交换机
工作原理
交换机根据数据帧的源MAC来学习,构建CAM表项(MAC地址和端口的映射关系),根据目的MAC地址来进行转发(根据CAM表项来进行转发)
五种基本操作
- 学习MAC地址,根据源MAC构建CAM表项
- 删除MAC,默认300秒(aging-time),300秒后如果没有收到更新,就会删除
- 泛洪,如果MAC地址不在CAM表项中则会泛洪。广播只是泛洪 行为中的的其中 一种
BUM报文。B,Broadcast,ff-ff-ff-ff-ff-ff;U,未知单播帧, 第一组第八位为0是单播;M,组播 ,第一组第八位为1是组播,01-00-5e、01-80-c2、 33-33-33 - 转发,根据目的MAC,查找CAM表项进行转发
- 过滤,端口安全,交换机不会将数据帧从接收端口发送出去,如果数据帧中的CRC校验失败,也会丢弃
##端口类型
交换机三种端口模式Access、Hybrid和Trunk的理解
端口有三种模式:access,hybrid,trunk。
Access类型端口
只能属于1个VLAN,且该端口不打tag,一般连接主机,只用于接入链路
只允许与该端口的PVID相同的VLAN通过,收到untagged的数据帧,强制打上本端口PVID的标签;
Trunk类型端口
可以允许多个VLAN通过,且该端口都是打tag的,这个端口是交换机之间或者交换机和上层设备之间的通信端口,用于干道链路。这种端口的存在就是为了多个vlan的跨越交换机进行传递。
一个trunk端口可以拥有一个主vlan和多个副vlan。在交换机之间传递tagged frame。允许多个VLAN通过,可以与PVID不同;收到不带tagged frame的数据帧时,打上主PVID并转发;收到带tagged frame数据帧时,检查VLAN ID,如果允许并且VLAN ID与PVID相同,去掉tagged直接转发,如果允许并且VLAN ID与PVID不同,直接转发原数据帧。
Hybrid类型端口
可以允许多个VLAN通过,至于该端口在vlan中是否打tag由用户根据具体情况而定,可以用于交换机之间的连接也可以用于交换机和用户计算机之间的连接。
此端口的转发模式与trunk端口一样,允许多个VLAN通过,收到不带tagged frme,打上pvid标签并转发。收到带tagged frame时,如允许并且VLAN ID与PVID相同,除去标签转发,如允许并且VLAN ID与PVID不同,直接转发。hybrid允许多个VLAN报文不打标签发送,但是trunk端口只允许与自己PVID相同的VLAN报文发送时不打标签;当Hybrid端口没有tagged VLAN,untagged VLAN只有一个时,功能与access端口一样;当Hybrid端口没有untagged VLAN时,功能与trunk端口一样。
trunk和hybrid的区别主要是,hybrid端口可以允许多个vlan的报文不打标签,而 trunk端口只允许缺省vlan的报文不打标签,同一个交换机上不能hybrid和trunk并存
Access类型的接口仅属于一个VLAN,只能接收、转发相应VLAN的帧;Trunk类型接口则默认属于所有VLAN,任何 Tagged 帧都能经过Trunk接收和转发;Hybrid类型接口则介于二者之间,可自主定义端口上能接收和转发哪些VLANTag 的帧,并可决定VLANTag 是否继续携带或者剥离。Access和 Trunk 类型接口是Hybrid 类型接口的两个特例,一个仅支持一个VLAN的传递,一个默认支持所有VLAN的传递,而Access类型和Trunk类型的接口能做到的,Hybrid 接口都能做到。
Mux Vlan
Mux Vlan提供了一种在VLAN的端口间进行二层流量隔离的机制。
MUX VLAN 分为主VLAN和从VLAN,从VLAN又分为互通型从VLAN 和隔离型从VLAN。主VLAN与从VLAN之间可以相互通信;互通型从VLAN内的端口之间可以互相通信,隔离型从VLAN内的端口之间不能互相通信,不同从VLAN之间不能互相通信。
ARP代理
ARP用于将一个IP地址映射到正确的MAC地址。一个物理网络的子网(Subnet)中的源主机向另一个物理网络的子网中的目的主机发ARP request,和源主机直连的网关用自己接口的MAC地址代替目的主机回ARP reply,这个过程称为ARP 代理。
Proxy ARP有以下特点:
- 所有处理在ARP子网网关进行,所连网络中的主机不必做任何改动;
- 在主机端看不到子网,只是一个标准IP网络;
- Proxy ARP只影响主机的ARP高速缓存,对网关的ARP高速缓存和路由表没有影响;
- 使用Proxy ARP后,主机应该减小ARP老化时间,以尽快使无效ARP项失效,减少发给路由器而路由器却不能转发的报文
交换机开启arp代理:arp-proxy enable
路由式的ARP代理, 实现在没有配置网关的情况下,进行代理实现互通
Inter-arp proxy实现Super-vlan互通
Inner-arp proxy实现端口隔离的互通
Super Vlan(Vlan聚合)
VLAN聚合,只在super-VLAN接口上配置IP地址,而不必为每个sub-VLAN分配IP地址。所有sub-VLAN 共用IP网段,解决了IP地址资源浪费的问题。
端口隔离
端口隔离是交换机端口之间的一种访问控制安全控制机制。
实现不同端口接入的PC之间不能互访(PC属于相同的vlan),而所有的PC都能通过上行的交换机访问网络。
可以配置vlan内的用户间的相互隔离或者互通,端口隔离则是物理层次上的隔离,是基于端口。
vlan mapping(VLAN映射)
将用户报文中的私网VLAN Tag替换为公网的VLAN Tag,使其按照公网的网络规划进行传输。在报文被发送到对端用户私网时,再按照同样的规则将VLAN Tag恢复为原有的用户私网VLAN Tag,使报文正确到达目的地。
在交换机接收到带有用户私网报文的VLAN Tag后,首先根据配置的映射规则对用户私网报文的VLAN Tag进行匹配,如果匹配成功,则按照规则将私网VLAN Tag进行替换。
映射方式
1 to 1的映射方式
当部署VLAN Mapping功能设备上的主接口收到带有单层VLAN Tag的报文时,将报文中携带的单层VLAN Tag映射为公网的VLAN Tag。包括1:1和N:1两种方式,其中1:1的方式是将指定的一个用户侧VLAN Tag标签映射到一个网络侧VLAN Tag标签,N:1的方式是将指定范围的多个用户侧VLAN Tag标签映射到一个网络侧VLAN Tag标签。
2 to 1的映射方式
当部署VLAN Mapping功能设备上的主接口收到带有双层VLAN Tag的报文时,将报文中携带的外层Tag映射为公网的Tag,内层Tag作为数据透传。
2 to 2的映射方式
当部署VLAN Mapping功能设备上的主接口收到带有双层VLAN Tag的报文时,将报文中携带的双层VLAN Tag映射为公网的双层VLAN Tag。
基于MQC实现VLAN Mapping指的是通过MQC可以对分类后的报文实现VLAN Mapping。
用户可以根据多种匹配规则对报文进行流分类,然后将流分类与VLAN Mapping的动作相关联,对匹配规则的报文重标记报文的VLAN ID值。基于MQC的VLAN Mapping能够针对业务类型提供差别服务。
# 配置vlan mapping
int g0/0/2
qinq vlan-translation enable # 使能接口的vlan转换功能
port link-type trunk
port trunk allow-pass vlan 100
port vlan-mapping vlan 10 to 20 map-vlan 100 # 将vlan10到20全部转换成vlan100
QinQ
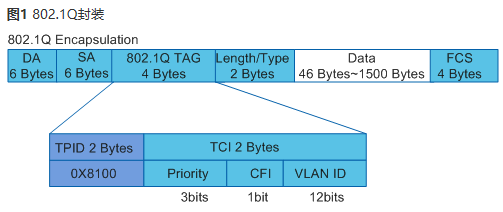
基于802.1 Q封装的隧道协议,报文封装双层VLAN Tag
有点
- 解决日益紧缺的公网VLAN ID资源问题
- 用户可以规划自己的私网VLAN ID
- 提供一种较为简单的二层VPN解决方案
- 使用户网络具有较高的独立性
分类(按照实现方式)
- 基于端口的QinQ:基于端口的基本QinQ
- 灵活QinQ:VLAN Stacking
- 基于流的灵活QinQ:基于ACL的灵活QinQ
TPID
标签协议标识TPID是vlan tag中的一个字段,表示vlan tag的协议类型,IEEE 802.1Q协议规定该字段的取值为0x8100
不同运营商的系统可能将QinQ帧外层VLAN标记的TPID设置为不同值。为实现与这些系统的兼容性,可以修改TPID值,使QinQ帧发送到公网时,承载与特定运营商相同的TPID值,从而实现与该运营商设备之间的互操作性。以太网帧的TPID与不带VLAN标记的帧的协议类型字段位置相同。为避免在网络中转发和处理数据包时出现问题,不可将TPID值设置为下表中的任意值:
# 基于端口的QinQ
interface GigabitEthernet0/0/2
port link-type dot1q-tunnel # 配置为QinQ模式
port default vlan 100 # 指定外层tag
# 灵活的QinQ
interface GigabitEthernet0/0/2
qinq vlan-translation enable # 开启vlan转换功能
port hybrid untagged vlan 100 200 # 收到vlan100和200的数据之后去掉vlan tag100和200
port vlan-stacking vlan 10 to 20 stack-vlan 100 # 收到vlan10-20的数据之后,加上vlan tag 100
port vlan-stacking vlan 30 to 40 stack-vlan 200
# 修改TPID配置
interface GigabitEthernet0/0/1
port link-type trunk
port trunk allow-pass vlan 100
qinq protocol 9100
链路聚合
链路聚合是将—组物理接口捆绑在一起作为一个逻辑接口来增加带宽的一种方法,又称为多接口负载均衡组或链路聚合组,相关的协议标准请参考IEEE802.3ad。
配置手工负载分担模式链路聚合
- 当需要增加两台设备之间的带宽或可靠性,而两台设备中有一台不支持LACP协议时,可在Switch设备上创建手工负载分担模式的Eth-Trunk,并加入多个成员接口增加设备间的带宽及可靠性。
- Eth-Trunk的创建、成员接口的加入都需要手工配置完成,没有LACP协议报文的参与。
- 手工负载分担模式允许在聚合组中手工加入多个成员接口,所有的接口均处于转发状态,分担负载的流量。
- 手工负载分担没有协议的交互
在物理成员接口下接入eth-trunk
- 每个Eth-Trunk接口下最多可以包含8个成员接口。
- 成员接口不能配置任何业务和静态MAC地址,即成员接口加入Eth-Trunk时,必须为缺省的hybrid类型接口。
- Eth-Trunk接口不能嵌套,即成员接口不能是Eth-Trunk。
- 一个以太网接口只能加入到一个Eth-Trunk接口,如果需要加入其它Eth-Trunk接口,必须先退出原来的Eth-Trunk接口。
- 一个Eth-Trunk接口中的成员接口必须是同一类型,例如:FE口和GE口不能加入同一个Eth-Trunk接口。
- 可以将不同接口板上的以太网接口加入到同一个Eth-Trunk。
- 如果本地设备使用了Eth-Trunk,与成员接口直连的对端接口也必须捆绑为Eth-Trunk接口,两端才能正常通信。
- 当成员接口的速率不一致时,实际使用中速率小的接口可能会出现拥塞,导致丢包。
- 当成员接口加入Eth-Trunk后,学习MAC地址时是按照Eth-Trunk来学习的,而不是按照成员接口来学习
修改eth-trunk负载分担方式
- dst-ip(目的IP地址)模式:从目的IP地址、出端口的TCP/UDP端口号中分别选择指定位的3bit数值进行异或运算,根据运算结果选择Eth-Trunk表中对应的出接口。
- dst-mac(目的MAC地址)模式:从目的MAC地址、VLAN ID、以太网类型及入端口信息中分别选择指定位的3bit数值进行异或运算,根据运算结果选择Eth-Trunk表中对应的出接口。
- src-ip(源IP地址)模式:从源IP地址、入端口的TCP/UDP 端口号中分别选择指定位的3bit数值进行异或运算,根据运算结果选择Eth-Trunk表中对应的出接口。
- src-mac(源MAC地址)模式:从将源MAC地址、VLAN ID、以太网类型及入端口信息中分别选择指定位的3bit数值进行异或运算,根据运算结果选择Eth-Trunk表中对应的出接口。
