root_squash\no_root_squash:当NFS客户端以root管理员访问时,映射为NFS服务器的匿名用户\root管理员
# sync\async:同时将数据写入内存和硬盘中\优先将数据保存在内存
vim /etc/exports
/nfs10 192.168.10.*(rw,sync,root_squash) # 允许访问的NFS客户端(共享权限参数),没有空格
systemctl start rpcbind && systemctl start nfs-server
# ................客户端
showmount -e 192.168.10.10
mkdir /nfs20
echo "192.168.10.10:/nfs10 /nfs20 nfs defaults 0 0" >>/etc/fstab
mount -a
# 临时挂载:mount -t nfs 192.168.10.10:/nfs10 /nfs20
自动挂载服务autofs
无论是Samba还是NFS,都要把挂载信息写入到/etc/fstab中,这样远程共享资源就会自动随服务器开机而进行挂载。虽然这很方便,但是如果挂载的远程资源太多,则会给网络带宽和服务器的硬件资源带来很大负载。
如果在资源挂载后长期不使用,也会造成服务器硬件资源的浪费。
autofs自动挂载服务与mount命令不同,当检测到用户试图访问一个尚未挂载的文件系统时,将自动挂载该
文件系统,实现存储资源的动态挂载,从而节约了网络资源和服务器的硬件资源。
# 安装
yum -y install autofs
systemctl enable autofs && systemctl start autofs
# 修改配置文件
# 格式:挂载目录 子配置文件。挂载目录是设备挂载位置的上一级目录,例如光盘设备一般挂载到/media/cdrom目录中,那么挂载目录写成/media即可
# 对应的子配置文件则是对这个挂载目录内的挂载设备信息作进一步的说明
# 子配置文件需要用户自行定义,文件名字没有严格要求,但后缀建议以.misc结束
vim /etc/auto.master
/media /etc/autofs/iso.misc
/nfs20 /etc/autofs/nfs.misc # 将192.168.10.10的nfs挂载到/nfs20/test10目录下
vim /etc/autofs/iso.misc
iso -fstype=iso9660,ro,nosuid,nodev :/dev/cdrom # 第一个参数是最后一级目录,千万不能加/
test10 -fstype=nfs 192.168.10.10:/nfs10
systemctl restart autofs
RAID
硬RAID需要使用专用的RAID卡来实现,有的时候在资金不充足的情况下,又想保证数据的安全性,可以使用软RAID来实现,但是这个需要CPU资源来支持
为了实现分布式存储,提高存储的可用性,以及数据的安全性,可以使用iSCSI+软RAID的方案,即iscsi的客户端initiator作为存储资源的管理端,将多块iscsi存储资源配置为raid
软RAID和硬RAID的区别
如果由CPU执行硬盘控制器的驱动程序代码完成,就是软RAID;如果由RAID卡上的主控芯片完成,就是硬RAID。
有的服务器虽然没有RAID卡,但是主板板载RAID控制芯片完成上述转换,这也是硬RAID。但是在家用级主板,某些低端的扩展卡所提供的RAID功能,是由CPU执行驱动程序的相关代码实现上述转换,都是软RAID。
某些操作系统的文件系统/块设备驱动本身也可以实现类似功能,例如Windows动态磁盘实现的镜像卷/带区卷/RAID5卷以及存储空间、Linux的DM、BtrFS、BSD/Solaris的ZFS,与硬件无关,自然都是软RAID。对于软RAID来说,这些操作需要占用一定的CPU资源,尤其是RAID5和RAID6这两种模式的写入操作很复杂,不建议使用,数据修复几乎不可能
至于安全性和便利性方面:
- 安全性方面,只要RAID级别相同,并没有太大区别,主要看RAID管理器是否提供校验/修复功能,是否支持自动定期校验/修复
- 便利性方面,主要看RAID管理器提供的功能。例如是否可以动态扩展逻辑驱动器,动态升级RAID级别,或者增加SSD缓存加速读写性能等。如果软RAID是Intel芯片组提供的话,Intel的RST是支持这几个功能的,至于其它硬RAID或者软RAID方案,需要具体问题具体分析
当需要迁移系统时,硬RAID可以直接 Ghost ;但是软RAID没法Ghost备份
如果不开启写入缓存(例如RAID卡设置为WriteThrough模式),RAID5和RAID6的写入性能会非常低下。如果开启回写缓存(RAID卡设置WriteBack模式),则一旦发生系统崩溃、电源故障等情况,可能会导致数据丢失,硬件RAID卡一般会有电池单元给缓存供电,系统重启/电源恢复的时候可以把缓存中未写入硬盘的数据写入硬盘。
实施
# 安装软件
yum -y install mdadm
# 创建raid阵列
mdadm -Cv /dev/md0 -n 3 -l 5 -x 1 /dev/sdb /dev/sdc /dev/sdd /dev/sde
# -Cv:为创建阵列并显示过程
# /dev/md0:为生成的阵列组名称
# -n 3:创建RAID 5磁盘阵列所需的硬盘个数
# -l 5:RAID磁盘阵列的级别
# -x 1:磁盘阵列的备份盘个数
# /dev/sdb /dev/sdc /dev/sdd /dev/sde:需要使用的硬盘名称,可以使用配符来指定硬盘设备的名称
# 查看设备的详细信息
mdadm -D /dev/md0
LVM
如果存储服务器已经配置了硬RAID1或者RAID10或者RAID01来保障数据的安全性,为了提高存储的可用性和扩展性,通常需要使用iSCSI搭配LVM来实现,即在iscsi的客户端initiator上配置LVM来实现存储的伸缩,即随着实际需求的变化调整硬盘分区的大小时,提高存储灵活性,LVM可以允许用户对硬盘资源进行动态调整。LVM是在硬盘分区和文件系统之间添加了一个逻辑层,它提供了一个抽象的卷组,可以把多块硬盘进行卷组合并。
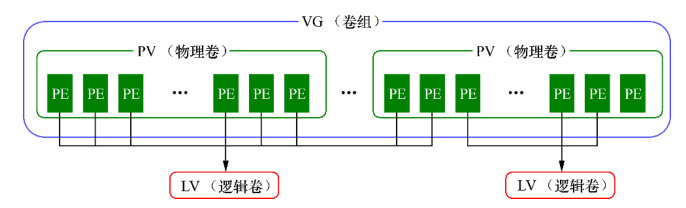
- 物理卷PV处于LVM中的最底层,可以将其理解为物理硬盘、硬盘分区或者RAID磁盘阵列
- 卷组VG建立在物理卷PV之上,一个卷组VG可以包含多个物理卷PV,而且在卷组VG创建之后也可以继续向其中添加新的物理卷PV
- 逻辑卷LV是用卷组中空闲的资源建立的,并且逻辑卷在建立后可以动态地扩展或缩小空间
命令介绍
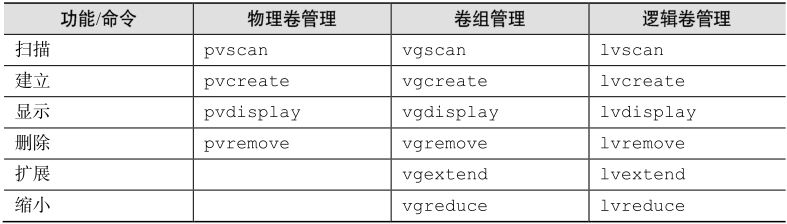
实施
创建
# ......................物理卷...................
# 添加需要使用的磁盘
pvcreate /dev/sdb /dev/sdc
# 查看状态
pvdisplay
# ......................卷组...................
# 把两块硬盘设备加入到storage(自定义)卷组
vgcreate storage /dev/sdb /dev/sdc
# 查看卷组的状态
vgdisplay
# ......................逻辑卷...................
# 切割出一个约为150MB的逻辑卷设备
# 对逻辑卷进行切割时有两种计量单位:
# 1. 以容量为单位,所使用的参数为-L,例如,使用-L 150M生成一个大小为150MB的逻辑卷
# 2. 以基本单元(默认为4MB)的个数为单位,所使用的参数为-l,例如,使用-l 37可以生成一个大小为37×4MB=148MB的逻辑卷
lvcreate -n vo -l 37 storage # vo是自定义的,后面挂载时使用;storage是在创建卷组时自定义的
# 查看逻辑卷状态
lvdisplay
# 把生成好的逻辑卷进行格式化,然后挂载使用
mkfs.xfs -f /dev/storage/vo
mkdir /lvmtest
echo "/dev/storage/vo /lvmtest xfs defaults 0 0" >> /etc/fstab
mount -a
df -h
扩展
- 只要卷组中有足够的资源,就可以一直为逻辑卷扩容
- 卷组中没有资源了,可以在PV中添加,然后再添加到卷组中
- 扩展前需要卸载设备
# 先卸载
umount /lvmtest
# 扩展逻辑卷(由150M到300M)
lvextend -L 300M /dev/storage/vo
# 检查硬盘完整性,并重置硬盘容量(至关重要)
e2fsck -f /dev/storage/vo
resize2fs /dev/storage/vo
# 重新挂载硬盘设备并查看挂载状态
mount -a
df -h
缩小
- 在对逻辑卷进行缩容操作时,其丢失数据的风险更大,在生产环境中执行相应操作时,一定要提前备份好数据
- 在对LVM逻辑卷进行缩容操作之前,要先检查文件系统的完整性,这是为了保证数据安全
- 在执行缩容操作前,和扩展一样,需要先把文件系统卸载掉
# 先卸载
umount /lvmtest
# 检查文件系统的完整性
e2fsck -f /dev/storage/vo
# 把逻辑卷vo的容量减小到200MB
resize2fs /dev/storage/vo 200M
lvreduce -L 200M /dev/storage/vo
# 重新挂载文件系统并查看系统状态
mount -a
df -h
逻辑卷快照
LVM具有快照卷功能,类似于虚拟机软件的还原时间点功能,有两个特点:
- 快照卷的容量必须等同于逻辑卷的容量
- 快照卷仅一次有效,一旦执行还原操作后则会被立即自动删除
# 查看卷组的信息
vgdisplay
# 生成快照卷
# -s生成快照卷,-L指定切割的大小
lvcreate -L 200M -s -n SNAP /dev/storage/vo
lvdisplay
# 快照还原
umount /lvmtest
lvconvert --merge /dev/storage/SNAP # 快照卷会被自动删除掉
mount -a
删除逻辑卷
重新部署LVM或者不再需要使用LVM时,则需要执行LVM的删除操作。
需要提前备份好重要的数据信息,然后依次删除逻辑卷、卷组、物理卷设备,这个顺序不可颠倒
# 先卸载,并删除配置
umount /lvmtest
vim /etc/fstab
# 删除/dev/storage/vo /lvmtest xfs defaults 0 0
# 删除逻辑卷设备
lvremove /dev/storage/vo
y
# 删除卷组,此处只写卷组名称即可,不需要设备的绝对路径
vgremove storage
# 删除物理卷设备
pvremove /dev/sdb /dev/sdc