- src-dst-ip(源IP地址与目的IP地址的异或)模式:从目的IP地址、源IP地址两种负载分担模式的运算结果进行异或运算,根据运算结果选择Eth-Trunk表中对应的出接口。
- src-dst-mac(源MAC地址与目的MAC地址的异或)模式:从目的MAC地址、源MAC地址、VLAN ID、以太网类型及入端口信息中分别选择指定位的3bit数值进行异或运算,根据运算结果选择Eth-Trunk表中对应的出接口。
#配置手工负载分担模式链路聚合
# sw1/2
# 方法一:配置聚合后加入端口
int Eth-Trunk 10
trunkport g0/0/1 to 0/0/4
# 方法二:在接口下加入eth-trunk
int Eth-Trunk 10
q
int g0/0/1
# port-group group-member g0/0/1 to g0/0/4
eth-trunk 10
int g0/0/2
eth-trunk 10
int g0/0/3
eth-trunk 10
int g0/0/4
eth-trunk 10
# 设置活动连接数
interface Eth-Trunk10
port link-type trunk
port trunk allow-pass vlan 2 to 4094
least active-linknumber 2 # 如果活动链接数低于该值,聚合组直接down
max bandwidth-affected-linknumber # 设置最大活动链接数
配置静态LACP模式链路聚合
静态LACP模式也称为M∶N模式。这种方式同时可以实现链路负载分担和链路冗余备份的双重功能。在链路聚合组中M条链路处于活动状态,这些链路负责转发数据并进行负载分担,另外N条链路处于非活动状态作为备份链路,不转发数据。当M条链路中有链路出现故障时,系统会从N条备份链路中选择优先级最高的接替出现故障的链路,同时这条替换故障链路的备份链路状态变为活动状态开始转发数据。
静态LACP模式与手工负载分担模式的主要区别:静态LACP模式有备份链路,而手工负载分担模式所有成员接口均处于转发状态,分担负载流量
# 配置静态LACP模式链路聚合
int Eth-Trunk 10
port link-type trunk
port trunk allow-pass vlan 2 to 4094
mode lacp-static
trunkport g0/0/1 to 0/0/4
least active-linknumber 2 # 最小活动连接数
max active-linknumber 3 # 最大活动连接数
lacp preempt enable # 开启抢占,即接口恢复正常后按照优先级进行抢占
lacp preempt delay 10 # 配置抢占延时,接口UP后10秒钟后,进行抢占 (防止链路震荡)
q
lacp priority 100 # 修改设备的LACP优先级,优先级小的成为主动端
int g0/0/1
lacp priority 40000 # 修改接口的LACP 优先级,优先级小的会被选择
# mixed-rate link enable:命令用来使能允许端口支持速率不同的接口加入同一Eth-Trunk接口的功能。
STP
生成树的工作原理:生成树的最终目的是用来破环的
工作流程
- 先要选举出一个根桥RB(皇帝),在整个交换网络中选举的,用来发送BPDU报文(圣旨)
- 选举出根端口(RP)(在每一个非根交换机上选举出一个)(太守),用来接收BPDU报文的(圣旨)
- 选举出指定端口(DP)(在每条链路上都要选举出一个指定端口)(钦差),用来发放或转发BDPU报文
- 非根端口,非指定端口,会成为预备端口(AP),会被阻塞
根桥RB的选举
比较BridgeID,有三部分级成:优先级+扩展系统ID+MAC,华为的扩展系统ID是0
比较优先级,优先级低成为根桥;如果优先级相同,比较MAC地址,MAC地址小的成为根桥。
优先级为0,仅是最大可能会成为根桥,不一定是根桥。
stp root primary # 思科做法是把最小的优先级减去8192,华为直接置为0
stp root secondary # 思科做法是把最小的优先级减去4096,华为直接置为4096
根端口RP的选举(用来接收BPDU)
通俗选法:选离RB距离最近的那个
- 比较到达根桥最小路径开销值(RPC)
- 比较转发该BPDU的BridgeID,越小越优
- 比较转发该BPDU报文的PortID:端口优先级+端口编号,即优先级越小越优,如果优先级相同;比较端口编号
- 比较接收该BPDU报文的PortID:端口优先级+端口编号,即优先级越小越优,如果优先级相同;比较端口编号
指定端口DP的选举(用来发送BPDU)
和RP选举规则相同,通俗选法:RP对面的端口一定是DP
- 比较到达根桥最小路径开销值(RPC)
- 比较转发该BPDU的bridge ID,越小越优
- 比较转发该BPDU报文的PortID:端口优先级+端口编号,优先级越小越优,如果优先级相同,比较端口编号
- 比较接收该BPDU报文的Port ID:端口优先级+端口编号,优先级越小越优,如果优先级相同,比较端口编号
根桥的接口默认都是DP,但根桥的接口不一定全部都是DP,有可能是AP(思科)或BP(华为)
AP的选举(阻塞端口)
非DP,非RP就是AP,端口会被阻塞掉
STP的两种报文
- 配置BPDU(STP的BPDU发送(组播)地址:01-80-C2-00-00-00)
- TCN报文(拓扑变更通知)

调整设备的RP端口
- 调整转发端口的开销值
stp instance 0 cost 30000 - 调整接收端口的优先级
stp priority 8192
可能的临时环路
在端口角色以及状态的变化过程中,可能会出现临时环路问题。
解决临时环路的方法: 在一个端口从不转发状态进入之前,需要等待一个足够长的时间 ,以使需要进入不转发状态的端口有足够时间完后才能生成树计算,并进入不转发状态
端口状态转换
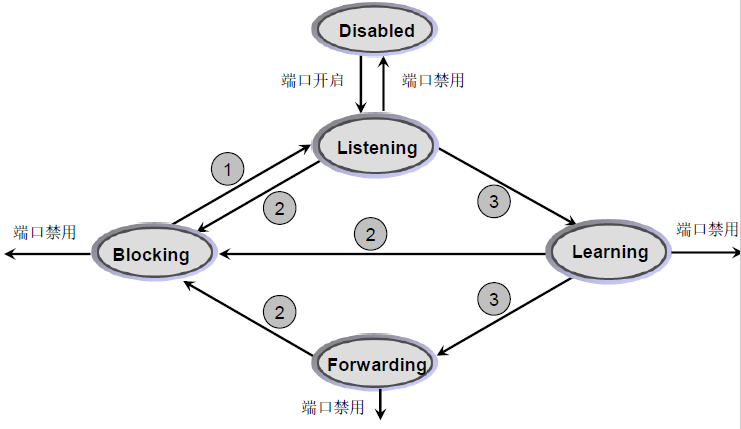
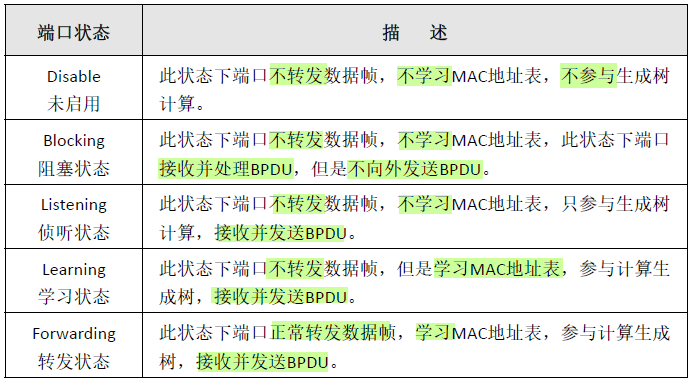
华为将disable、blocking和listening三种状态合并为discarding状态
1:端口被选为指定DP或根端口RP;
2:端口被选为预备端口AP;
3:经过Forward Delay间隔,默认为 15 秒。
端口被禁用之后进入Disable状态。
当一个端口从不转发状态进入状态之前需要等待两次 Forward Delay间隔 ,以解决前文所述可能的临时环路问题。
拓扑结构改变导致MAC地址表错误
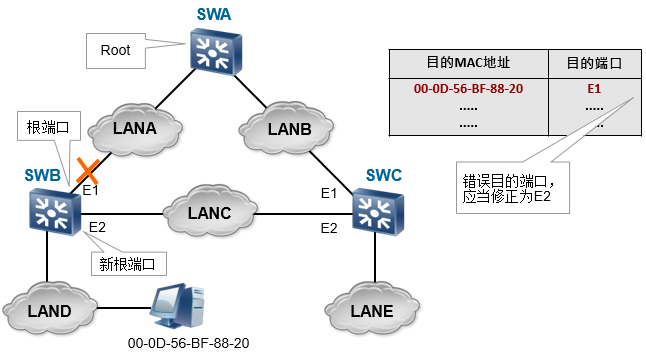
默认情况下,MAC地址表中的动态表项生存期为300秒(5分钟)
稳定拓扑下,在SWC上到达LAND某PC的目的端口应当为E1;
当SWB的E1接口断开之后,E2接口成为新的根端口,从SWC到达该PC的目的地址应当修改为E2,但是交换机不能检测到拓扑改变,导致MAC地址表错误,最长可导致5分钟的数据转发错误。
解决问题的办法:当拓扑结构改变之后,通过一定的机制,使拓扑改变的信息在整网内泛洪,并修改MAC地址表的生存期为一个较短的数值,等拓扑结构稳定之后,再恢复MAC地址表的生存期。STP规定这个较短的MAC地址表生存期使用交换机的Forward Delay参数,默认为15秒
端口改变所在的交换机(RP端口)给上级发TCN报文(TC=1,表示拓扑改变),直到当RB收到该报文之后,全网泛洪配置BPDU(TCA=1,表示拓扑改变响应),进行重新选举
TC=1的BPDU会发送多长时间?37秒=MaxAge(20s)+ForwardDelay(15s)+Hello(2s),共计18个报文
所有交换机在收到TC=1的报文之后会将MagAge时间由300秒调整为15秒
泛洪拓扑改变信息
在向整网泛洪拓扑改变信息的过程中,共涉及三 种BPDU:
- 拓扑改变通知BPDU:用于非根交换机在根端口上向上行交换机通告拓扑改变信息,并且每隔Hello Time(2秒)发送一次,直到收到上行交换机的拓扑改变确认配置BPDU或者拓扑改变配置BPDU。
- 拓扑改变确认配置BPDU:配置BPDU的一种,和普通配置BPDU不同的是此配置BPDU设置了一个Flag位。用于非根交换机在接收到拓扑改变通知BPDU的指定接口上向下行交换机发送拓扑改变通知的确认信息。
- 拓扑改变配置BPDU:此配置BPDU设置了另外 一个Flag位。用于从根交换机向整网泛洪拓扑改变信息,所有交换机都在自己所有的指定端口上泛洪此BPDU。
STP的缺点
- 收敛慢,至少需要30s
- 发生了拓扑变更,至少需要30s才能收敛
- 端口角色只有三种,端口状态却有五种
- STP需要一个max age时间(20s)才能感受到线路变化,端口状态变化需要30s,则恢复通信需要50s(非直连,直连只需要30s的端口状态变化时间)。
RSTP
RSTP对STP的改进
- 端口角色从三种变为五种
STP:DP、RP 、AP
RSTP:DP 、RP、AP(预备端口)、BP(指定端口的备份)、EP(边缘端口)
AP是RP的备份,BP是DP的备份 - 端口状态 五种变为三种
Discarding、Learning、Forwarding - BPDU格式的变化--flag位的变化
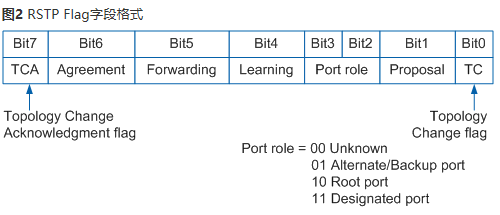
- 第0位为TC标志位,和STP相同。
- 第1位为Proposal标志位,该位置位表示该BPDU为快速收敛机制中的Proposal报文。
- 第2位和第3位为端口角色标志位,
00表示端口角色为未知;
01表示端口角色为Alternate或Backup端口(AP或BP);
10表示端口为根端口;
11表示端口为指定端口。 - 第4位为Learning标志位,该位置位表示端口处于Learning状态。
- 第5位为Forwarding标志位,该位置位表示端口处于Forwarding状态。
- 第6位为Agreement标志位,该位置位表示该BPDU位快速收敛机制中的Agreement报文。
- 第7位为TCA标志位,和STP相同。
0和7是一组,1和6是一组,2和3是一组,4和5是一组
快速收敛
Proposal/Agreement机制
当一个端口被选举成为指定端口DP之后,在STP中,该端口至少要等待一个Forward Delay(Learning)时间才会迁移到Forwarding状态。而在RSTP中,此端口会先进入Discarding状态,再通过Proposal/Agreement机制快速进入Forward状态。这种机制必须在点到点全双工链路上使用。
Proposal/Agreement机制,其目的是使一个指定端口尽快进入Forwarding状态。如图所示,根桥S1和S2之间新添加了一条链路。在当前状态下,S2的另外几个端口p2是Alternate端口,p3是指定端口且处于Forwarding状态,p4是边缘端口。
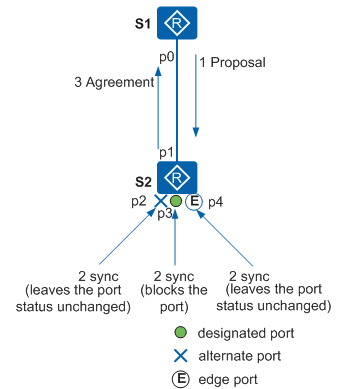
新链路连接成功后,P/A机制协商过程如下:
- p0和p1两个端口马上都先成为指定端口,发送RST BPDU。
- S2的p1口收到更优的RST BPDU,马上意识到自己将成为根端口,而不是指定端口,停止发送RST BPDU。
- S1的p0进入Discarding状态,于是发送的RST BPDU中把proposal置1。
- S2收到根桥发送来的携带proposal的RST BPDU,开始将自己的所有端口进入sync变量置位。
- p2已经阻塞,状态不变;p4是边缘端口,不参与运算;所以只需要阻塞非边缘指定端口p3。
- p2和p3都进入Discarding状态之后,端口的synced变量置位,根端口p1的synced也置位,于是便向S1返回Agreement位置位的回应RST BPDU。该RST BPDU携带和刚才根桥发过来的BPDU一样的信息,除了Agreement位置位之外(Proposal位清零)。
- 当S1判断出这是对刚刚发出的Proposal的回应,于是端口p0马上进入Forwarding状态。
下游设备继续执行P/A协商过程。
事实上对于STP,指定端口的选择可以很快完成,主要的速度瓶颈在于:为了避免环路,必须等待足够长的时间,使全网的端口状态全部确定,也就是说必须要等待至少一个Forward Delay所有端口才能进行转发。而RSTP的主要目的就是消除这个瓶颈,通过阻塞自己的非根端口来保证不会出现环路。而使用P/A机制加快了上游端口转到Forwarding状态的速度。
协商机制的前提-点到点链路
使用“Proposal-Agreement”的前提是泛洪这两种消息的链路均为点到点链路,点到点链路是指两个交换机直接相连的链路。之所以必须使用点到点链路是因为点到多点链路有环路风险。
# 开启全局边缘端口
[Huawei]stp edged-port default
# 开启端口下边缘端口
interface GigabitEthernet0/0/4
stp edged-port enable
# 如果全局开启边缘端口且开启了BPDU保护功能,需要将连接交换机的上连接口(trunk接口)关闭边缘端口功能
根端口快速切换机制
如果网络中一个根端口RP失效,那么网络中最优的Alternate端口AP将成为根端口,进入Forwarding状态。因为通过这个Alternate端口连接的网段上必然有个指定端口可以通往根桥。这种产生新的根端口的过程会引发拓扑变化,详细描述请见RSTP技术细节中的RSTP拓扑变化处理。
边缘端口的引入
在RSTP里面,如果某一个指定端口位于整个网络的边缘,即不再与其他交换设备连接,而是直接与终端设备直连,这种端口叫做边缘端口EP。边缘端口不接收处理配置BPDU,不参与RSTP运算,可以由Disable直接转到Forwarding状态,且不经历时延,就像在端口上将STP禁用。但是一旦边缘端口收到配置BPDU,就丧失了边缘端口属性,成为普通STP端口,并重新进行生成树计算,从而引起网络震荡。
RSTP拓扑变化处理
在RSTP中检测拓扑是否发生变化只有一个标准:一个非边缘端口迁移到Forwarding状态。
一旦检测到拓扑发生变化,将进行如下处理:
- 首先清空状态发生变化的端口上学习到的MAC地址。
- 同时在2倍的hello time时间内不断向非边缘端口发送TC置位的RST BPDU。
- 其他设备收到TC置位的RST BPDU后,清空其他所有端口学习到的MAC地址(除了收到RST BPDU的端口)。同时也会从自己的非边缘端口和根端口向外泛洪TC置位的 RST BPDU。
RSTP中配置BPUD的处理
- 非根桥设备每隔Hello Timer从指定端口主动发送配置BPDU
- BPDU超时计时器为3个Hello Timer
- 阻塞端口可以立即对收到的次级BPDU进行回应
根端口快速切换机制
网桥根端口失效,且对端网桥指定端口依然为转发状态,则该网桥Alternate端口直接进入转发状态
RSTP与STP互操作
- RSTP端口在接收到STP BPDU的两个hello timer后,会切换到STP工作模式
- 切换到STP协议的RSTP端口会丧失快速收敛等特性
- 当运行STP的设备从网络撤离后,原运行RSTP的交换设备上的相应端口(连接STP设备的端口)可迁移回到RSTP工作模式
如果边缘端口收到BPDU报文,会失去边缘端口特性,变为普通接口
BPDU保护和BPDU Filture
BPDU保护和BPDU Filture一般都是与边缘端口EP配合使用
边缘端口EP即发也收BPDU,EP+BPDU保护只发不收BPDU,EP+BPDU Filture不收也不发BPDU
- 什么情况配置BPDU保护
- 没有办法保证接入端一定是终端设备
- 为了防止其他非法设备抢占根桥RB
- 什么情况配置BPDU Filture
stp bpdu-filter enable- 不收也不发BPDU
- 防止自己去抢别人根桥
根保护
stp root-protection
防止自己的根桥被抢占,一般配置在DP接口
一旦启用Root保护功能的指定端口收到优先级更高的RST BPDU时,端口状态将进入Discarding状态,不再转发报文。在经过一段时间(通常为两倍的Forward Delay),如果端口一直没有再收到优先级较高的RST BPDU,端口会自动恢复到正常的Forwarding状态。
Root保护功能只能在指定端口DP上配置生效
环路保护
stp loop-protection
在启动了环路保护功能后,如果根端口或Alternate端口长时间收不到来自上游设备的BPDU报文时,则向网管发出通知信息(此时根端口会进入Discarding状态,角色切换为指定端口),而Alternate端口则会一直保持在阻塞状态(角色也会切换为指定端口),不转发报文,从而不会在网络中形成环路。直到链路不再拥塞或单向链路故障恢复,端口重新收到BPDU报文进行协商,并恢复到链路拥塞或者单向链路故障前的角色和状态。
环路保护功能只能在根端口RP和预备端口AP上配置生效
防TC-BPDU报文攻击
stp tc-protection threshold 1 # 默认为1
交换设备在接收到TC BPDU报文后,会执行MAC地址表项和ARP表项的删除操作。
如果有人伪造TC BPDU报文恶意攻击交换设备时,交换设备短时间内会收到很多TC BPDU报文,频繁的删除操作会给设备造成很大的负担,给网络的稳定带来很大隐患。
启用防TC-BPDU报文攻击功能后,在单位时间内,交换设备处理TC BPDU报文的次数可配置。
如果在单位时间内,交换设备在收到TC BPDU报文数量大于配置的阈值,那么设备只会处理阈值指定的次数。对于其他超出阈值的TC BPDU报文,定时器到期后设备只对其统一处理一次。这样可以避免频繁的删除MAC地址表项和ARP表项,从而达到保护设备的目的。
MSTP
RSTP和STP还存在同一个缺陷:由于局域网内所有的VLAN共享一棵生成树,因此无法在VLAN间实现数据流量的负载均衡,链路被阻塞后将不承载任何流量,造成带宽浪费,还有可能造成部分VLAN的报文无法转发。
实例就是多个VLAN的一个集合。通过将多个VLAN捆绑到一个实例,可以节省通信开销和资源占用率。MSTP各个实例拓扑的计算相互独立,在这些实例上可以实现负载均衡。可以把多个相同拓扑结构的VLAN映射到一个实例里,这些VLAN在端口上的转发状态取决于端口在对应MSTP实例的状态。
MST区域
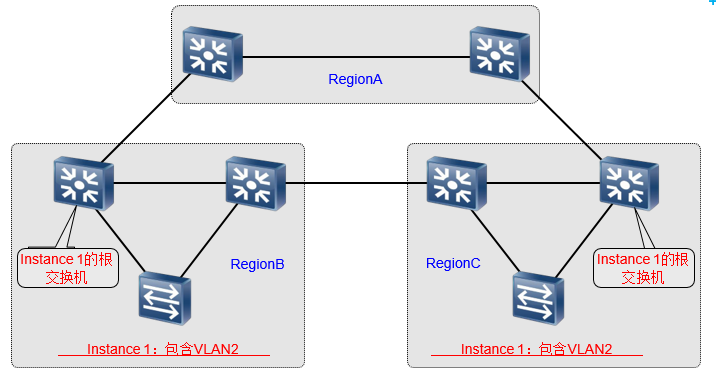
MSTP允许一组相邻的交换机组成一个MST区域(MST Region)。同一个区域的交换机有着相同的VLAN到MST Instance的映射关系。除了Instance 0之外,每个区域的MST Instance都独立计算生成树,不管是否包含相同的VLAN,不管VLAN是否通过区域间链路,区域间的生成树计算互不影响。
MSTP域
MSTP域,具有相同元素网桥的集合:使能MSTP,相同域名,相同VLAN映射,相同的修订级别
CST/IST/CIST/总根/主桥/MSTI/MSTI域根
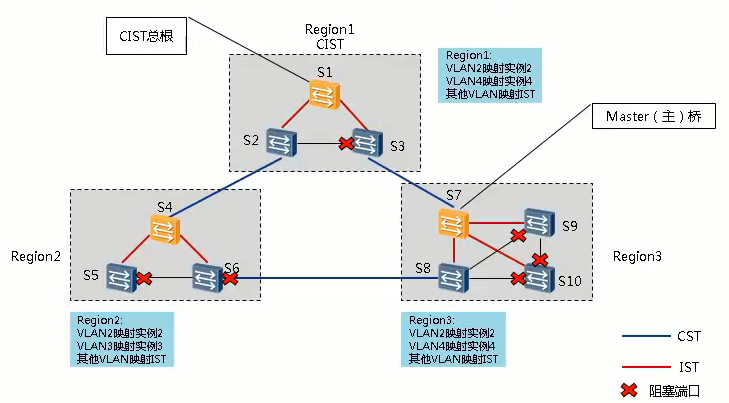
- CIST公共和内部生成树CIST是通过STP或RSTP协议计算生成的,连接一个交换网络内所有交换设备的单生成树。
- 总根是整个网络中优先级最高的网桥,即为CIST的根桥。
- 拓扑中,MST域内的红线和MST域间的蓝线共同组成了CIST。CIST的根桥为MST Region1中的S1。
- CST公共生成树CST(Common Spanning Tree)是连接交换网络内所有MST域的一棵生成树。
- CST就是这些节点通过STP或RSTP协议计算生成的一棵生成树。
- 拓扑中,由蓝线组成CST。CST的根即为MST Region1。
- 内部生成树IST(Internal Spanning Tree)是各MST域内的一棵生成树。
- MST域内每颗生成树都对应一个实例号,IST的实例号为0。实例0无论有没有配置都是存在的,没有映射到其他实例的VLAN默认都会映射到实例0,即IST上。
- IST是CIST在MST域中的一个片段。拓扑中,由红线组成IST。
- 主桥(Master Bridge)也就是IST Master,它是域内距离总根最近的交换设备。
- 如果总根在MST域中,则总根为该域的主桥。
- 拓扑中,Master桥为黄色的网桥,即为S1/S4/S7。
- 构成单生成树SST(Single Spanning Tree)有两种情况:
- 运行STP或RSTP的交换设备只能属于一个生成树。
- MST域中只有一个交换设备,这个交换设备构成单生成树。
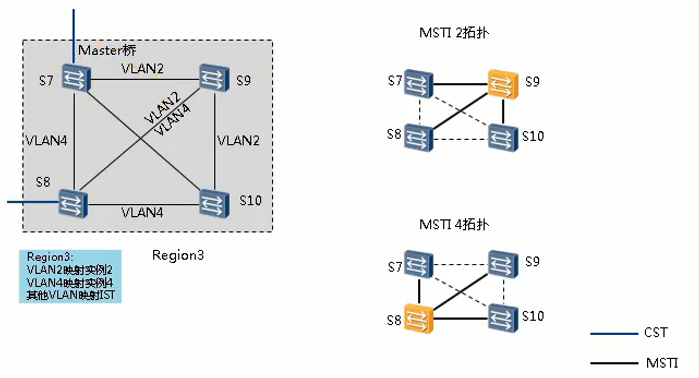
- MSTI
- 一个MST域内可以生成多棵生成树,每棵生成树都称为一个MSTI。MSTI域根是每个多生成树实例的树根。域中不同的MSTI有各自的域根。
- MSTI之间彼此独立,MSTI可以与一个或者多个VLAN对应。但一个VLAN只能与一个MSTI对应。
- 每一个MSTI对应一个实例号,实例号从1开始,以区分实例号为0的IST。
- 拓扑中,VLAN2映射到实例2,即MSTI 2;VLAN4映射到实例4,即MSTI 4。
- MSTI域根
- MSTI域根是每个MSTI上优先级最高的网桥,MST域内每个MSTI可以指定不同的根。
- 拓扑中,假设S9在MSTI 2中优先级最高,所以S9为MSTI 2中的域根;假设S8在MSTI 4中优先级最高,所以S8为MSTI 2中的域根。
MSTP端口角色
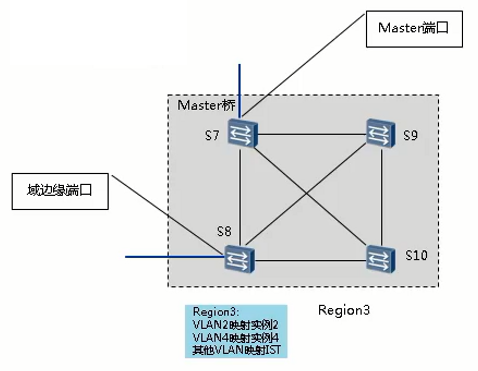
MSTP在RSTP的基础上新增了2种端口,MSTP的端口角色共有7种:根端口、指定端口、Alternate端口、Backup端口、边缘端口、Master端口和域边缘端口。
Master端口
- Master端口是MST域和总根相连的所有路径中最短路径上的端口,它是交换设备上连接MST域到总根的端口。
- Master端口是域中的报文去往总根的必经之路。
- Master端口是特殊域边缘端口,Master端口在CIST上的角色是Root Port,在其它各实例上的角色都是Master端口。
- 拓扑中,S7面向Region 1的端口为Master口。
域边缘端口
- MST域内网桥和其他MST域或者STP/RSTP网桥相连的端口为域边界端口。
- 拓扑中,S8面向Region 2的端口为域边界端口。
由于网桥在不同MSTI上可以具有不同的角色,所以网桥端口在MSTI上可能有不同的角色。唯一例外的是Master端口,该端口在所有MSTI上的角色都相同,都为Master端口。
MSTP和RSTP交互
RSTP/STP网桥将MSTP域看做一个桥ID为域根ID的RSTP桥。
当RSTP/STP网桥收到MSTP的BPDU后,会提取BPDU中的总根、外部路径开销、域根ID、指定端口ID作为RSTP/STP的(RID、RPC、BID、PID)
当MSTP网桥收到RSTP/STP的BPDU后,会将BPDU中的(RID、RPC、BID、PID)对应到MSTP中,其中BID作为MSTP中的域根ID,也作为指定交换机ID,内部路径开销为0.
MSTP拓扑计算--比较原则
首先,比较根交换设备ID。
如果根交换设备ID相同,再比较外部路径开销。
如果外部路径开销相同,再比较域根ID。
如果域根ID仍然相同,再比较内部路径开销。
如果内部路径仍然相同,再比较指定交换设备ID。
如果指定交换设备ID仍然相同,再比较指定端口ID。
如果指定端口ID还相同,再比较接收端口ID。
MSTP快速收敛
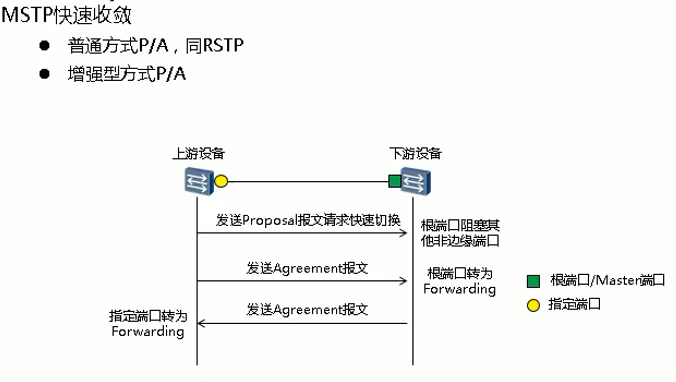
在MSTP中,P/A机制工作过程如下:
- 上游设备发送Proposal报文,请求进行快速迁移。下游设备接收到后,把与上游设备相连的端口设置为根端口,并阻塞所有非边缘端口。
- 上游设备继续发送Agreement报文。下游设备接收到后,根端口转为Forwarding状态。
- 下游设备回应Agreement报文。上游设备接收到后,把与下游设备相连的端口设置为指定端口,指定端口进入Forwarding状态。
缺省情况下,华为使用增强的快速迁移机制。如果华为设备与其他厂商的设备进行互通,而其他厂商的设备P/A机制使用普通的快速迁移机制,此时,可在华为设备上通过命令stp no-agreement-check设置P/A机制为普通的快速迁移机制,从而实现华为设备和其他厂商的设备进行互通。
DHCP
DHCP 三种地址分配方式
在这三种方式中,只有动态分配的方式可以对已经分配给主机但现在此主机已经不用的IP地址重新加以利用。这样,在给一台临时连入网络的主机分配地址或者在一组不需要永久的IP地址的主机中共享一组有限的IP地址时,动态分配就会显得特别有用。当一台新主机要永久的接入一个网络时,而网络的IP地址非常有限,为了将来这台主机被淘汰时能回。
自动分配
在自动分配中,不需要进行任何的IP地址手工分配。当DHCP客户机第一次向DHCP服务器租用到IP地址后,这个地址就永久地分配给了该DHCP客户机,而不会再分配给其他客户机。
动态分配
当DHCP客户机向DHCP服务器租用IP地址时,DHCP服务器只是暂时分配给客户机一个IP地址。只要租约到期,这个地址就会还给DHCP服务器,以供其他客户机使用。如果DHCP客户机仍需要一个IP地址来完成工作,则可以再要求另外一个IP地址。
手动分配
在手动分配中,网络管理员在DHCP服务器上通过手工方法配置DHCP客户机的IP地址。当DHCP客户机要求网络服务时,DHCP服务器把手工配置的IP地址传递给DHCP客户机。
DHCP报文类型(共8个类型)
- DHCP DISCOVER:由客户端广播来查找可用的服务器。
- DHCP OFFER:服务器用来响应客户端的DHCP DISCOVER报文,并指定相应的配置参数。
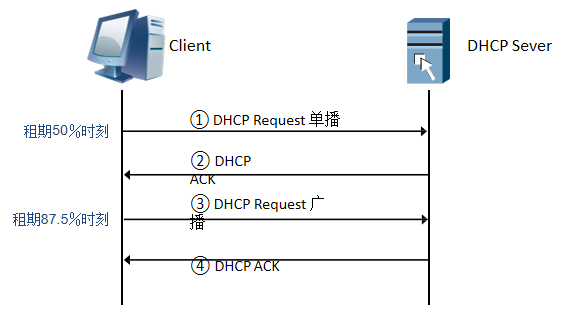
华为是单播,思科是广播 - DHCP REQUEST:由客户端发送给服务器来请求配置参数或者请求配置确认或者续借租期。使用场景如下:
- 正常的请求消息(华为是单播)
- 租约的期限到了50%(单播,进行续约)
- 租约的期限到了87.5%(广播,在50%的时候续约不成功,重新进行续约)
- PC重启之后需要重新续约
- DHCP ACK:由服务器到客户端,含有配置参数包括IP地址。
- DHCP DECLINE:当客户端发现地址已经被使用时,用来通知服务器。
- DHCP INFORM:客户端已经有IP地址时用它来向服务器请求其他的配置参数。
- DHCP NAK:由服务器发送给客户端来表明客户端的地址请求不正确或者租期已过期。
- DHCP RELEASE:客户端要释放地址时用来通知服务器。
PC>ipconfig /release # 释放IP地址;PC>ipconfig /renew # 重新获取IP
报文格式

DHCP报文中的option字段,采用“CLV”方式构成。DHCP的选项字段可以应用到多种不同的场景,比如无线等
- Code:标识号,唯一标识后面的信息内容,占1byte
- Length:长度,表示后面信息内容的长度,占1byte
- Value:信息内容,其长度为length所指定,以byte为单位
工作流程
全局配置
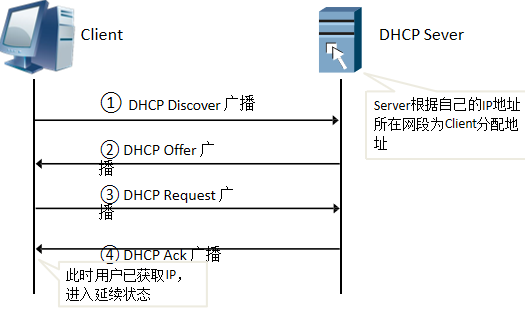
- 客户端发送DHCP Discover 广播报文即目的地址为255.255.255.255,在网络上寻找DHCP Server。
- 网络的的DHCP服务器响应客户端的请求,可能有多个DHCP Sever响应,以广播的方式进行。在网络中接收到DHCPdiscover发现信息的DHCP服务器都会做出响应,它从尚未出租的IP地址中挑选一个分配给DHCP客户机,向DHCP客户机发送一个包含出租的IP地址和其他设置的DHCPoffer信息。
- 客户端收到了DHCP Server的DHCP Offer报文之后,则向DHCP Server发送所需要的IP地址请求,该信息中包含向它所选定的DHCP服务器请求IP地址的内容。
- 因为有多个DHCP服务器,所以客户端是以广播方式发送DHCP Request报文,还因为要通知所有的DHCP服务器,他将选择某台DHCP服务器所提供的IP地址服务器收到请求之后,给客户端发送ACK响应报文。
- 以后DHCP客户端每次重新登录网络时,就不需要再发送DHCPdiscover发现信息了,而是直接发送包含前一次所分配的IP地址的DHCPrequest请求信息。
#......................全局配置
dhcp enable # 全局下开启dhcp
# 配置单臂路由
interface GigabitEthernet0/0/1.20
dot1q termination vid 20
ip address 192.168.20.1 255.255.255.0
arp broadcast enable
# 配置DHCP
dhcp select interface # 配置接口模式
dhcp server static-bind ip-address 192.168.20.200 mac-address 5489-98f9-5a19 # mac地址绑定
dhcp server excluded-ip-address 192.168.20.201 192.168.20.253 # IP地址池中排除相应IP
dhcp server lease unlimited #配置租借期为无限期
dhcp server dns-list 8.8.8.8 # 配置DNS服务器
dhcp server domain-name qyt # 配置域名
#..........................配置地址池
dhcp enable # 全局下开启dhcp
# 配置地址池
ip pool VLAN10
gateway-list 192.168.10.1 # 配置地址池必须配置网关
network 192.168.10.0 mask 255.255.255.0
static-bind ip-address 192.168.10.100 mac-address 5489-9874-0143
excluded-ip-address 192.168.10.201 192.168.10.254
dns-list 8.8.8.8
# 借口下开启
interface GigabitEthernet0/0/1.10
dot1q termination vid 10
ip address 192.168.10.1 255.255.255.0
arp broadcast enable
dhcp select global
# 查看地址池中已经使用的地址
dis ip pool name VLAN10 used
华为地址池分配顺序是从大到小,因此一般设置网关为x.x.x.254;思科地址池分配顺序为从小到大,因此一般设置网关为x.x.x.1
续租
中继
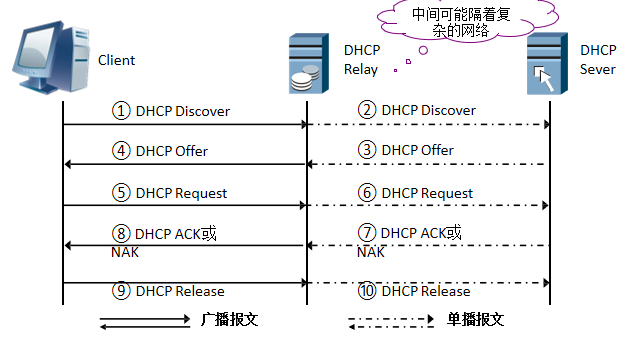
# 为实现DHCP服务器跨Vlan,则需要配置中继
interface GigabitEthernet0/0/1.10
dot1q termination vid 10
ip address 192.168.10.1 255.255.255.0
arp broadcast enable
dhcp select relay # 配置中继
dhcp relay server-ip 192.168.100.100 #配置中继的地址(此地址必须可以ping通)
# 中继也需要在相应接口下开启
dhcp select global
DHCP Snooping
原理
- DHCP Snooping是一种DHCP 安全特性,通过截获DHCP Client和DHCP Relay之间的DHCP报文并进行分析处理,可以过滤不信任的DHCP报文并建立和维护一个DHCP Snooping绑定表。
绑定表包括MAC地址、IP地址、租约时间、VLAN ID、接口信息。 - DHCP Snooping通过对这个绑定表的维护,建立一道在DHCP Client和DHCP Server之间的防火墙。
- DHCP Snooping可以解决设备应用DHCP时遇到的DHCP DoS(Denial of Service)攻击、DHCP Server仿冒攻击、DHCP仿冒续租报文攻击等问题。
关键技术
- 信任/非信任端口:一般通向DHCP服务器 (运营商网络内部)的端口设成“信任(Trusted)”,其它端口(连接运营商网络外部的端口) 都设为“不信任(Untrusted)” 。
- 绑定表:建立
MAC + IP + VLAN + Port的绑定关系。 - Option82:是DHCP协议报文中选项部分之中的一项,用于记录报文入端口类型、端口号、VLAN信息以及桥MAC地址,是生成绑定表的重要部分。
DHCP Snooping绑定表
分为动态绑定表和静态绑定表
- 静态绑定表
按照实际需求在报文入端口手工输入,没有租期限制
用途:一些重要设备(如服务器)和一些高端用户需采用静态方式,一是没有租期限制,二是安全性高且便 于管理。 - 动态绑定表
DHCP客户端在申请IP地址过程中,根据DHCP报文内容在报文入端口自动生成,存在老化时间,有租期限制。
用途:生成方便,常用于非重要设备。不过绑定表存在老化时间,且不便于管理。
# 全局下开启DHCP嗅探
dhcp snooping enable
# vlan下开启DHCP嗅探并添加信任端口
vlan 10
dhcp snooping enable
dhcp snooping trusted int g0/0/3
arp anti-attack check user-bind enable # 在vlan下开启动态arp检测
#在接口下配置该端口为DHCP信任端口
interface GigabitEthernet0/0/24
dhcp snooping trusted
arp anti-attack check user-bind enable # 在接口下开启动态arp检测
arp anti-attack check user-bind alarm enable
# 查看DHCP Snooping配置情况
dis dhcp snooping configuration
# 查看DHCP Snooping绑定表
dis dhcp snooping user-bind all
DHCP的Option82原理
使能Option82功能,可以根据Option82信息建立精确到接口的绑定表。
- DHCP Relay Agent插 入到用户的DHCP报 文,DHCP服务器通 过识别Option82来执 行IP地址分配策略或 其它策略。
- DHCP服务器的响应 报文也带Option82, Relay Agent将Option82剥离后发给用户。
- Agent Information Field中包括多个子选项,每个子选项格式为SubOpt/Length/Value三元组。
DHCP Option82工作流程
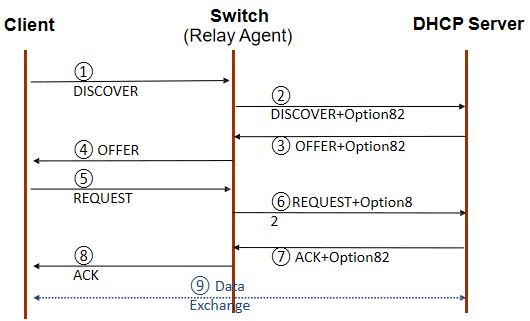
DHCP仿冒者攻击
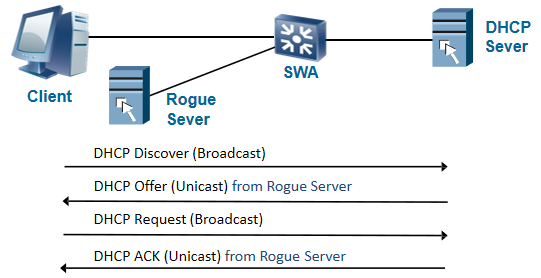
DHCP仿冒者攻击解决方法:一般把通向DHCP Server的接口(连接网络内部的网络侧接口)设成Trusted
状态,其它接口(连接网络外部的用户侧接口)都设为Untrusted状态。
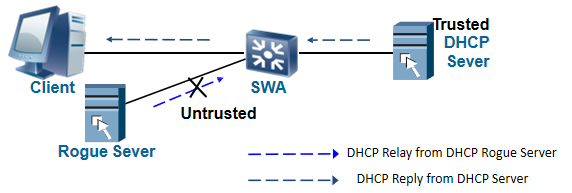
中间人攻击和IP/MAC Spoofing攻击
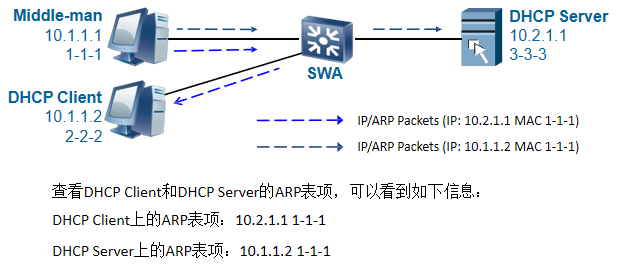
中间人攻击和IP/MAC Spoofing攻击解决方法:为了防止中间人攻击或IP/MAC Spoofing攻击,可以在交换机上配置DHCP Snooping功能,使能DHCP Snooping绑定表功能后,只有接收到的报文的信息和绑定表中的内容一致才会被转发,否则报文将被丢弃。
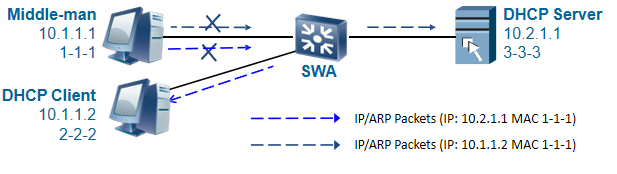
DAI(动态ARP检测)是用来检测arp报文的,是用来防止中间人攻击;IPSG(IP源防攻击)是用来检测IP报文的,用来防止盗用IP的
#-------------------------DAI
# 在vlan下开启动态arp检测
vlan 10
dhcp snooping enable
dhcp snooping trusted interface GigabitEthernet0/0/1
arp anti-attack check user-bind enable
# 在接口下开启动态arp检测
interface GigabitEthernet0/0/5
port link-type access
port default vlan 10
arp anti-attack check user-bind enable
arp anti-attack check user-bind alarm enable
#------------------------------
# 配置静态绑定表
user-bind static ip-address 192.168.10.100 mac-address 5489-9832-2464 inter
face g0/0/5 vlan 10
# 查看静态绑定表
dis dhcp static user-bind all
#------------------------------IPSG
# 在VLAN下开启IP源防护
vlan 10
ip source check user-bind enable
# 在接口下开启IP源防护功能
interface GigabitEthernet0/0/5
ip source check user-bind enable
ip source check user-bind alarm enable
# 查看IP源防护功能
[SW1]dis ip source check user-bind interface GigabitEthernet 0/0/5
ip source check user-bind enable
ip source check user-bind alarm enable
# ------------------------------开启端口安全
int g0/0/2
port-security enable
port-security max-mac-num 1 # 最多允许一个max
port-security protect-action shutdown # 触发之后关闭端口(protect丢弃;restrict丢弃后告警;shutdown关闭端口)
port-security mac-address sticky # 只允许这个mac地址(5489-982A-463D)通过
port-security mac-address sticky 5489-982A-463D vlan 10
饿死攻击
- 攻击原理:在饿死攻击方式中,攻击者不断变换物理地址,尝试申请地址池中所有的IP 地址,直到耗尽DHCP Server地址池中的地址,导致其他正常用户无法获得地址。
- 解决方案:通过MAC地址限制功能可以防止饿死攻击。通过限制交换机接口上允许学习到的最多MAC 地址数目,防止用户通过变换MAC地址,大量发送DHCP请求,同时也限制了一个接口上的用户数目。
改变CHADDR值的饿死攻击
- 攻击原理:在这种攻击方式中,如果攻击者改变的不是数据帧头部的源MAC,而是改变DHCP报文中的CHADDR(Client Hardware Address)值来不断申请IP地址,而交换机仅根据数据帧头部的源MAC来判断该报文是否合法,那么MAC地址限制方案不能起作用。
- 解决方案:可以使用DHCP Snooping检查DHCP REQUEST报文中CHADDR字段的功能。如果该字段跟数据帧头部的源MAC相匹配,便转发报文;否则,丢弃报文。
ARP攻击原理
- ARP攻击方式:有针对主机的,也有针对网关的;有地址欺骗型的, 也有野蛮攻击型的;有来自病毒的攻击,也有来自使用非法软件的人为攻击。
- ARP攻击根源:ARP协议本身过于简单和开放,没有任何的安全手段。
- ARP攻击危害:ARP地址欺骗攻击一般针对个别或一定范围内的主机 进行,危害相对较小。但针对网关设备的大流量ARP DDOS攻击,由 于其网络位置的特殊性,将造成大面积用户“掉线”。
- ARP攻击解决方法:
- 在应用DHCP服务器的组网环境下, 建立可信端口(trust Port),通过监控可信端口的DHCP 报文获得IP/MAC地址绑定表,这是DHCP Check IP/ARP安全检查手段的重要依据。实际上也是一种安全焦点的转移,把ARP安全问题转换为别的安全问题。
- DHCP Snooping Chek IP/ARP依据可信端口上生成的绑定表,过滤掉所有不匹配的IP/ARP报文。大大的提高了防攻击的能力。
iStack堆叠
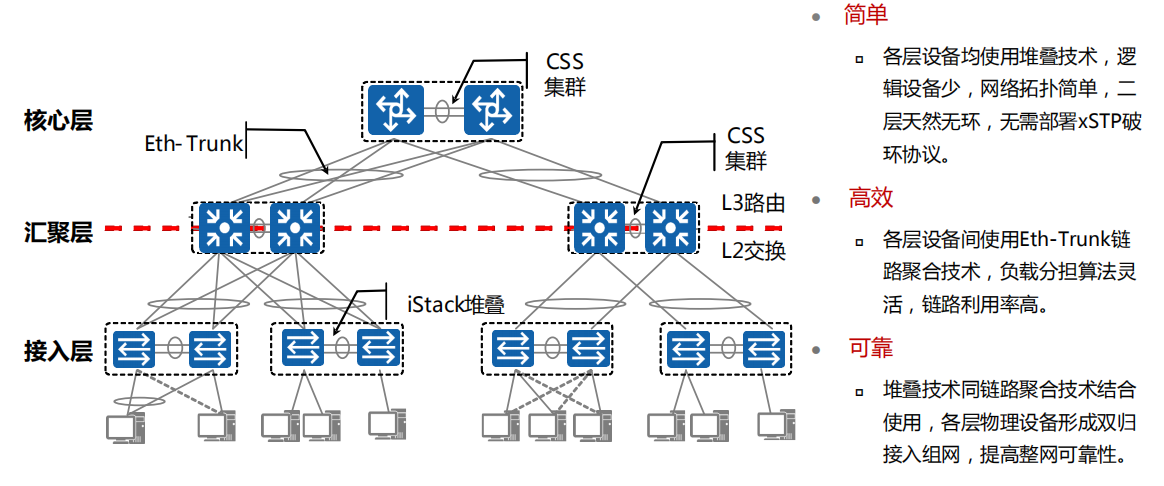
CSS和iStack的区别:CSS是框式堆叠,iStack是盒式堆叠
典型园区组网(CSS+Eth-Trunk+iStack)
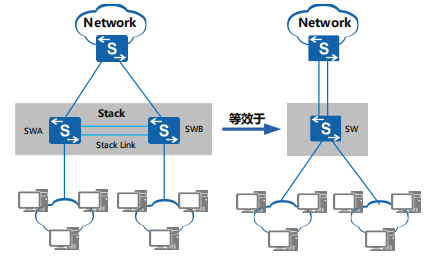
设备堆叠iStack
智能堆叠iStack是指将多台支持堆叠特性的交换机设备组合在一起,从逻辑上组合成一台交换设备。
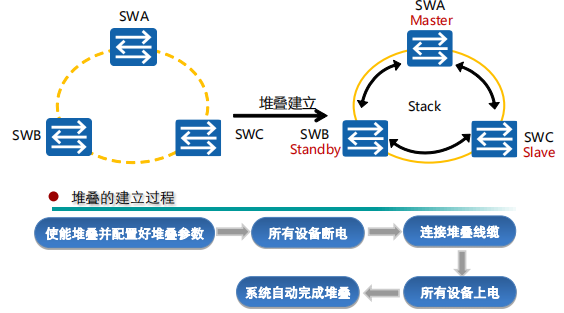
基本概念
角色
堆叠中所有的单台交换机都称为成员交换机,按照功能不同,可以分为三种角色:
- 主交换机(Master):负责管理整个堆叠。堆叠中只有一台主交换机。
不支持抢占 - 备交换机(Standby):是主交换机的备份交换机。当主交换机故障时,备交换机会接替原主交换机的所有业务。堆叠中只有一台备交换机。
- 从交换机(Slave):主要用于业务转发,从交换机数量越多,堆叠系统的转发能力越强。除主交换机和备交换机外,堆叠中其他所有的成员交换机都是从交换机。
堆叠ID
即成员交换机的槽位号(Slot ID),用来标识和管理成员交换机,堆叠中所有成员交换机的堆叠ID都是唯一的。
堆叠优先级
堆叠优先级是成员交换机的一个属性,主要用于角色选举过程中确定成员交换机的角色,优先级值越大表示
优先级越高,优先级越高当选为主交换机的可能性越大。
堆叠建立
堆叠连接方式
交换机组建堆叠根据堆叠口的不同,可以分为两种方式:堆叠卡堆叠和业务口堆叠
- 堆叠卡堆叠又分为以下两种情况:
- 交换机之间通过专用的堆叠插卡及专用的堆叠线缆连接
- 堆叠卡集成到了交换机后面板上,交换机通过集成的堆叠端口及专用的堆叠线缆连接
- 业务口堆叠指的是交换机之间通过与逻辑堆叠端口绑定的物理成员端口相连,不需要专
用的堆叠插卡
堆叠成员加入
堆叠成员加入是指向已经稳定运行的堆叠系统添加一台新的交换机。
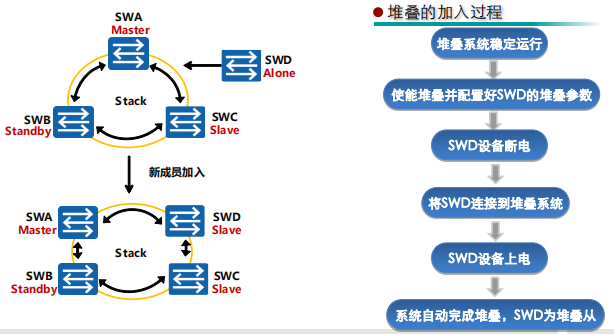
- 使能堆叠并配置好SWD的堆叠参数
- 如果是业务口堆叠,新加入的交换机需要配置无力程远端口加入逻辑堆叠端口。链型连接时,当前堆叠系统链型两端(或一端)的成员交换机也需要配置物理成员端口加入逻辑堆叠口。
- 如果是堆叠卡堆叠,新加入的成员交换机需要使能堆叠功能。
为了便于管理,建议新加入的交换机配置堆叠ID,如果不配置,堆叠系统会为其分配一个堆叠ID
- 讲SWD连接到堆叠系统
- 如果是链型连接,新加入的交换机建议添加到链型的两端,这样对现有的业务影响最小
- 如果是环型连接,需要把当前环型拆成链型,然后在链型的两端添加设备
- 系统完成堆叠
- 新加入的交换机连线上电启动后,进行角色选举,新加入的交换机会选举为从交换机,堆叠系统中原有的主备从角色不变
- 角色选举结束后,主交换机更新堆叠拓扑信息,同步到其他成员交换机上,并向新加入的交换机分配堆叠ID(在新成员未配置或配置冲突时)
- 新加入的交换机更新堆叠ID,并同步主交换机的配置文件和系统软件,之后进入稳定运行状态
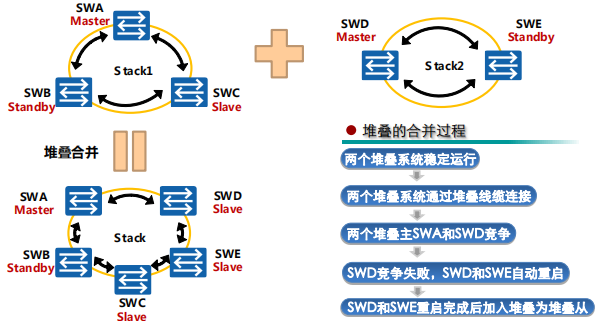
堆叠合并
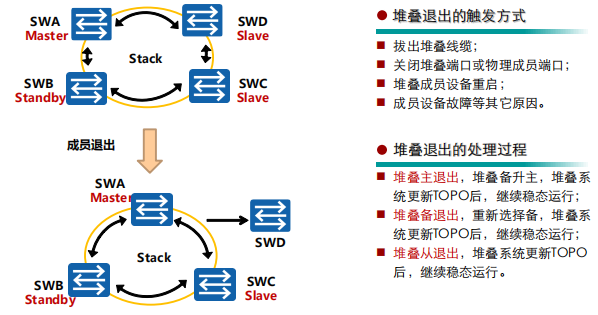
堆叠成员退出
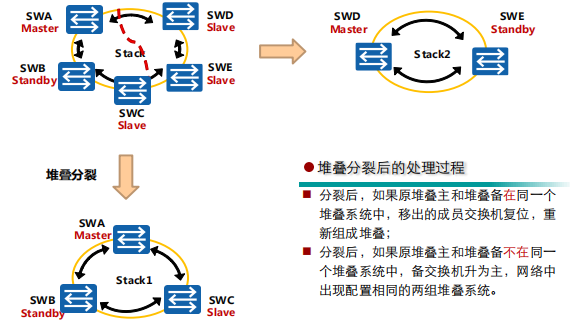
堆叠分裂
多主检测
直连检测方式
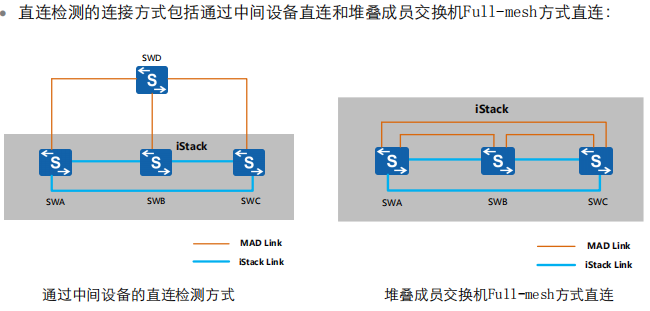
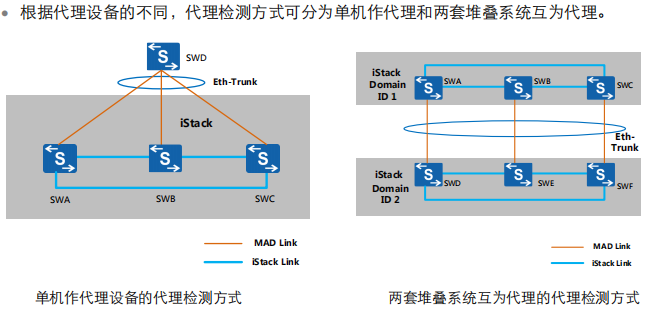
代理检测方式
连线方式
- 链型
- 环型
配置
通过堆叠卡连接方式组建堆叠
[SwitchA] stack slot 0 priority 200
\\配置成员交换机的堆叠优先级。缺省情况下,成员交换机的堆叠优先级为100
[SwitchB] stack slot 0 renumber 1
\\配置设备的堆叠ID
[SwitchC] stack slot 0 renumber 2
通过业务口连接方式组建堆叠
[SwitchA] interface stack-port 0/1
[SwitchA-stack-port0/1] port interface gigabitethernet 0/0/27 enable
\\配置业务口为物理成员端口并将其加入到逻辑堆叠端口中。交换机B、C同理。
[SwitchA] interface stack-port 0/2
[SwitchA-stack-port0/2] port interface gigabitethernet 0/0/28 enable
[SwitchA] stack slot 0 priority 200
\\ 配置SwitchA的堆叠优先级为200
[SwitchB] stack slot 0 renumber 1
\\配置SwitchB的堆叠ID为1
[SwitchC] stack slot 0 renumber 2
CSS堆叠
集群交换系统CSS,又称集群,是指将两台支持集群特性的交换机设备组合在一起,从逻辑上组合成以太交换设备。
特征
- 交换机多虚一:堆叠交换机对外表现为一台逻辑交换机,控制平面合一,统一管理
- 转发平面合一:堆叠内物理设备转发平面合一,转发信息共享并实时同步
- 跨设备链路聚合:跨堆叠内物理设备的链路被聚合成一个Eth-Trunk端口,和现有设备实现互联。
基本概念
- 主交换机:负责管理整个集群,集群中只有一台主交换机
- 备交换机:主交换机的备份交换机。当主交换机故障时,备交换机会接替原主交换机的所有业务,集群中只有一台备交换机
- 集群ID:即CSS ID,用来标识和管理成员交换机,交换机中成员交换机的集群ID是唯一的。
- 集群优先级:即Priority,是成员交换机的一个属性,主要用于角色选举过程中确定成员交换机的角色,优先级值越大表示优先级越高,优先级越高当选为主交换机的可能性越大。
集群建立
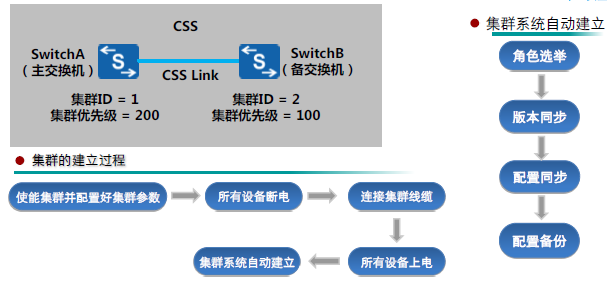
集群建立时,成员交换机间相互发送集群竞争报文,通过竞争,一台成为主交换机,负责管理整个集群系统,另外一台则成为备用交换机。
- 角色选举
- 运行状态比较,最先完成启动的交换机优先竞争为主交换机
- 堆叠优先级比较,堆叠优先级高的交换机优先竞争为主交换机
- 软件版本比较,软件版本高的交换机优先竞争为主交换机
- 主控板数量比较,有2块主控板的交换机比只有1块主控板的交换机优先竞争为主交换机
- 桥MAC地址比较,桥MAC地址小的交换机优先竞争为主交换机
- 版本同步
- 集群具有自动加载系统软件的功能,待组成集群的成员不需要具有相同的软件版本,只需要版本间兼容即可。
- 当主交换机选举结束后,如果备交换机与主交换机的软件版本不一致,备交换机会自动从主交换机下载系统软件,然后使用新的系统软件重启,并重新加入集群
- 配置同步
集群具有严格的配置文件同步机制,来保证集群中的多台交换机能够像一台设备一样在网络中工作。 - 配置备份
交换机从飞机群状态进入集群状态后,会自动将原有的非集群状态下的配置文件加上.bak的扩展名进行备份,以便关闭集群功能后,恢复原有配置。
CSS集群连接方式
设备组建集群有两种连接方式 ,分别为集群卡和业务口集群
- 集群卡方式:成员交换机之间通过主控板上专用的集群卡及专用的集群线缆连接。
- 业务口集群方式:成员交换机之间通过业务板上的普通业务口连接,不需要专用的集群卡。通iStack,业务口集群一样涉及两种端口的概念:物理成员端口和逻辑集群端口。
集群成员的加入与合并
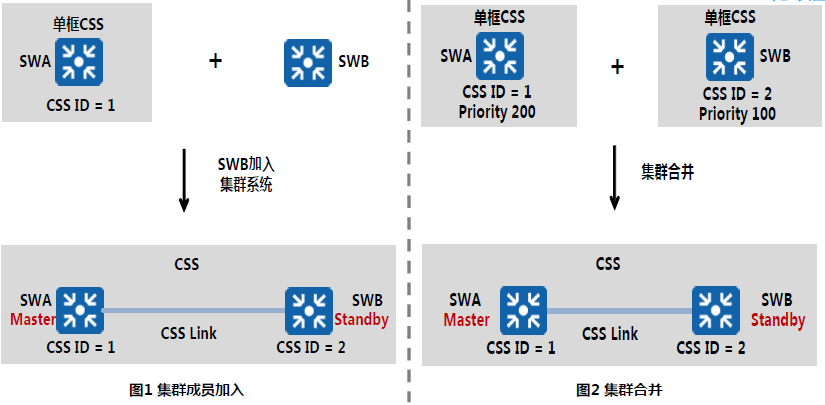
集群分裂
集群建立后,系统主用主控板和系统备用主控板定时发送心跳报文来维护集群系统的状态。集群线缆、
集群卡、主控板等发生故障或者是其中一台交换机下电或重启将导致两台交换机之间失去通信。当两
台交换机之间的心跳报文超时(超时时间为8秒)时,集群系统将分裂为两个单框集群系统,如图所 示:

集群分裂后,由于成员交换机运行着相同的配置文件,就会产生两个具有相同IP和MAC的集群系统。 为防止由此引起网络故障,必须进行IP地址和MAC地址的冲突检查。
集群升级
- 传统升级方式。传统的升级即通过指定启动文件后整机重启的方式进行升级。这种升级方式业务中断时间比较长,不适用于对业务中断时间要求较高的场景。
- 快速升级方式。堆叠快速升级提供了一种在堆叠系统的成员设备软件版本升级过程中尽量减少转发业务中断的机制,减少了升级设备对业务的影响。
- 升级前,堆叠与上下游设备之间使用Eth-Trunk双归连接方式。若不采用该连接方式,升级时流量中断时间会较长。
- 升级时,备交换机先以新版本重新启动,完成升级,此时数据流量由主交换机转发。
- 备交换机完成升级后,备交换机升级为主交换机,转发数据流量。原主交换机以新版本重新启动,完成升级后成为堆叠系统的备交换机。
- 升级结束,数据流量转发恢复正常。
# 模拟器不支持,需要使用真机配置
#CE1-A
lldp enable
stack
stack member 1 priority 200 # 配置槽位号(成员号)为1,优先级为200(默认为100)
stack member 1 domain 10
q
interface Stack-Port 1/1
port member-group interface 10GE 1/0/17 to 1/0/18
q
dis stack configuration
q
save
reboot
#CE1-B
lldp enable
stack
stack member 2 priority 120
stack member 2 domain 10
# stack member 2 rebunber 3 inherit-config # 修改槽位号并继承之前的配置
q
interface Stack-Port 1/1
port member-group interface 10GE 1/0/17 to 1/0/18
q
dis stack configuration
q
save
reboot
# 查看拓扑
dis stack topology
双向转发检测BFD
一个通用的标准化的介质无关和协议无关的快速故障检测机制,用于快速检测、监控网络中链路或者IP路由的转发连通状况。
应用场景
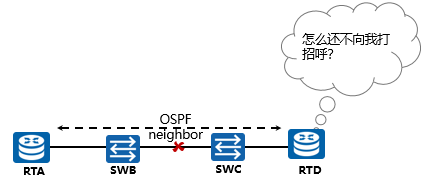
RTA和RTD建立了OSPF邻接关系,Hello包发送周期为10秒;当交换机SWB与SWC链路物理中断,路由器RTA和RTD无法感知,需要等待OSPF协议邻居失效计时器超时后才会中断邻接关系。(40秒之后才能感知到)
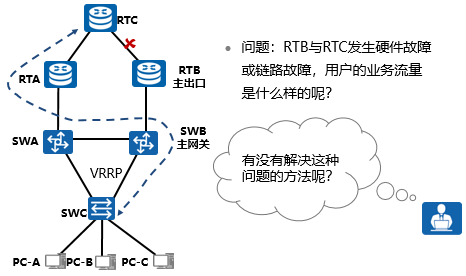
SWA和SWB启用了VRRP协议,实现了主备网关的作用,SWB为主用网关。当出口路由器RTB与外网Router的链路中断,SWB虽然可以通过动态路由协议感知,但是无法联动连接下游的网关接口,且继续为主网关。用户的数据流还是发送到SWB,SWB再通过三层路由转发给SWA,最后由RTA出口。虽然结果不至于造成业务中断,但是会产生次优路径。
简介
一种全网统一、检测迅速、监控网络中链路或者IP路由的双向转发连通状况,并为上层应用提供服务的技术。

BFD会话建立方式和检测机制
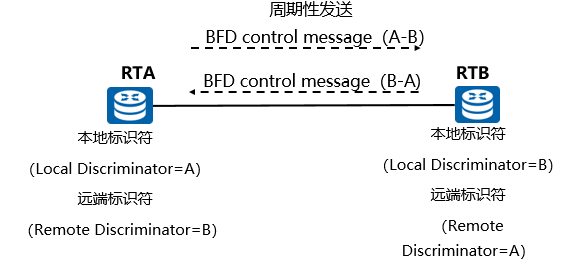
- BFD的标识符:
- BFD建立会话存在标识符的概念,类似于OSPF建立邻居需要一个路由器的Router ID。
- 标识符分为本地标识符和远端标识符,本地标识符用于表示本端设备,远端标识符用于表示对端设备。
- 静态建立BFD会话是指通过命令行手工配置BFD会话参数,包括配置本地标识符和远端标识符等,然后手工下发BFD会话建立请求。
- 动态建立BFD会话是指由应用程序触发创建BFD会话,当应用程序动态触发创建BFD会话时,系统分配属于动态会话标识符区域的值作为BFD会话的本地标识符。然后向对端发送Remote Discriminator的值为0的BFD控制报文,进行会话协商。当BFD会话的一端收到Remote Discriminator的值为0的BFD控制报文时,判断该报文是否与本地BFD会话匹配,如果匹配,则学习接收到的BFD报文中Local Discriminator的值,获取远端标识符。
- BFD的检测机制:
- BFD的检测机制是两个系统建立BFD会话,并沿它们之间的路径周期性发送BFD控制报文,如果一方在既定的时间内没有收到BFD控制报文,则认为路径上发生了故障,BFD控制报文是UDP报文,端口号3784。
- BFD提供异步检测模式。在这种模式下,系统之间相互周期性地发送BFD控制报文,如果某个系统连续3个报文都没有接收到,就认为此BFD会话的状态是Down。
BFD会话建立过程
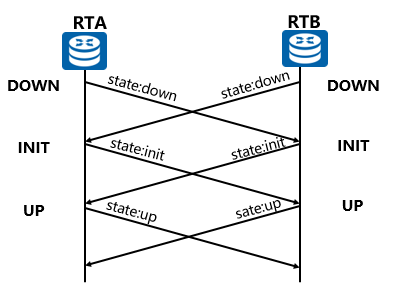
- RTA和RTB各自启动BFD状态机,初始状态为Down,发送状态为Down的BFD报文。对于静态配置BFD会话,报文中的Remote Discriminator的值是用户指定的;对于动态创建BFD会话,Remote Discriminator的值是0。
- RTB收到状态为Down的BFD报文后,状态切换至Init,并发送状态为Init的BFD报文。
- RTB本地BFD状态为Init后,不再处理接收到的状态为Down的报文。
- RTB收到状态为Init的BFD报文后,本地状态切换至Up。
- RTA的BFD状态变化同RTB。
- 邻居会话建立成功后,RTA和RTB周期性的向对方发送状态为Up的控制报文。
BFD工作流程
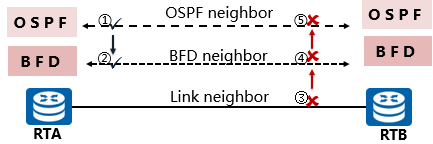
OSPF邻居建立-->BFD会话建立。
链路故障-->BFD会话Down-->OSPF邻居关系中断。
OSPF的BFD检测故障发现处理流程:
- OSPF通过自己的Hello机制发现邻居并建立连接。
- OSPF在建立了邻居关系后,将邻居信息(包括目的地址和源地址等)通告给BFD。
- BFD根据收到的邻居信息建立会话。
- 被检测链路出现故障。
- BFD快速发送BFD探测报文检测到链路故障,如果在规定时间内无响应,BFD会话状态变为Down。
- BFD通知本地OSPF进程BFD邻居不可达。
- 本地OSPF进程中断OSPF邻居关系。
联动功能
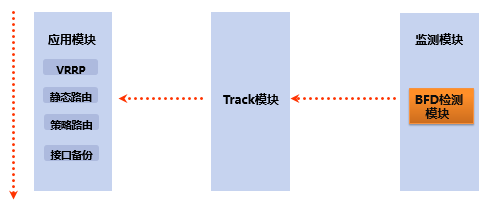
- 监测模块负责对链路状态、网络性能等进行监测,并将探测结果通知给Track模块 。
- Track模块收到监测模块的探测结果后,及时改变Track项的状态,并通知应用模块。
- 应用模块根据Track项的状态,进行相应的处理,从而实现联动。
镜像技术
在网络维护的过程中会遇到需要对报文进行获取和分析的情况,比如怀疑有攻击报文,此时需要在不影响报文转发的情况下,对报文进行获取和分析。
镜像技术可以在不影响报文正常处理流程的情况下,将镜像端口的报文复制一份到观察端口,用户利用数据监控设备来分析复制到观察端口的报文,进行网络监控和故障排除。
数据采集的作用
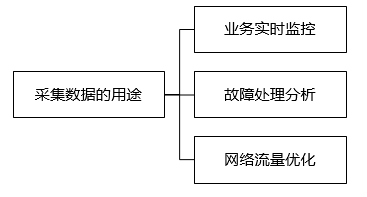
数据采集的方法
- 分光器物理采集
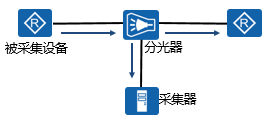
- 利用物理器件分光器插入连接的链路当中,复制出正常的数量流到采集器上面。
- 优点是采集的数据完整可靠,只在中间链路上操作,完全不影响被采集设备的性能,也不占用链路带宽。
- 缺点是每次采集要做物理动作切入,相对繁琐且有风险。
- 适合网络业务出入口大型设备的数据流采集,常用于连接IDS设备的网络环境。
- NMS集中采集
- 利用通用标准协议SNMP协议传送标准的MIB数据,采集整网的配置信息和设备端口数据流信息。
- 优点是可以采集整网设备节点信息。
- 缺点是针对接口的数据流信息采集不够精细和完整,大部分是统计信息。
- 适合网管中心查看设备的参数和性能以及业务信息统计。
镜像概述
- 镜像定义
将镜像端口(源端口)的报文复制一份到观察端口(目的端口)。 - 镜像作用
获取完整报文用于分析网络状况。 - 镜像优点
不影响原有网络,快捷方便。采集的是实时数据流,真实可靠。
镜像的角色
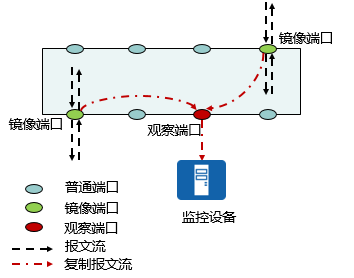
- 镜像端口:镜像端口是被监控的端口,从镜像端口流经的所有报文或匹配流分类规则的报文将被复制到观察端口。
- 观察端口:观察端口是连接监控设备的端口,用于输出从镜像端口复制过来的报文。
VXLAN
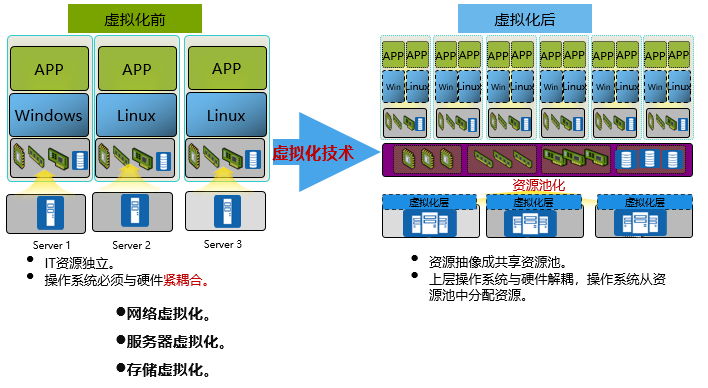
服务器虚拟化能够大幅降低IT建设运维成本,提高业务部署灵活性。虚拟机在传统数据中心网络中只能在二层网络中进行无缝迁移,一旦在跨三层网络中进行迁移,就会造成业务中断。于是VXLAN技术应运而生,大大提高了虚拟机迁移的灵活性,使海量租户不受网络IP地址变更和广播域限制的影响,同时也大大降低了网络管理的难度。
数据中心
概念
- 数据中心(Data Center)是一套完整、复杂的集合系统,它不仅包括计算机系统和其它与之配套的设备(例如通信和存储系统),还包含数据通信系统、环境控制设备、监控设备以及各种安全装置。
- 数据中心通常是指在一个物理空间内实现信息集中处理、存储、传输、交换、管理的场所。
- 服务器、网络设备、存储设备等通常都是数据中心的关键设备。
- 设备运行所需要的环境因素,如供电系统、制冷系统、机柜系统、消防系统、监控系统等通常都被认为是关键物理基础设施。
- 互联网数据中心(Internet Data Center,IDC)是互联网中数据存储和处理的中心,是互联网中数据交互最为集中的地方。
简而言之: - DC (Data Center)。
- 企业IT系统的核心。
- 海量数据运算、交换、存储的中心。
- 关键信息业务应用的计算环境。
- 集中管控各种数据、应用程序、物理或 虚拟化设备的环境。
- 数据中心四大焦点:可靠 、灵活 、绿色 、高效
传统数据中心网络结构
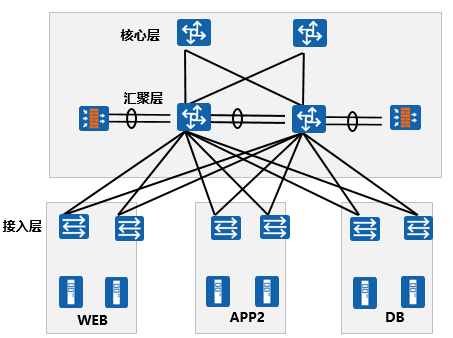
- 数据中心按不同业务功能进行分区。传统数据中心的网络结构是按照经典的三层架构(接入、汇聚、核心)进行部署的。
- 按照功能模块划分,传统数据中心可分为核心区、外网服务器区、内网服务器区、互联网服务器区、数据中心管理区、数据交换&测试服务器区、数据存储功能区、数据容灾功能区等。
- 在服务器区,再根据不同的应用类型划分不同的层次,例如,数据库层、应用服务器层、WEB服务器层等。
面对的挑战
- 计算节点低延迟需求
- 同一物理服务器部署大量虚拟机,造成流量并发量大增。
- 数据流量模型也从传统的南北向流量转变为东西向流量。
- 网络中存在大量多对一、多对多的东西向流量。
- 对接入层和汇聚层设备的处理能力提出了更高的要求。
- 虚拟化应用大量部署
- 传统的数据中心内,服务器主要用于对外提供服务,不同业务区域之间可通过划分为不同的安全分区或VLAN进行隔离。
- 一个分区通常集中了该业务所需的计算、网络及存储资源,不同的分区之间或者禁止互访,或者经由三层网络进行互访,数据中心的网络流量大部分集中于南北向。在这种设计下,不同分区间计算资源无法共享,资源利用率低下的问题越来越突出。
- 通过虚拟化技术、云计算管理技术等,将各个分区间的资源进行池化,实现数据中心资源的有效利用。
- 随着这些新技术的兴起和应用,新的业务需求如虚拟机迁移、数据同步、数据备份、协同计算等在数据中心内开始实现部署,数据中心内部东西向流量开始大幅度增加。
- 虚拟机动态迁移技术在实际应用中很常见,比如需要对一台服务器进行升级和维护时,可以通过VM迁移技术将这台服务器上的VM先迁移到另一台服务器上,其间所提供的服务不中断,然后等服务器升级和维护结束后再将VM迁移回来即可。
- 虚拟机动态迁移技术还可以充分利用计算资源,比如某公司的网购平台在某段时间内在某片区域提供促销活动,其间业务量大大增加,这样可以将其他业务量小的区域内的VM动态迁移过来,这样不会中断其他区域服务的情况下,集中利用资源,活动结束后再将VM调整回原先的区域。
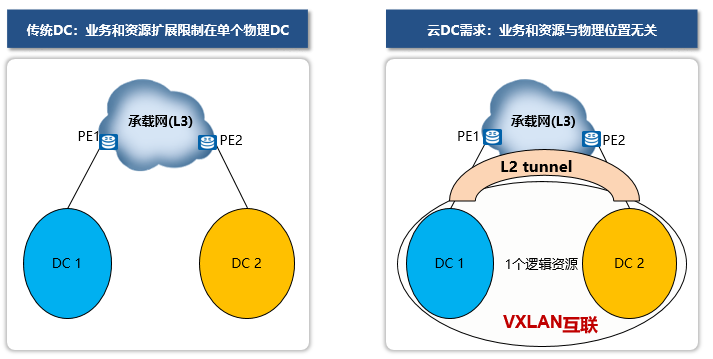
多数据中心大二层互联 - VXLAN
- 业务快速创新、自动发放需求
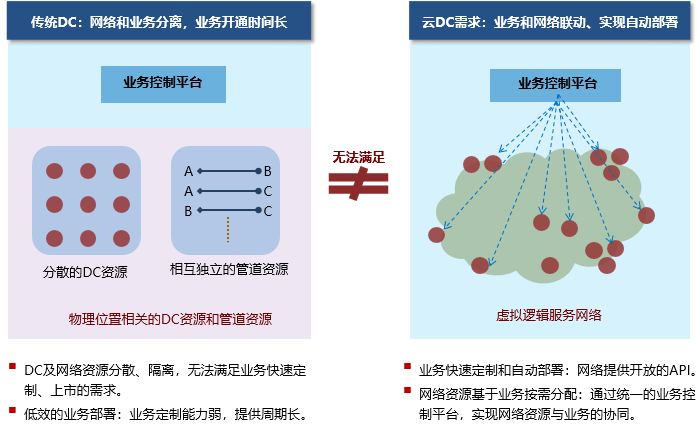
云数据中心的网络解决方案
传统三层网络架构下虚拟机动态迁移带来的问题
虚拟机迁移要求二层可达,变更虚拟机IP地址业务造成业务中断,而且相关的服务器也要进行相应的配置变更。
当前的一些解决方案:拓扑简化思想。通过CSS、istack技术简化拓扑,服务器处于扁平网络架构,VM在同一个二层网络中,迁移过程无需修改IP,服务不受影响,可无障碍灵活迁移。
该解决方案存在的问题:MAC地址数量陡增,接入设备压力较大;多租户隔离环境中设备VLAN资源紧张;二层网络范围过大,影响网络通信效率;传统解决方案较适用于DC内部大二层互联应用
VXLAN部署的典型网络架构
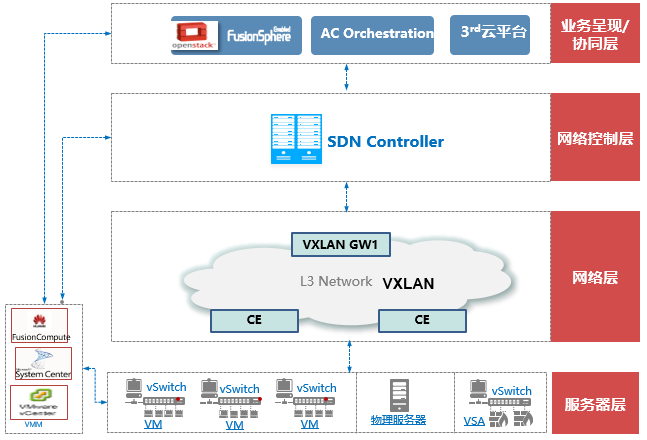
- VXLAN/NVGRE/STT是三种典型的NVO3技术。
- 是通过MAC In IP技术在IP网络之上构建逻辑二层网络。
- 同一租户的VM彼此可以二层通信、跨三层物理网络进行迁移。
- 相比传统L2 VPN等Overlay技术,NVO3的CE侧是虚拟或物理主机,而不是网络站点。
- 此外主机具有可移动性。
- 目前,一般是IT厂商主导,通过服务器的Hypervisor来构建Overlay网络。
VXLAN组网逻辑架构
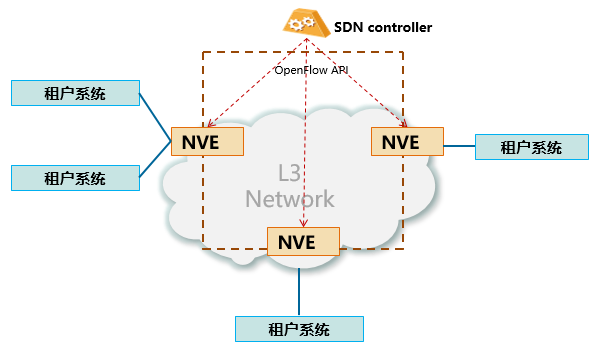
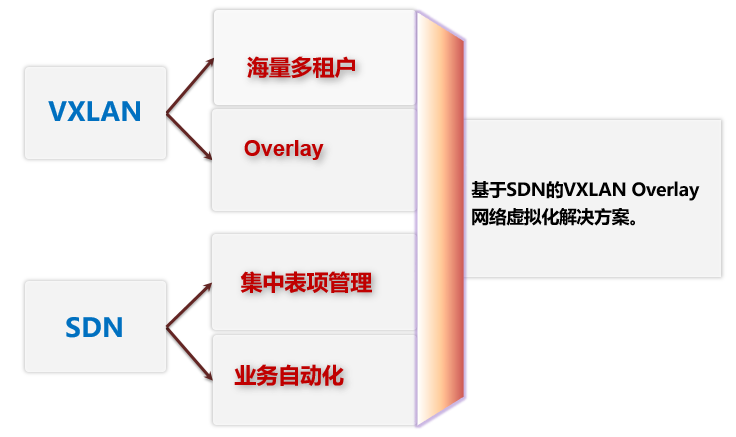
- VXLAN是IETF NVO3定义的NVO3标准技术之一,采用MAC in UDP封装方式,将二层报文用三层协议进行封装,可对二层网络在三层范围进行扩展,同时支持24bits的VNI ID(16M租户能力),满足数据中心大二层VM迁移和多租户的需求。
- 在VXLAN NVO3网络模型中,部署在VXLAN网络边缘的设备称为 VXLAN NVE(Network Virtualization Edge,网络虚拟边缘),主要负责VLAN网络与VXLAN网络间的封装和解封装。经过NVE封装转换后,NVE间就可基于L3基础网络建立Overlay二层虚拟化网络。
- VXLAN技术特点:
- 位置无关性:业务可在任意位置灵活部署,缓解了服务器虚拟化后相关的网络扩展问题。
- 可扩展性:在传统网络架构上规划新的Overlay网络,部署方便,同时避免了大二层的广播风暴问题,可扩展性极强。
- 部署简单:由高可靠SDN Controller完成控制面的配置和管理,避免了大规模的分布式部署,同时集中部署模式可加速网络和安全基础架构的配置,提高可扩展性。
- 适合云业务:可实现千万级别的租户间隔离,有力地支持了云业务的大规模部署。
- 技术优势:VXLAN利用了现有通用的UDP进行传输,成熟性极高。
VXLAN网关
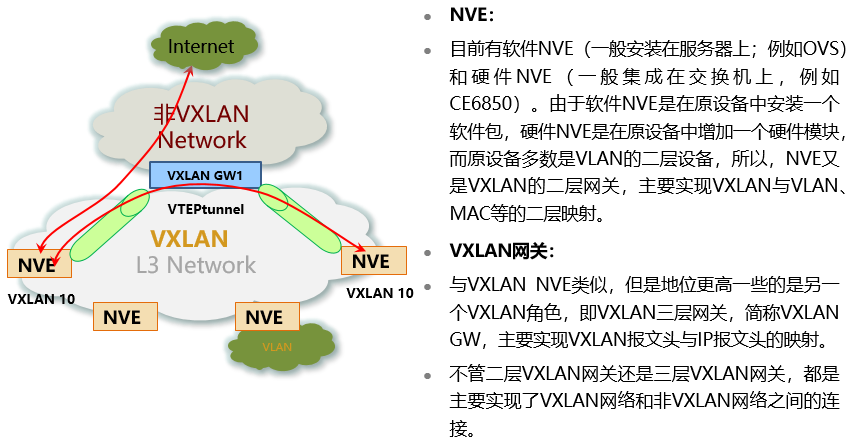
- NVE是服务器虚拟化层的一个功能模块,虚拟机通过虚拟化软件直接建立VTEP隧道。
- NVE也可以是一台支持VXLAN的接入交换机集中为多租户提供VXLAN网关服务。
- VXLAN网关可以实现不同VXLAN下租户间通信,也能实现VXLAN用户与非VXLAN用户间通信,这和VLANIF接口的功能是类似的。
VXLAN报文封装
- VXLAN是IETF定义的NVO3(Network Virtualization over Layer3)标准技术之一。
- 采用Mac in UDP封装方式将二层报文用三层协议进行封装。
- 支持24bits的VNI ID ,满足数据中心大二层VM迁移和多租户的需求。
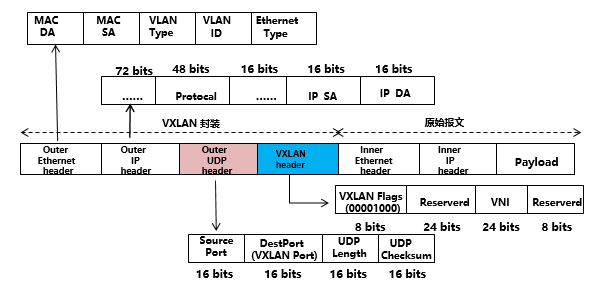
- VXLAN头封装:
- VNI:VXLAN网络标识,24比特,用于区分VXLAN段。
- Reserved:24比特和8比特,必须设置为0。
- 外层UDP头封装:
- 目的UDP端口号是4789。源端口号是内层以太报文头通过哈希算法计算后的值。
- 外层IP头封装:
- 源IP地址为发送报文的虚拟机所属VTEP的IP地址;目的IP地址是目的虚拟机所属VTEP的IP地址。
- 外层Ethernet头封装:
- SA:发送报文的虚拟机所属VTEP的MAC地址。
- DA:目的虚拟机所属VTEP上路由表中直连的下一跳MAC地址。
- VLAN Type:可选字段,当报文中携带VLAN Tag时,该字段取值为0x8100。
- Ethernet Type:以太报文类型,IP协议报文该字段取值为0x0800。
VXLAN数据封装过程
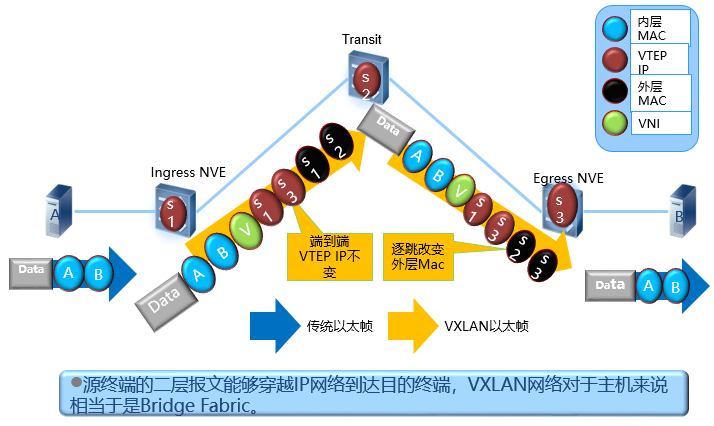
基于SDN的VXLAN基本组网
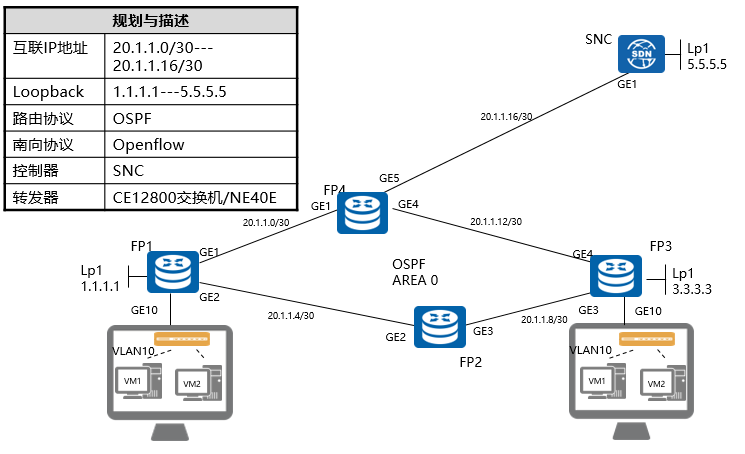
实验
实验一
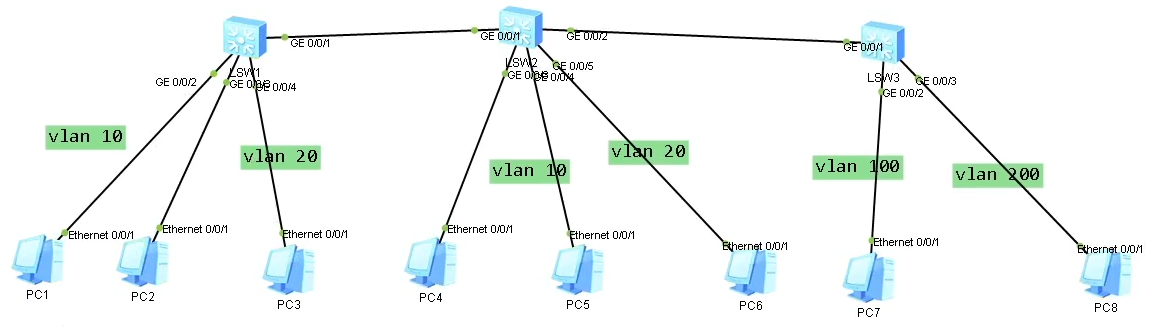
- pc1、pc2和pc4、pc5实现通信(VLAN10),pc3和pc6通信(VLAN20)
- pc7和pc4、pc5通信,但是不能和pc1和pc2通信
- pc8和pc6通信,但是不能和pc3通信
# sw1
sys
sys sw1
vlan batch 10 20 100 200
int g0/0/1
port link tr
port trunk allow vlan 10 20 100 200
port-group group-member g0/0/2 to g0/0/3
port link access
port default vlan 10
q
int g0/0/4
port link access
port default vlan 20
# sw2
sys
sys sw2
vlan batch 10 20 100 200
int g0/0/1
port hybrid tagged vlan 10 20 100 200
int g0/0/2
port hybrid tagged vlan 10 20 100 200
port-group group-member g0/0/3 to g0/0/4
port hybrid untagged vlan 10 100
port hybrid pvid vlan 10
q
int g0/0/5
port hybrid untagged vlan 20 200
port hybrid pvid vlan 20
# sw3
sys
sys sw3
vlan batch 10 20 100 200
int g0/0/1
port link tr
port trunk allow vlan 10 20 100 200
int g0/0/2
port hybrid untagged vlan 10 100
port hybrid pvid vlan 100
int g0/0/3
port hybrid untagged vlan 20 200
port hybrid pvid vlan 200
实验二:Mux Vlan
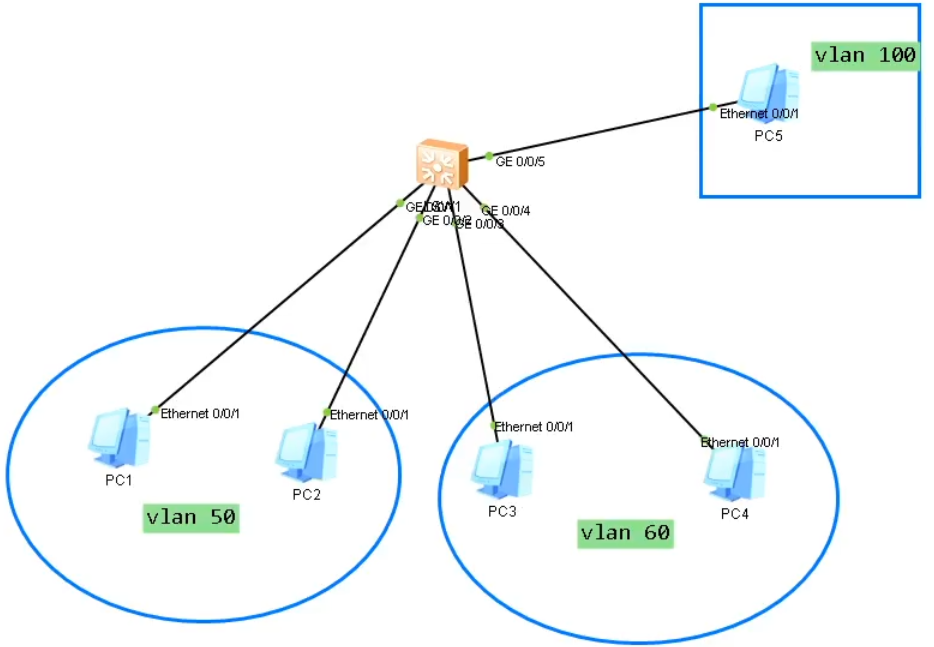
- vlan50内的主机可以相互通信
- vlan60内的主机不能相互通信
- vlan50和vlan60内的所有主机均可以访问vlan100中的pc5
# .............................配置Mux vlan
vlan batch 50 60 100 #创建vlan
vlan 100
mux-vlan # 配置主vlan
subordinate group 50 # 配置mux vlan 中的互通型从vlan
subordinate separate 60 # 配置mux vlan 中的隔离型从vlan
port-group group-member g0/0/1 to g0/0/2
port link access
port default vlan 50
port mux-vlan enable # 使能端口下的mux vlan功能:互通型从vlan
port-group group-member g0/0/3 to g0/0/4
port link access
port default vlan 60
port mux-vlan enable # 使能端口下的mux vlan功能:隔离型从vlan
int g0/0/5
port link access
port default vlan 100
port mux-vlan enable # 使能端口下的mux vlan功能:主vlan
实验三:Vlan聚合和端口隔离
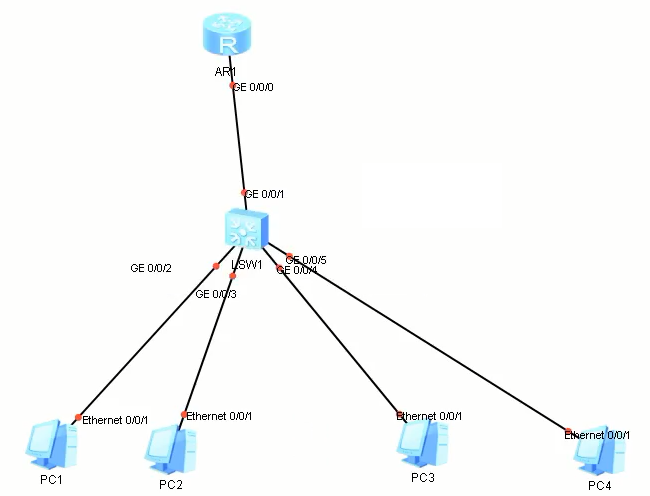
- Vlan聚合:所有vlan共享一个网段全网互通
- 端口隔离:pc1和PC2不能互访,PC3和pc4可以互访且可以访问PC1和PC2
#.............................Vlan聚合
# SW1
sys
sys SW1
vlan batch 10 20 100 200
port -group group-member g0/0/2 to g0/0/3
port link acc
port default vlan 10
port -group group-member g0/0/4 to g0/0/5
port link acc
port default vlan 20
q
vlan 100
aggregate-vlan # Super-VLAN由多个Sub-VLAN组成,不能加入物理端口,但可以创建VLANIF接口并配置IP地址
access-vlan 10 # 将多个Sub-VLAN批量加入到Super-VLAN中,必须保证这些Sub-VLAN没有创建对应的VLANIF接口
access-vlan 20
int vlan 100
ip add 10.10.10.1 24
arp-proxy inter-sub-vlan-proxy enable # 开启vlan间的arp代理
int vlan 200
ip addr 10.10.200.1 24
int g0/0/1
port default vlan 200
# AR1
sys
sys AR1
int g0/0/0
ip addr 10.10.200.254 24
q
ip route-static 10.10.10.0 24 10.10.200.1
ip route-static 10.10.20.0 24 10.10.200.1
int lo 0
ip addr 8.8.8.8 32
q
ip route-static 0.0.0.0 0 10.10.200.254
#.............................端口隔离
# SW1
sys
sys SW1
vlan batch 100
port -group group-member g0/0/2 to g0/0/5
port link acc
port default vlan 100
# 方法一:接口下配置
int g0/0/2
port-isolate enable
int g0/0/3
port-isolate enable
# 方法二:配置隔离端口组
port-isolate mode all # 全部隔离为all(即二层三层都隔离),二层隔离为l2
int g0/0/2
port-isolate enable group 1
int g0/0/3
port-isolate enable group 1
实验四:MSTP
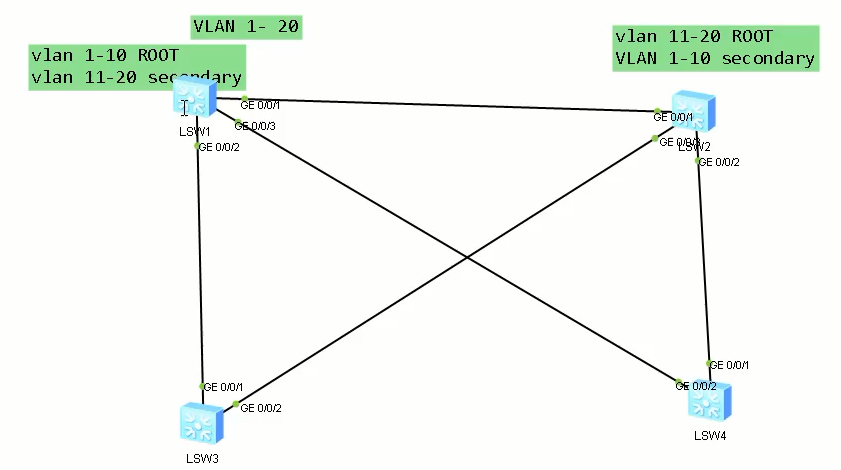
# SW1
sys
sys SW1
vlan batch 1 to 20
port-group gr g0/0/1 to g0/0/3
port link trunk
port tr allow all
stp region-configuration
region-name hcie
revision-level 10
instance 10 vlan 1 to 10
instance 11 vlan 11 to 20
active region-configuration
stp instance 10 root primary
stp instance 11 root secondary
# SW2
sys
sys SW2
vlan batch 1 to 20
port-group gr g0/0/1 to g0/0/3
port link trunk
port tr allow all
stp region-configuration
region-name hcie
revision-level 10
instance 10 vlan 1 to 10
instance 11 vlan 11 to 20
active region-configuration
stp instance 11 root primary
stp instance 10 root secondary
# SW3
sys
sys SW3
vlan batch 1 to 20
port-group gr g0/0/1 to g0/0/3
port link trunk
port tr allow all
stp region-configuration
region-name hcie
revision-level 10
instance 10 vlan 1 to 10
instance 11 vlan 11 to 20
active region-configuration
# SW4
sys
sys SW4
vlan batch 1 to 20
port-group gr g0/0/1 to g0/0/3
port link trunk
port tr allow all
stp region-configuration
region-name hcie
revision-level 10
instance 10 vlan 1 to 10
instance 11 vlan 11 to 20
active region-configuration
实验五:MSTP域
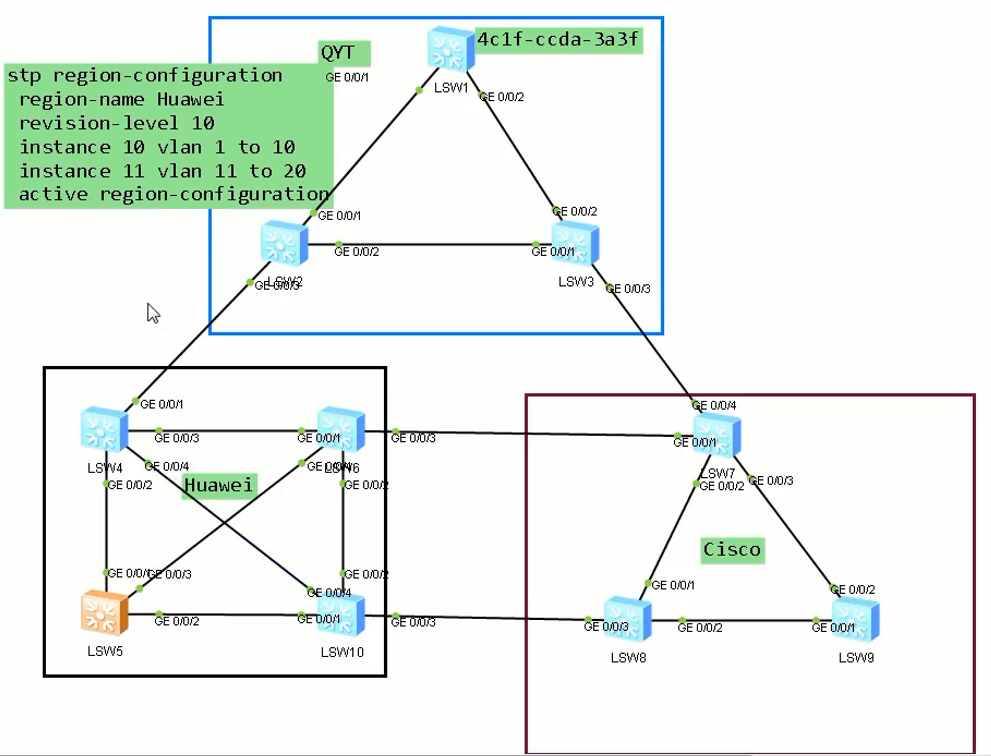
# SW1
sys
sys SW1
vlan batch 1 to 20
port-group group-member g0/0/1 to g0/0/4
port link trunk
port tr allow vlan all
stp root primary # 设置为总根
stp region-configuration
region-name qyt
revision-level 10
instance 10 vlan 1 to 10
instance 11 vlan 11 to 20
active region-configuration
# SW2
sys
sys SW2
vlan batch 1 to 20
port-group group-member g0/0/1 to g0/0/4
port link trunk
port tr allow vlan all
stp region-configuration
region-name qyt
revision-level 10
instance 10 vlan 1 to 10
instance 11 vlan 11 to 20
active region-configuration
# SW3
sys
sys SW3
vlan batch 1 to 20
port-group group-member g0/0/1 to g0/0/4
port link trunk
port tr allow vlan all
stp region-configuration
region-name qyt
revision-level 10
instance 10 vlan 1 to 10
instance 11 vlan 11 to 20
active region-configuration
# ---------------------------
# SW4
sys
sys SW4
vlan batch 1 to 20
port-group group-member g0/0/1 to g0/0/4
port link trunk
port tr allow vlan all
stp region-configuration
region-name huawei
revision-level 10
instance 10 vlan 1 to 10
instance 11 vlan 11 to 20
active region-configuration
stp instance 10 root primary
stp instance 11 root secondary
# SW5
sys
sys SW5
vlan batch 1 to 20
port-group group-member g0/0/1 to g0/0/4
port link trunk
port tr allow vlan all
stp region-configuration
region-name huawei
revision-level 10
instance 10 vlan 1 to 10
instance 11 vlan 11 to 20
active region-configuration
# SW6
sys
sys SW6
vlan batch 1 to 20
port-group group-member g0/0/1 to g0/0/4
port link trunk
port tr allow vlan all
stp region-configuration
region-name huawei
revision-level 10
instance 10 vlan 1 to 10
instance 11 vlan 11 to 20
active region-configuration
stp instance 11 root primary
stp instance 10 root secondary
# SW10
sys
sys SW10
vlan batch 1 to 20
port-group group-member g0/0/1 to g0/0/4
port link trunk
port tr allow vlan all
stp region-configuration
region-name huawei
revision-level 10
instance 10 vlan 1 to 10
instance 11 vlan 11 to 20
active region-configuration
# ------------------------------
# SW7
sys
sys SW7
vlan batch 1 to 20
port-group group-member g0/0/1 to g0/0/4
port link trunk
port tr allow vlan all
stp region-configuration
region-name cisco
revision-level 10
instance 10 vlan 1 to 10
instance 11 vlan 11 to 20
active region-configuration
# SW8
sys
sys SW8
vlan batch 1 to 20
port-group group-member g0/0/1 to g0/0/4
port link trunk
port tr allow vlan all
stp region-configuration
region-name cisco
revision-level 10
instance 10 vlan 1 to 10
instance 11 vlan 11 to 20
active region-configuration
# SW9
sys
sys SW9
vlan batch 1 to 20
port-group group-member g0/0/1 to g0/0/4
port link trunk
port tr allow vlan all
stp region-configuration
region-name cisco
revision-level 10
instance 10 vlan 1 to 10
instance 11 vlan 11 to 20
active region-configuration
实验六:BFD
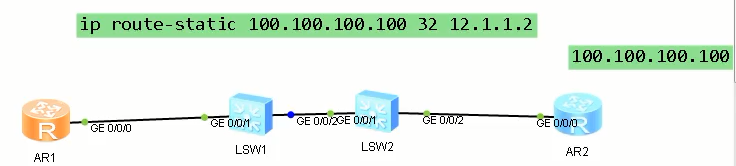
# BFD和静态联动
# AR1
bfd
bfd qyt bind peer-ip 12.1.1.2 interface GigabitEthernet0/0/0 source-ip 12.1.1.1 auto
commit
ip route-static 100.100.100.100 255.255.255.255 12.1.1.2 track bfd-session qyt
# AR2
bfd
bfd qyt bind peer-ip 12.1.1.1 interface GigabitEthernet0/0/0 source-ip 12.1.1.2 auto
commit
# BFD的单臂回声
# 即单向检测,应用于一端设备不支持BFD的情况下
# AR1
bfd
bfd qyt bind peer-ip 12.1.1.2 interface GigabitEthernet0/0/0 source-ip 12.1.1.1 one-arm-echo
discriminator local 1
commit
ip route-static 100.100.100.100 255.255.255.255 12.1.1.2 track bfd-session qyt
# BFD和OSPF联动
# AR1
bfd
q
ospf 10 router-id 1.1.1.1
bfd all-interfaces enable
# AR2
bfd
q
ospf 10 router-id 2.2.2.2
bfd all-interfaces enable
# BFD和BGP联动
# AR1
bfd
q
bgp 100
router-id 1.1.1.1
peer 2.2.2.2 as-number 100
peer 2.2.2.2 connect-interface lo 0
peer 2.2.2.2 bfd enable
# AR2
bfd
q
bgp 100
router-id 2.2.2.2
peer 1.1.1.1 as-number 100
peer 1.1.1.1 connect-interface lo 0
peer 1.1.1.1 bfd enable
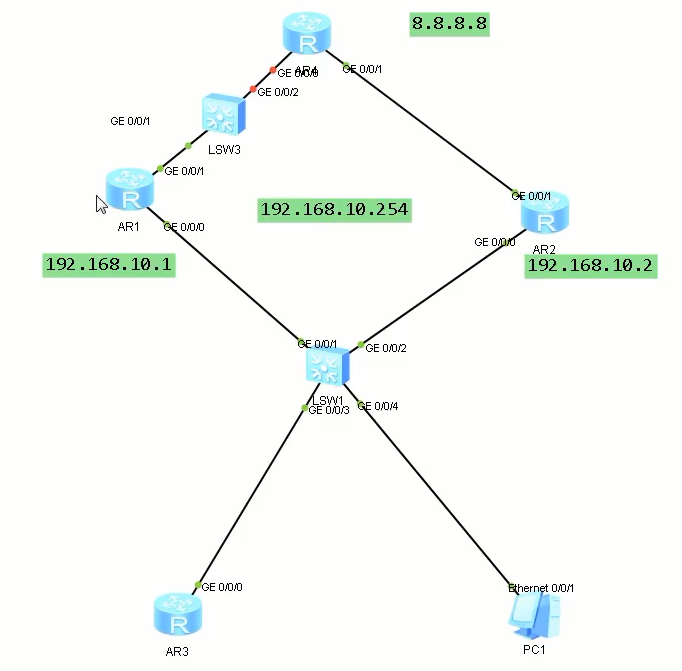
# BFD和VRRP联动
# 接口断掉之后优先级减30
# AR1
sys
sys AR1
int g0/0/1
ip addr 14.1.1.1 24
int g0/0/0
ip addr 192.168.10.1 24
vrrp vrid 10 virtual-ip 192.168.10.254
vrrp vrid 10 priority 120
vrrp vrid 10 preempt-mode timer delay 10
ospf 10 router 1.1.1.1
area 0
network 192.168.10.1 0
network 14.1.1.1 0
q
silent-interface g0/0/0
bfd qyt bind peer-ip 14.1.1.4 interface GigabitEthernet0/0/1 source-ip 14.1.1.1 auto
q
int g0/0/0
vrrp vrid 10 track bfd-session session-name qyt reduced 30
# AR2
sys
sys AR2
int g0/0/1
ip addr 24.1.1.2 24
int g0/0/0
ip addr 192.168.10.2 24
vrrp vrid 10 virtual-ip 192.168.10.254
vrrp vrid 10 preempt-mode timer delay 10
ospf 10 router 2.2.2.2
area 0
network 192.168.10.2 0
network 24.1.1.2 0
q
silent-interface g0/0/0
# AR4
int g0/0/0
ip addr 14.1.1.4 24
int g0/0/1
ip addr 24.1.1.4 24
int lo 0
ip addr 8.8.8.8 32
ospf 10 router 4.4.4.4
area 0
network 8.8.8.8
network 24.1.1.4 0
network 14.1.1.4 0
bfd qyt bind peer-ip 14.1.1.1 interface GigabitEthernet0/0/0 source-ip 14.1.1.4 auto
实验七:端口镜像
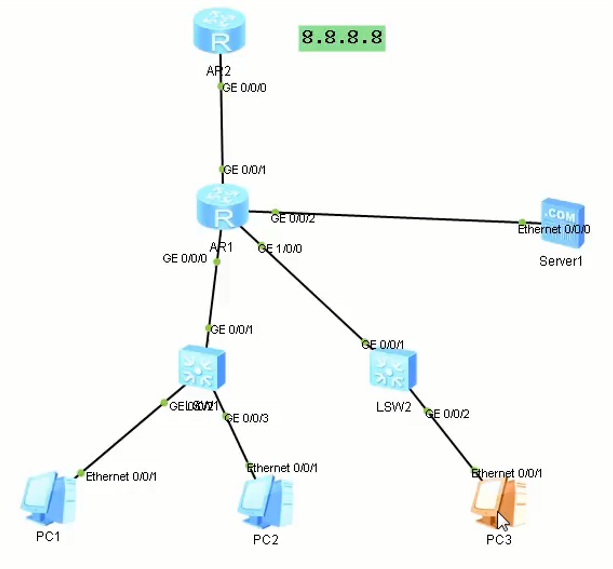
# 初始化呢配置
# AR1
sys
sys AR1
int g0/0/0
ip addr 192.168.10.1 24
int g0/0/1
ip addr 12.1.1.1 24
int g0/0/2
ip addr 192.168.30.1 24
int g1/0/0
ip addr 192.168.20.1 24
ospf 10 route 1.1.1.1
a 0
network 192.168.0.0 0.0.255.255
q
silent-interface g0/0/0
silent-interface g1/0/0
silent-interface g0/0/2
# SW1/2
stp disable
# AR2
sys
sys AR2
int g0/0/0
ip addr 12.1.1.2 24
int lo 0
ip addr 8.8.8.8 32
ospf 10 route 2.2.2.2
a 0
network 8.8.8.8 0
# 镜像端口配置
# 将AR1的g0/0/0为镜像端口,g0/0/2为观察端口
# AR1
observe-port int g0/0/2 # 首先需要配置观察端口
# 跨路由器或交换机配置观察端口:observe-server destination-ip 2.2.2.2 source-ip 1.1.1.1
######## 监控g0/0/0上的全部流量
int g0/0/0 # 配置镜像端口
mirror to observe-port both # [both/inbound/outbound]
######## 针对特定流量监控,只监控PC1的流量
acl 2001
rule permit source 192.168.10.10 0
q
traffic classifier C1
if-match acl 2001
q
traffic behavior B1
mirror to observe-port
q
traffic policy P1
classifier C1 behavior B1
int g0/0/0
traffic-policy P1 inbound